连夺4项第一!AI常识推理和人类又近了3%
![]()
新智元报道

新智元报道
编辑:好困 桃子
【新智元导读】让机器像人一样思考又迈进了一步?
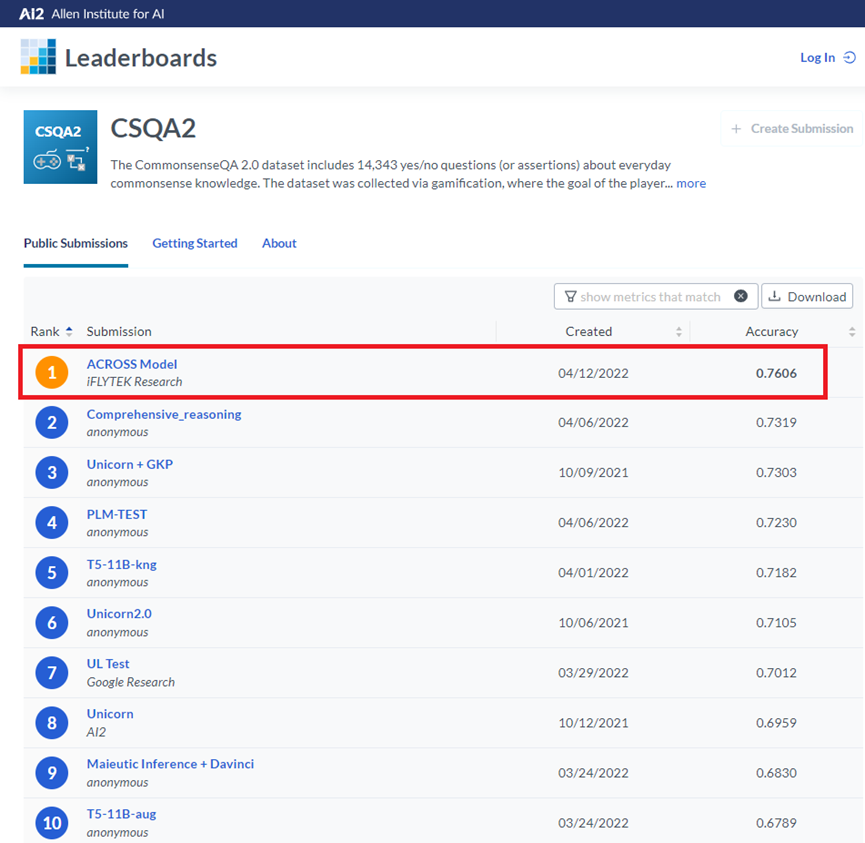
刷新常识推理世界纪录


多语种语言理解三连冠
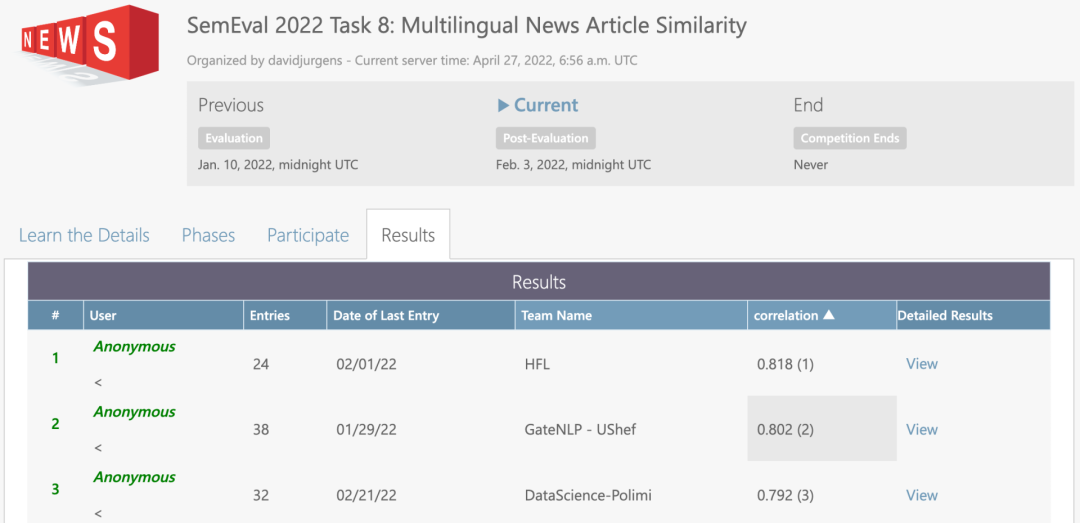
新闻相似度评价

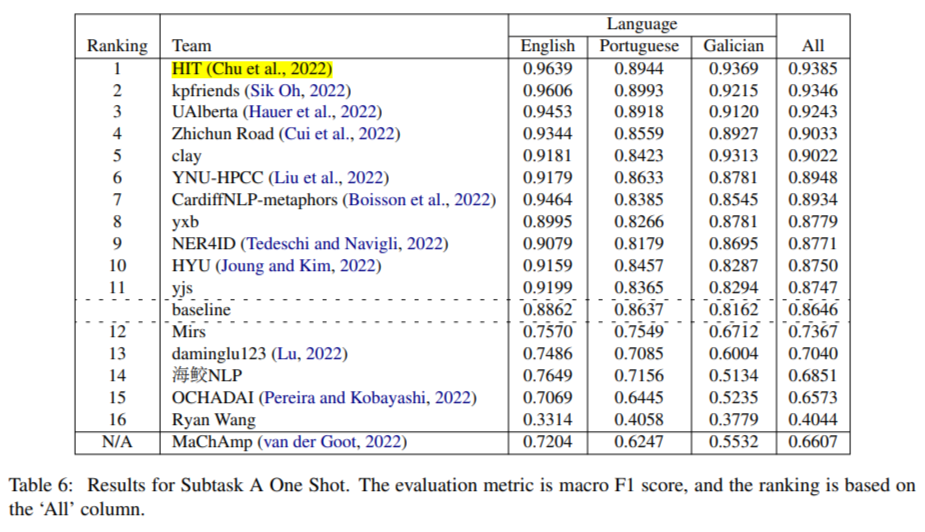
惯用语识别

复杂命名实体识别

用上了吗?
用上了吗?


下一站,去哪?
下一站,去哪?

登录查看更多
相关内容
专知会员服务
26+阅读 · 2022年3月1日
专知会员服务
37+阅读 · 2020年4月10日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
Arxiv
0+阅读 · 2022年6月21日
Arxiv
27+阅读 · 2021年1月21日



相关VIP内容
专知会员服务
26+阅读 · 2022年3月1日
专知会员服务
37+阅读 · 2020年4月10日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年6月21日
Arxiv
27+阅读 · 2021年1月21日