

将先前的知识纳入预训练的语言模型已被证明对知识驱动的NLP任务是有效的,如实体类型和关系提取。目前的预训练程序通常通过使用知识屏蔽、知识融合和知识替换将外部知识注入模型。然而,输入句子中包含的事实信息并没有被充分挖掘出来,注入的外部知识也没有被严格检查。因此,上下文信息不能得到充分的利用,额外的噪音会被引入,或者注入的知识量有限。为了解决这些问题,提出了MLRIP,它修改了ERNIEBaidu提出的知识屏蔽策略,并引入了一个两阶段的实体替换策略。广泛的实验与综合分析表明,在军事知识驱动的NLP任务中,MLRIP比基于BERT的模型更有优势。
引言
以无监督或弱监督的目标,如掩蔽语言模型(MLM),在大规模异质文本的语料库上预训练语言表示模型,可以使下游的自然语言处理(NLP)任务受益,如命名实体识别(NER),关系提取(RE)和实体类型。ELMo(Peters等人,2018)、OpenAI GPT(Radford等人,2018)和BERT(Devlin等人,2018)在大规模语料库上进行了训练,并被广泛用于开放领域的NLP任务,这些任务极大地促进了下游性能甚至获得最先进的性能(SOTA)。对于特定领域,人们提出了许多特定领域的语言表示模型,如BioBERT(Symeonidou等人,2019)、FinBERT(Araci,2019)、SciBERT(Beltagy等人,2019)和PatentBERT(Lee和Hsiang,2020),它们在各种特定领域的NLP任务中取得了SOTA性能。尽管这些预训练的模型在实证研究中获得了巨大的成功,但最新的研究表明,采用弱监督方式的努力(Xiong等人,2019,He等人,2019,Bosselut等人,2019)优于采用无监督方式的。
最近,许多研究人员致力于使用各种策略将外部知识,无论是KG、注释,还是非结构化文本,纳入语言表示模型,如ERINEBaidu(Sun等人,2019)、ERINE-Tsinghua(Zhang等人,2019)、K-ADAPTER(Wang等人,2020)等,并在下游NLP任务上建立新的SOTA。因此,向语言表征模型注入知识已经成为NLP的主流。
然而,这些有前景的模型不能直接用于军事领域,原因如下:(1)ELMo、OpenAI GPT、BERT、XLNet(Yang等人,2019)和ERNIE-Baidu等语境化词汇表示法主要在一般语料库(Wikipedia和BookCorpus)上训练和测试,很难估计它们在军事文本挖掘上的表现。(2)军事文本中使用的语言和词汇与一般文本有很大不同,因此一般语料和军事语料的词汇分布有很大不同,这对军事文本挖掘来说往往是一个问题。(3)预训练任务是针对一般文本中的语料和实体特征设计的,不适合军事文本挖掘,应相应开发特定领域的预训练任务。(4)一般文本中不包含特定领域的特征,如多种表示方式、语义模糊、不同文本之间字面意义差异大等。
此外,现有的预训练模型绝大多数是通过使用掩蔽语言模型(Devlin等,2018,Liu等,2019)或知识掩蔽(Sun等,2019,Joshi等,2020,Cui等,2021)策略与注意机制来学习单词表征,或者通过向模型注入外部知识(Xiong等,2019,He等,2019,Liu等,2021)。但是,使用这些方法有一定的局限性:(1)遮蔽语言模型只能对低层次的语义知识进行建模(Sun等,2019);(2)知识遮蔽策略将更多的词汇、句法和语义信息建模到预训练模型中,但没有充分利用输入句子中包含的事实信息,这一点已在图2中说明;(3)知识增强方法忽略了知识源中存在的问题,例如,知识可能是错误的,有些知识没有包含等情况。在本论文中,提出了一个名为MLRIP的模型。遵循Sun等人(2019)提出的知识屏蔽策略,但对这些策略进行了修改,明确加入了输入句子中包含的先验事实知识来帮助预测屏蔽单元,同时还加入了关系级屏蔽方法来增强先验知识的表示。此外,提出了一个两阶段的实体替换策略,将更多的特定领域的知识纳入表示模型。首先,应用同实体提及来替换原点提及,这使得MLRIP能够学习实体提及知识,同时,为实体提及替换引入了一个负样本策略。在此基础上,使用基于事实的替换策略将特定领域的先验知识注入模型中。
为了评估提出的模型MLRIP性能,首先构建了一组基准数据集进行比较,然后对两个知识驱动的NLP任务,即实体类型和关系分类进行了实验。实验结果表明,MLRIP通过充分利用句子中的词法、句法和事实知识信息,以及来自特定领域知识库的知识,明显优于BERT和ERNIE-百度。还评估了MLRIP在军事NER上的表现,MLRIP仍然取得了相当的结果。此外,对所有的策略进行了消减研究,相应的实验表明,提出的策略实现了改进,并使下游的任务相应受益。
总而言之,贡献如下:
-
提出了一个名为MLRIP的军事文本挖掘模型,并引入了一种新的知识屏蔽策略来训练语言表示模型,同时,还引入了一种新的知识整合方法来将军事领域的特定知识注入语言表示模型。
-
提出的模型大大促进了知识驱动的军事NLP下游任务的性能,如实体类型和关系提取。
-
构建了各种军事文本挖掘的基准数据集。
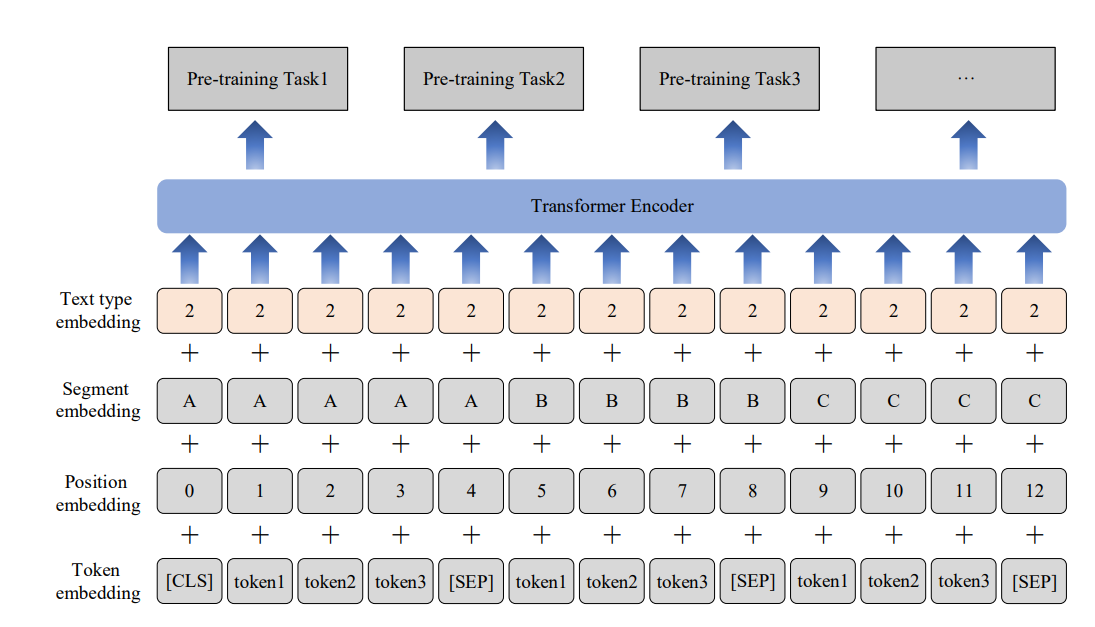
图1:MLRIP模型的结构。输入嵌入包含标记嵌入、片段嵌入、位置嵌入和文本类型嵌入。可以根据这个结构进行各种预训练任务。


