EMNLP 2022 | 校准预训练模型中的事实知识

©PaperWeekly 原创 · 作者 | werge
研究方向 | 自然语言处理

论文标题:
Calibrating Factual Knowledge in Pretrained Language Models
EMNLP 2022
https://arxiv.org/abs/2210.03329
https://github.com/dqxiu/CaliNet

Overview
近年来,预训练语言模型(PLMs)在多个 NLP 任务上都取得了较好的表现。研究表明 [1] PLMs 可以作为知识库存储事实知识,并帮助提升知识密集型的下游任务,如 QA 等。然而,其存储的事实知识存在一定比例的错误 [2] ,阻碍了下游任务表现。这便引入了一个问题:如何在 PLMs 中直接校准事实知识,而不需要重新训练?在本文中,作者提出了一个任务无关的的轻量级方法 CALINET 来实现这一目标。
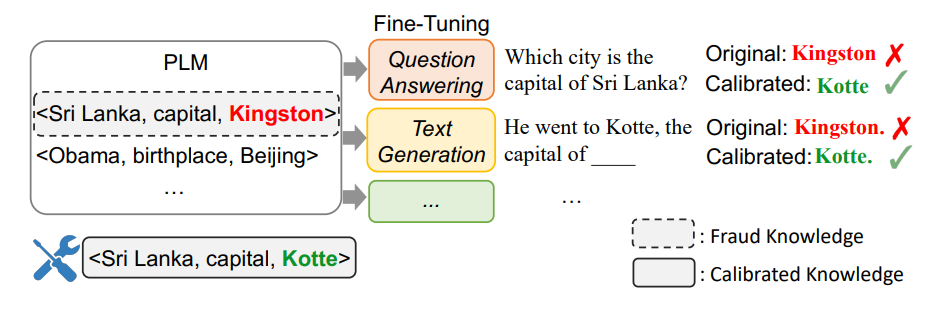
CALINET
对知识进行校准。本文的主要贡献如下:
CALINET
对错误事实进行校准,在不引入大量额外参数的前提下,该方法可以有效地校正错误事实,并展现了显著的泛化能力。

Methods
2.1 Contrastive Knowledge Assessment
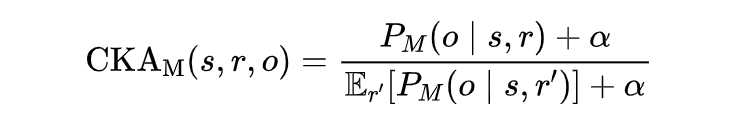

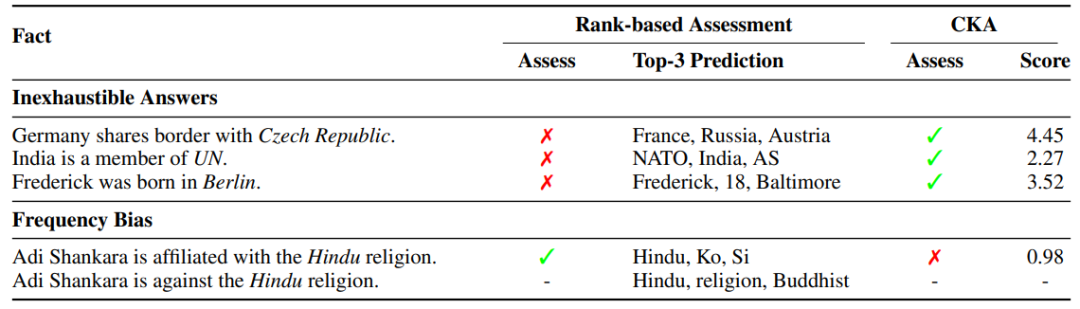
通过计算 CKA 分数检测模型学到的错误事实信息后,下一步考虑如何对这些错误事实进行校准。
根据之前的工作 [3] [4],可以将 Transformer 中的 FFN(Feed Forward Network) 层视为存储事实知识的 key-value 对, 因此,作者设计了一个类似于 FFN 层的网络层结构 CALINET,将每一个新加入的 key-value 对称作校正记忆槽,用于帮助调整原本 FFN 层的预测 token 分布,从而校准存储在 PLMs 中的错误事实。
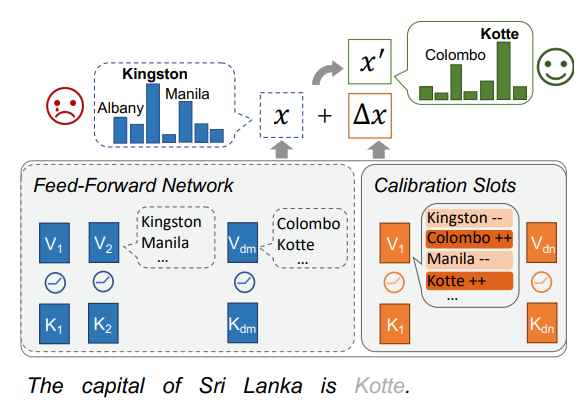
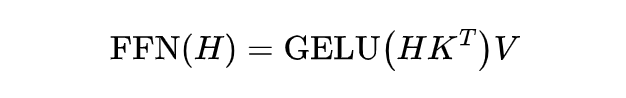
加入 CALINET 后,FFN 层的输出就变为:
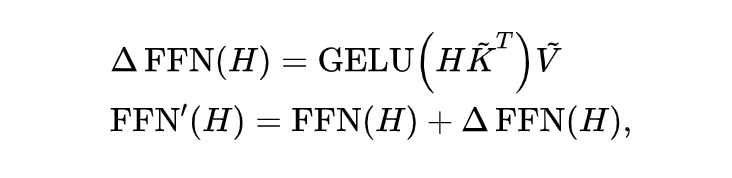
Obama was born in Hawaii
和
The birthplace of Obama is Hawaii
,描述的都是同一个事实。因此,作者基于 PARAREL 数据集
[5]
构建校准数据,其中包含
<'obama', 'born in', 'hawaii'>
知识对应的不同数据:

综上,通过在增强的数据上;利用 MLM 目标函数训练 CALINET 中新增的参数(冻结原有 PLMs 的参数),即可帮助模型校准知识,且不影响原本正确的事实知识。

Experiments
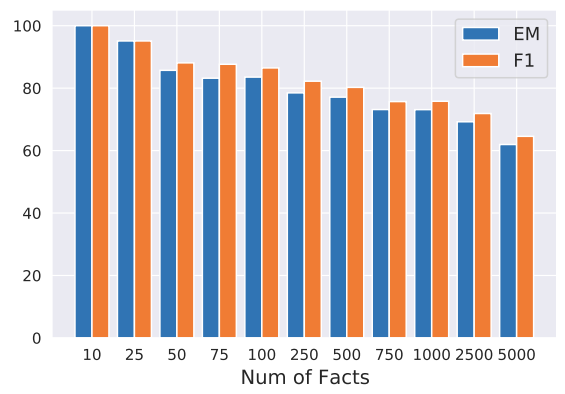
实验分为两部分,第一部分为检测实验,第二部分为校准实验。
t5-base
和
t5-large
的 CKA 分数,其中平滑系数
t5-decoder
的后面。作为对比试验,作者在校准数据集上继续与预训练
[7]
了两个预训练模型。
t5-base
从
t5
模型进行了微调。根据它们在测试集上的预测正确性,选取回答错误的问题,然后从 T-REx 中检索所有包含这些问题中任何实体的三元组。最后,利用
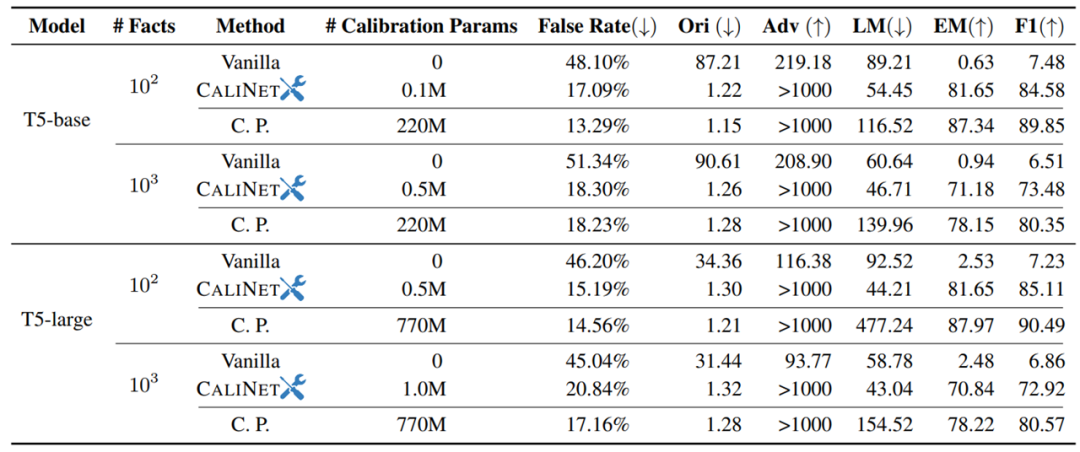
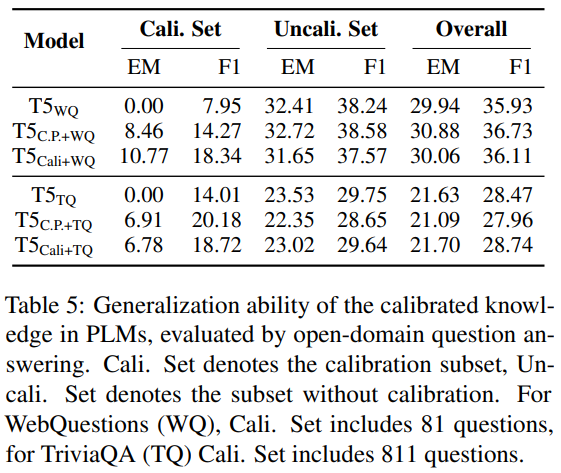
最终实验结果如下表所示,可以看到,模型在校准数据集中(Cali. Set)的 QA 表现有所提升,而不在校准数据集(Uncali. Set)中的 QA 表现没有变化,说明 PLMs 中的校准知识也可以用于 QA 任务:
lawyer、English
等高频词,而校准之后,模型不但能输出正确结果,并且也提升了相关同义词的输出概率。这说明作者提出的方法并不仅仅是学到了表面知识,而是真实提升了模型对相关事实知识的“理解”。

Conclusion

参考文献
[1] Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham Neubig. 2020. How can we know what language models know? TACL.
[2] Boxi Cao, Hongyu Lin, Xianpei Han, Le Sun, Lingyong Yan, Meng Liao, Tong Xue, and Jin Xu. 2021a. Knowledgeable or educated guess? revisiting language models as knowledge bases. In Proceedings of ACL.
[3] Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer feed-forward layers are key-value memories. In Proceedings of EMNLP
[4] Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. Knowledge neurons in pretrained transformers. In Proceedings of ACL.
[5] Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, and Yoav Goldberg. 2021. Measuring and improving consistency in pretrained language models. TACL, 9.
[6] Hady ElSahar, Pavlos Vougiouklis, Arslen Remaci, Christophe Gravier, Jonathon S. Hare, Frédérique Laforest, and Elena Simperl. 2018. T-rex: A large scale alignment of natural language with knowledge base triples. In Proceedings of LREC.
[7] Suchin Gururangan, Ana Marasovic, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of ACL.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」





