

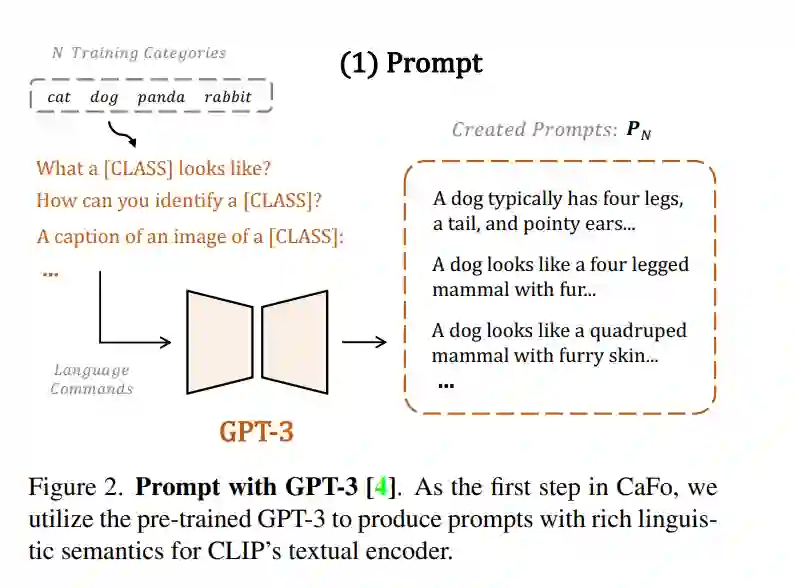
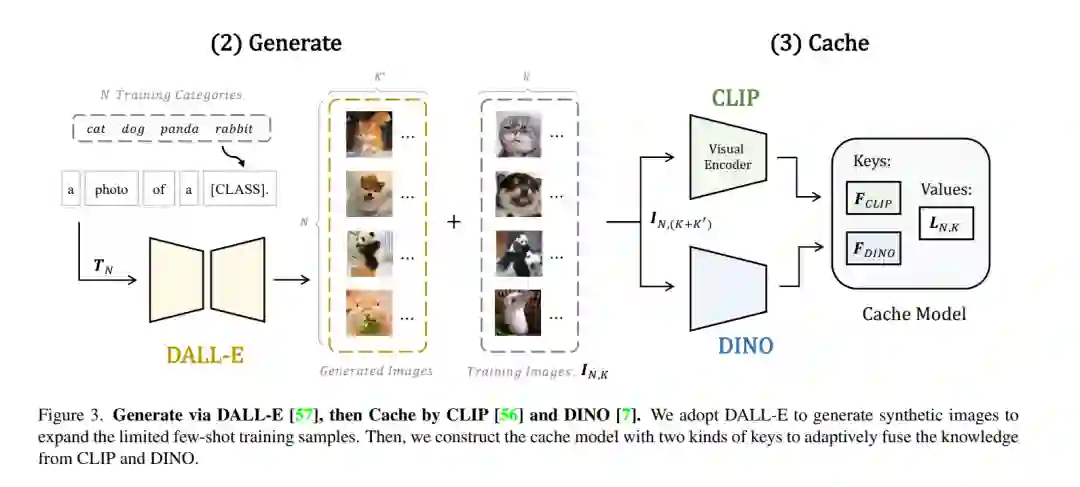
低数据环境下的视觉识别需要深度神经网络从有限的训练样本中学习广义表示。最近,基于CLIP的方法显示出有希望的少样本性能,得益于对比性语言-图像预训练。提出问题,是否可以通过级联更多样化的预训练知识来进一步辅助少样本表示学习。本文提出CaFo,一种级联的基础模型,融合了各种预训练范式的各种先验知识,以实现更好的少样本学习。CaFo融合了CLIP的语言对比知识、DINO的视觉对比知识、DALL-E的视觉生成知识和GPT-3的语言生成知识。具体来说,CaFo的工作原理是“提示,生成,然后缓存”。首先,利用GPT-3为具有丰富下游语言语义的提示片段产生文本输入。然后,通过DALL-E生成合成图像,以在不需要任何人工的情况下扩展少样本训练数据。最后,提出一种可学习的缓存模型来自适应地融合CLIP和DINO的预测结果。通过这种合作,CaFo可以充分释放不同预训练方法的潜力,并将它们统一起来,以执行最先进的少样本分类。代码可以在https://github.com/ZrrSkywalker/CaFo上找到。
https://www.zhuanzhi.ai/paper/6522618f8de51b1851243672034c9f7a
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
12+阅读 · 2021年5月30日
相关VIP内容
相关资讯