
大型语言模型(LLM)显示出强大的性能和发展前景,并在现实世界中得到广泛部署。然而,LLM可以从未经处理的训练数据中捕获社会偏见,并将偏见传播到下游任务。不公平的LLM系统具有不良的社会影响和潜在的危害。本文对LLM中公平性的相关研究进行了全面的综述。首先,对于中型LLM,分别从内在偏差和外在偏差的角度介绍了评价指标和去偏差方法。然后,对于大型LLM,介绍了最近的公平性研究,包括公平性评估、偏见原因和去偏差方法。最后,讨论并提出了LLM中公平性发展的挑战和未来方向。
大型语言模型(LLMs),如BERT(Devlin等,2019年),GPT-3(Brown等,2020年)和LLaMA(Touvron等,2023a年),在自然语言处理(NLP)的各种任务中展现出强大的性能和发展前景,并在现实世界中产生越来越广泛的影响。它们的预训练依赖于来自各种来源的大型语料库。许多研究已经验证,LLMs捕捉了未经加工的训练数据中的人类社会偏见,并且这些偏见体现在编码嵌入中,这些嵌入会传递到下游任务中(Garg等,2018年;Sun等,2019年)。不公平的LLM系统会对弱势或边缘化人群做出歧视性、刻板和有偏见的决策,从而引发不良的社会影响和潜在的危害(Blodgett等,2020年;Kumar等,2023年)。语言模型中的社会偏见主要源自于从人类社会收集的训练数据。一方面,这些未经审查的语料库包含大量反映偏见的有害信息,导致语言模型学习到刻板化的行为(Mehrabi等,2022年)。另一方面,训练数据中不同人口群体的标签存在不平衡,分布差异可能导致在假设同质性的模型应用于异质真实数据时产生不公平的预测(Shah、Schwartz和Hovy,2020年)。此外,语言模型学习过程中的人为因素或嵌入中的意外偏见可能引发甚至放大下游偏见(Bansal,2022年)。
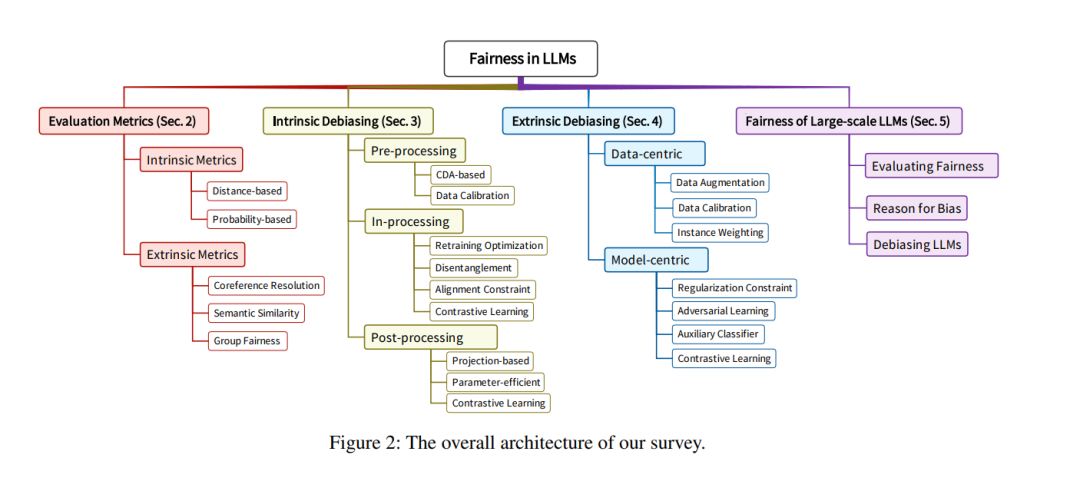
根据训练范式,LLMs可以分为预训练和微调范式,以及提示范式。在预训练和微调范式中,LLMs的参数少于十亿个,并且易于调整,例如BERT和RoBERTA(Liu等,2019年),我们称之为中等规模的LLMs。中等规模LLMs中的偏见可以大致分为两种类型:内在偏见和外在偏见(Goldfarb-Tarrant等,2021年),如图1所示。内在偏见对应于LLM编码的嵌入中的偏见,并反映了模型输出表示的公平性。外在偏见对应于下游任务的决策偏见,并反映了模型预测的公平性。在提示范式中,LLMs的参数超过十亿个,并且基于提示进行调整或不调整,例如GPT-4(OpenAI,2023年)和LLaMA-2(Touvron等,2023b年),我们称之为大规模的LLMs。大规模LLMs中的偏见通常在给定特定提示时体现在模型输出中。在本文中,我们对LLMs中的公平性相关研究进行了全面的回顾,总体架构如图2所示。重点关注预训练和微调范式下的中等规模LLMs,我们在第2节介绍了评估指标,在第3节和第4节分别介绍了内在去偏见方法和外在去偏见方法。在第5节中,提供了提示范式下大规模LLMs的公平性,包括公平性评估、偏见原因和去偏见方法。我们还在第6节中讨论了当前面临的挑战和未来发展方向。
