

大型语言模型(LLM)的出现显著地重塑了人工智能革命的发展轨迹。然而,这些LLM存在一个明显的限制,因为它们主要擅长处理文本信息。为了解决这一约束,研究人员努力将视觉能力与LLM整合,从而催生了视觉-语言模型(VLM)的出现。这些先进的模型在处理更复杂的任务,如图像描述和视觉问答等方面发挥着重要作用。在我们的综述论文中,我们深入探讨了VLM领域的关键进展。我们的分类将VLM分为三个不同的类别:致力于视觉-语言理解的模型、处理多模态输入以生成单模态(文本)输出的模型,以及同时接受和产出多模态输入和输出的模型。这一分类基于它们在处理和生成各种数据模态方面的相应能力和功能。我们对每个模型进行了细致的解析,提供了其基础架构、训练数据来源以及可能的优点和限制的广泛分析,以便为读者提供对其核心组件的全面理解。我们还分析了VLM在各种基准数据集中的表现。通过这样做,我们旨在提供对VLM多样化景观的细致理解。此外,我们强调了在这一动态领域未来研究的潜在途径,期待进一步的突破和进展。
大型语言模型(LLM)的出现标志着人工智能领域变革性时代的开始,重塑了整个行业的格局。横跨学术界和工业界的研究实验室正积极参与到一个竞争激烈的赛跑中,以推动LLM的能力发展。然而,这些模型面临一个显著的限制——它们仅限于处理单一模态的数据,特别是文本。这一约束突显了在持续完善LLM以便跨多种模态无缝运作的过程中一个关键的挑战,这是AI领域进一步创新的重要途径。
天生的智能擅长处理多种模态的信息,包括书面和口头语言、图像的视觉解释以及视频的理解。这种无缝整合不同感官输入的能力使人类能够导航复杂的现实世界。为了模仿人类的认知功能,人工智能同样必须拥抱多模态数据处理。这一需求不仅仅是技术性的,更是为了让AI系统在现实世界场景中具备上下文意识和适应性而必需的。
为了应对这些限制,研究人员开创了一种称为视觉-语言模型(VLM)的尖端神经模型类别。这些模型复杂地结合了视觉和文本信息,展现出在理解和生成涉及图像和文本的内容方面的卓越能力。VLM在执行图像描述、响应视觉查询和基于文本描述生成图像等任务方面表现出多才多艺的能力。它们无缝整合视觉和语言模态的能力使它们站在技术进步的前沿,使它们能够以无与伦比的技巧导航图像与文本之间的复杂相互作用。
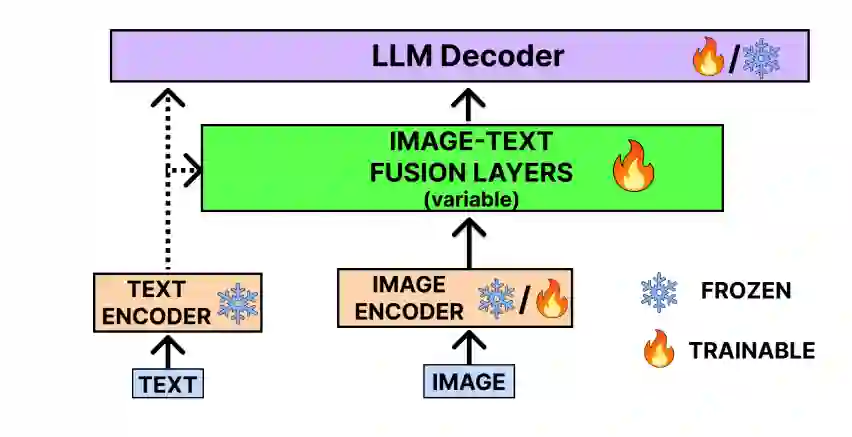
近期,主要研究实验室持续推出创新的VLM,包括DeepMind的Flamingo、Salesforce的BLIP和OpenAI的CLIP。例如GPT-4(V)和Gemini展示了聊天机器人在VLM领域的进化。值得注意的是,并非所有多模态模型都是VLM;例如,像Midjourney和DALL-E [Ramesh et al., 2021]这样的文本到图像模型缺乏语言生成组件,凸显出多模态AI领域的多样化景观。VLM的一般架构包括一个图像和文本编码器,用于生成嵌入,这些嵌入然后在图像-文本融合层中融合,融合后的向量通过LLM生成最终的视觉感知生成文本。VLM的工作原理在图2中显示。
在这篇综述论文中,我们根据它们的输入处理和输出生成能力,将VLM分为三大类:视觉-语言理解模型、多模态输入文本生成模型和最先进的多模态输入-多模态输出模型。随后的各节深入解释了每一类别,阐明了这些多样化VLM框架的细微功能和能力。
近期的相关综述,如[Wang et al., 2023b]主要探讨了用于开发多模态模型的各种预训练技术和数据集,[Yin et al., 2023]探讨了训练各种多模态语言模型的关键技术。[Wu et al., 2023a]提供了使用多模态语言模型的实际应用和指导。最新的一篇由[Zhang et al., 2024]深入介绍了大约26种最新的VLM。与之前的综述相比,没有一个系统地根据它们的输入处理和输出生成能力对视觉-语言模型(VLM)进行分类。我们的综述通过提供对VLM的彻底分类,揭示了它们功能的复杂性。我们广泛分析了不同VLM在基准数据集上的表现,特别包括最新的MME基准,提供全面的见解。我们的综述代表了迄今为止最全面、最新的VLM汇编,涵盖了大约70个模型。它为用户提供了在这一开创性研究领域不断演变的视觉-语言模型的最新和最全面的见解,是最终的指南。
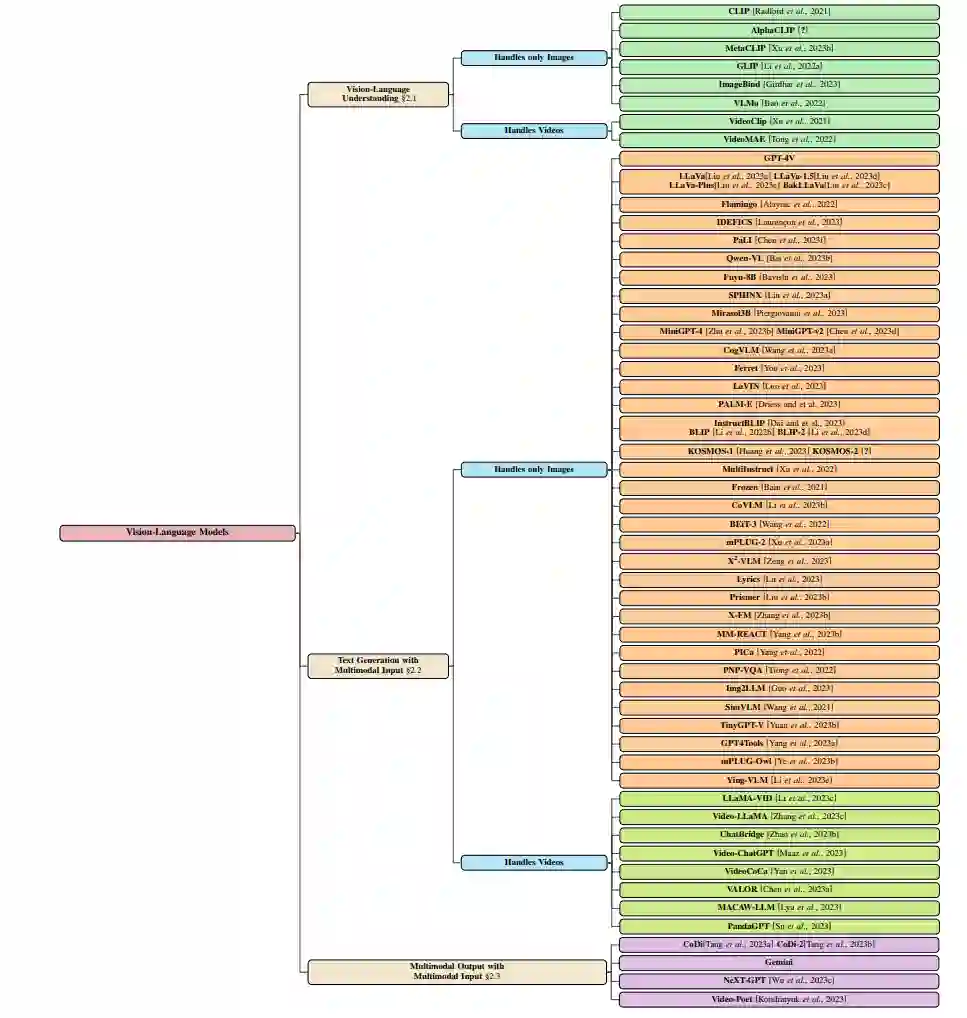
图1:视觉语言模型的分类,突出显示模型能够处理的输入和输出格式。
2 视觉-语言模型(VLM)
在本节中,我们对VLM进行了全面的考察,将它们分类为三个主要类别: * 视觉-语言理解(VLU):这一类别包括专门为解释和理解视觉信息与语言结合的模型。 * 多模态输入的文本生成:在这一分类中,我们探索了在利用多模态输入的同时,擅长生成文本内容的模型,从而融合了多种形式的信息。 * 多模态输出与多模态输入:这一类别深入研究了通过处理多模态输入来生成多模态输出的模型。这涉及到多种模态的合成,如视觉和文本元素,以产生全面而连贯的结果。我们在图1.1中展示了这一宽泛的分类。
比较分析 我们对几种视觉和语言模型(VLM)进行了广泛的分析,这些模型跨越了十个广泛认可的基准数据集,涵盖了视觉问题回答(VQA)和图像描述等任务。这一分析的结果呈现在表1中。此外,我们还使用多模态模型评估(MME)基准评估了这些VLM的感知和认知能力,其发现总结在表2中。更进一步,对各种VLM在视频问题回答数据集上的比较考察详细记录在表3中。 3. 未来方向
预训练与模块结构之间的权衡:当前有很多研究正在进行中,通过引入模块化代替黑盒预训练,以增强VLM的理解、控制和可信度。纳入其他模态:正在进行的工作包括引入更精细的模态,如受[Cheng et al., 2022]启发的注视/手势,这对教育行业非常重要。VLM的细粒度评估:正在进行更细致的VLM评估,关注偏见、公平等参数。在这方面的一些研究包括DALL-Eval [Cho et al., 2023a]和VP-Eval [Cho et al., 2023b]。VLM中的因果关系和反事实能力:已经完成了很多工作,以理解LLM的因果和反事实能力,这激发了研究人员在VLM领域探索相同的问题。Cm3 [Aghajanyan et al., 2022]是该领域的最早工作之一,该主题目前非常活跃。持续学习/遗忘:VLM领域存在一个趋势,即有效地持续学习,无需从头开始训练。VQACL [Zhang et al., 2023a]和Decouple before Interact [Qian et al., 2023]是该领域的最初工作之一。受到LLM中观察到的知识遗忘概念[Si et al., 2023]的启发,研究人员也在VLM领域探索类似的方法。训练效率:研究人员集中精力开发高效的多模态模型,如BLIP-2显示出前景,它在零样本VQA-v2中的表现超过Flamingo-80B 8.7%,同时使用的可训练参数显著减少(少54倍)。VLM的多语种基础:继OpenHathi [sarvam.ai, 2023]和BharatGPT [corovor.ai, 2023]等多语种LLM的最近激增之后,开发多语种视觉-语言模型(VLM)的势头正在增强。更多领域特定的VLM:各种领域特定的VLM,如MedFlamingo [Moor et al., 2023]和SkinGPT [Zhou et al., 2023]项目示例,已在其专业领域铺平了道路。进一步的努力正在进行中,以特别为教育和农业等行业量身定制VLM。
4 结论
本文提供了一个关于VLM领域最新发展的综述。我们根据VLM的用例和输出生成能力对其进行分类,提供了对每个模型架构、优点和局限的简洁见解。此外,我们突出介绍了该领域的未来方向,这些方向是根据近期趋势来提供进一步探索的路线图。我们相信这篇论文将作为一个宝贵的资源,为在多模态学习领域积极涉猎的计算机视觉和自然语言处理领域的研究人员提供指导。