
© 作者|李依凡 机构|中国人民大学研究方向|自然语言处理 多模态大模型能够根据图片内容与用户展开对话,完成复杂任务,但可能对图像中的物体产生幻觉。本文探讨并评估了目前多模态大模型的幻觉问题。实验发现目前的多模态大模型存在较严重的幻觉问题,并且该问题可能受多模态指令数据集中物体分布的影响。本文还介绍了一种更稳定、灵活的物体幻觉评测方式POPE。

论文题目:Evaluating Object Hallucination in Large Vision-Language Models 论文链接:https://arxiv.org/abs/2305.10355 论文代码:https://github.com/RUCAIBox/POPE
引言
大型语言模型在自然语言处理领域取得了革命性的进展,其成功也推动了多模态领域的发展。最近,诸如MiniGPT-4, LLaVA等多模态大模型 (Large Vision-Laguage Models, LVLMs) 向我们展示了令人印象深刻的多模态对话能力。给定一张图片,这些模型可以回答用户提出的关于图片的各种问题。从较为基本的物体识别或者图片描述,到更具挑战性的根据图片写广告,作诗,LVLMs的回答都像模像样。然而我们发现,LVLMs虽然在较为复杂的图像问答问题上表现出色,却难以正确回答一些看似更简单的问题,例如判断图像中是否存在某物体。在 image captioning 领域,这种模型生成了图像中不存在的物体的现象被称为物体幻觉 (Object Hallucination)。

本文通过定量实验测评了已有LVLMs的物体幻觉程度,并分析了其指令数据集的分布对幻觉的影响。此外我们还发现传统的物体幻觉评测方法在评测LVLMs时存在一定的局限性,并提出了一种基于轮询的物体探测评测方法 (Polling-based Object Probing Evaluation, POPE)。实验结果表明 POPE 具有更好的稳定性,并且能够扩展到未标注数据集上。
基于指令的评测
我们首先使用CHAIR指标在MSCOCO数据集上测试了最近的一些LVLMs。
评测设置
评测指标
CHAIR (Caption Hallucination Assessment with Image Relevance ) (Rohrbach et al., 2018) 是一种用于评估 image captioning 任务中物体幻觉的常用指标。给定图像中的真实物体,CHAIR计算出出现在模型生成的图像描述中但不在图像中的物体的比例。其两个变体和分别在对象实例级别和句子级别评估幻觉程度。具体计算公式为:
数据集
我们从MSCOCO数据集的验证集中随机选取了的2000张图像和人工标注的图像描述作为我们的评估数据集。在计算CHAIR指标时,我们遵循原论文的设置,仅考虑MSCOCO分割挑战中出现的80个物体。我们还使用了同义词列表,将生成的图像描述中的同义词映射到MSCOCO物体,避免将它们误判为幻觉物体。
模型
我们评估了5个最近提出的LVLMs,即MiniGPT-4,LLaVA,Mulimodal-GPT,mPLUG-Owl以及InstructBLIP。下表展示并比较了这些模型的结构和训练策略。
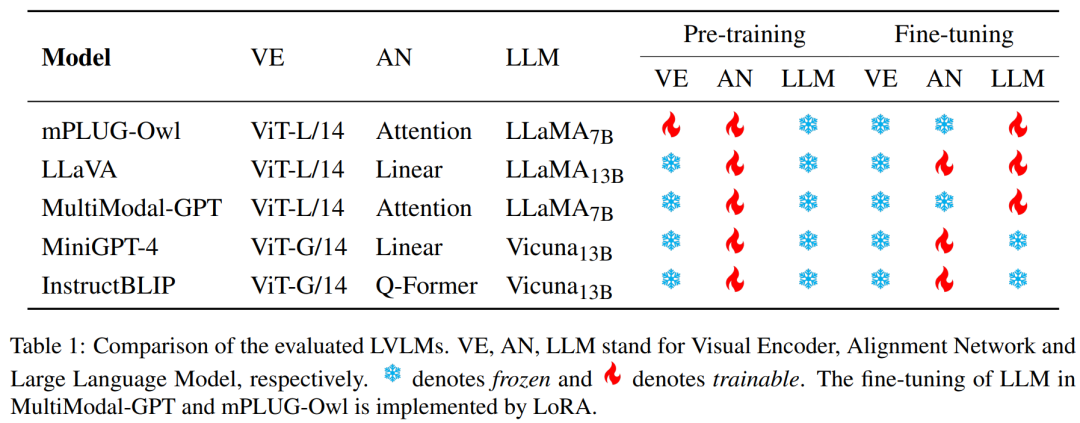
我们使用了如下指令来让模型生成对图像的描述:
- Instruction 1: Generate a short caption of the image.
- Instruction 2: Provide a brief description of the given image.
另外,我们还引用了一些较小的视觉-语言预训练模型 (VLPMs) 在MSCOCO上的物体幻觉结果,包括 OSCAR,VinVL,BLIP和OFA。
评测结果
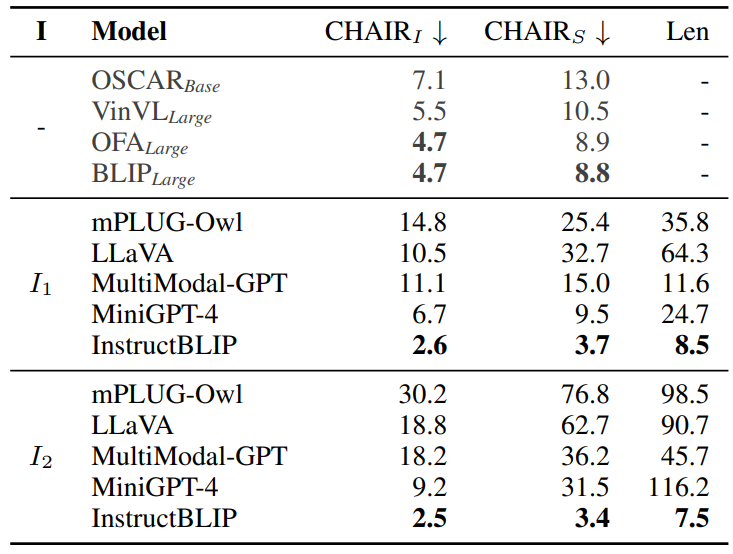
评测结果如上表所示。结果显示大部分 LVLMs 的物体幻觉问题反而比规模更小的 VLPMs 更严重。其中 InstructBLIP 的幻觉问题最轻微,这可能是由于其多模态指令从已有的数据集中收集,并且长度较短有关。而其他 LVLMs 大多借助 LLMs 来生成多模态指令,通过这种方式生成的指令往往包含更丰富的信息并且更长,但可能本身就含有幻觉信息。 此外,我们还发现这种基于指令的评测方式在评测 LVLMs 时存在一定的局限性。首先是稳定性问题,虽然我们设计的两条指令具有相近的语义,但模型根据这两条指令生成的图像描述的幻觉严重程度确存在很大差异。另外在不同指令下,模型的性能排名也可能发生改变(例如LLaVA和Multimodal-GPT的在 上的结果)。最后,CHAIR 在计算结果时需要判断图像描述中的物体是否出现在物体中,而图像的生成结果并不会局限于 MSCOCO 中的80种物体,因此需要人工设计同义词的映射规则,可能导致对幻觉的遗漏或者误判。
指令数据集对幻觉的影响
LVLMs 和 VLPMs 在训练过程上的主要区别在于 LVLMs 经历了多模态指令微调。鉴于 VLPMs 的物体幻觉问题明显好于 LVLMs,我们猜测多模态指令微调这个步骤可能是影响幻觉严重程度的主要原因。通过实验,我们发现 LVLMs 确实更容易对在多模态指令数据集中频繁出现/共现的物体产生幻觉。
频繁出现物体的影响
由于大部分多模态指令数据是在 MSCOCO 的基础上构造的,它们也可能继承了其中不平衡的物体分布,即部分物体频繁在数据中出现。因此在这些数据上微调后,LVLMs也可能倾向于生成这些物体。为了验证这一猜想,我们首先绘制了物体出现频率和幻觉频率的柱状图,如下图(a)所示。该图的横轴上的物体是在 MSCOCO 中出现频率最高的物体,并且频率从左到右依次降低。我们收集了MiniGPT-4, LLaVA, Multimodal-GPT和mPLUG-Owl在这些物体上的幻觉频率。从图中可以看出,幻觉频率基本从左到右依次降低,和物体出现频率的变化较为一致。因此 LVLMs 确实容易在频繁出现的物体上产生幻觉。
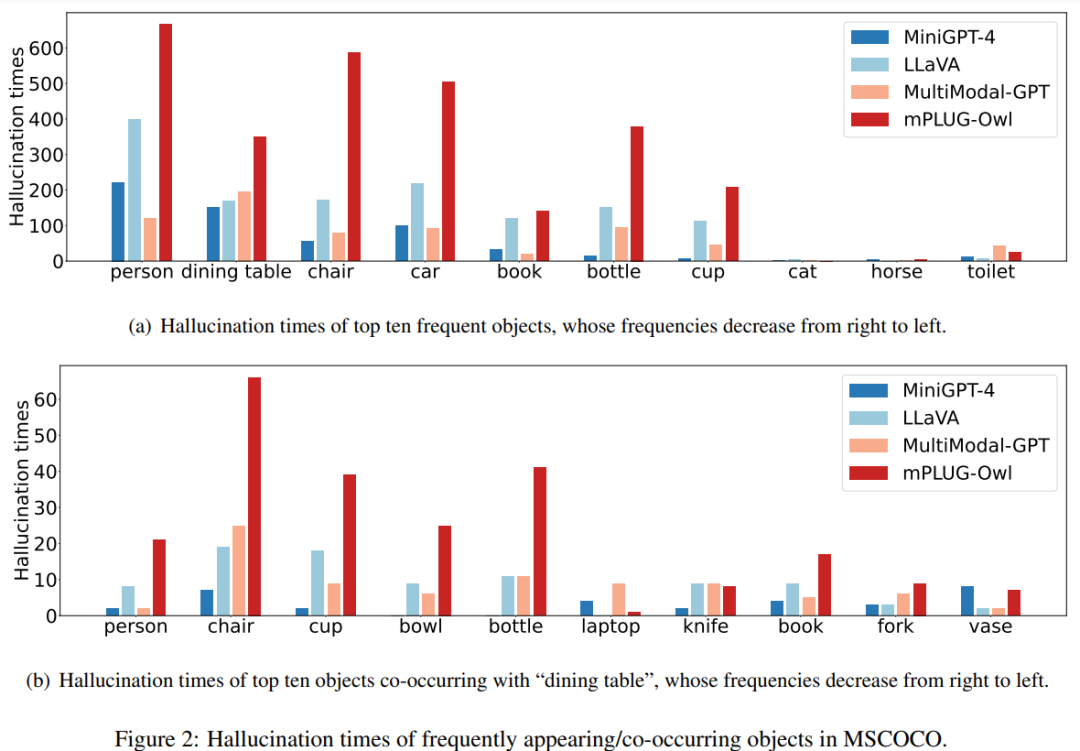
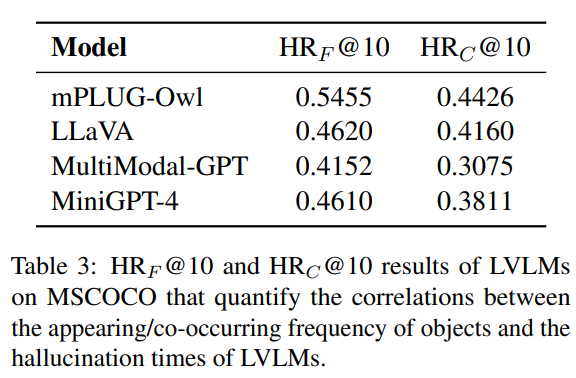
为了进一步定量分析这种现象,我们计算了频繁出现物体和所有幻觉物体之间的 Hit ratio@k ,以衡量它们间的一致性,其公式为: 其中是所有图像的总数,Hallucinated()表示在第张图中幻觉物体的个数,是幻觉物体中属于 MSCOCO 出现频率前k个的物体个数,从而能够反映频繁出现的物体占幻觉物体的比例。结果如下表左栏所示,几乎所有的 LVLMs 都在0.5左右,因此多模态指令数据集中高频出现的物体确实更容易出现幻觉。
频繁共现物体的影响
除了频繁出现的物体,数据集中一些频繁共现的物体组也可能影响幻觉问题(例如电脑,鼠标,键盘)。当图像中存在这些组中的某个物体时,模型可能会在组内其他物体上产生幻觉。我们使用了相似的实验验证该猜想,分析了和'dining table'频繁共现物体的幻觉情况。前图(b)中,物体的共现频率和幻觉频率也有较一致的变化规律。定量分析方面,我们定义 其中是共现的参考物体(即本次实验中的'dining table'),是幻觉物体中前个和高频共现的物体个数。结果展示在上表右栏中,可以发现大部分 LVLMs 的该项指标依然较高。因此频繁共现的物体组也会影响 LVLMs 的幻觉。
POPE
鉴于目前对 LVLMs 的物体幻觉评测方法存在诸多局限性,我们提出了POPE。
概述
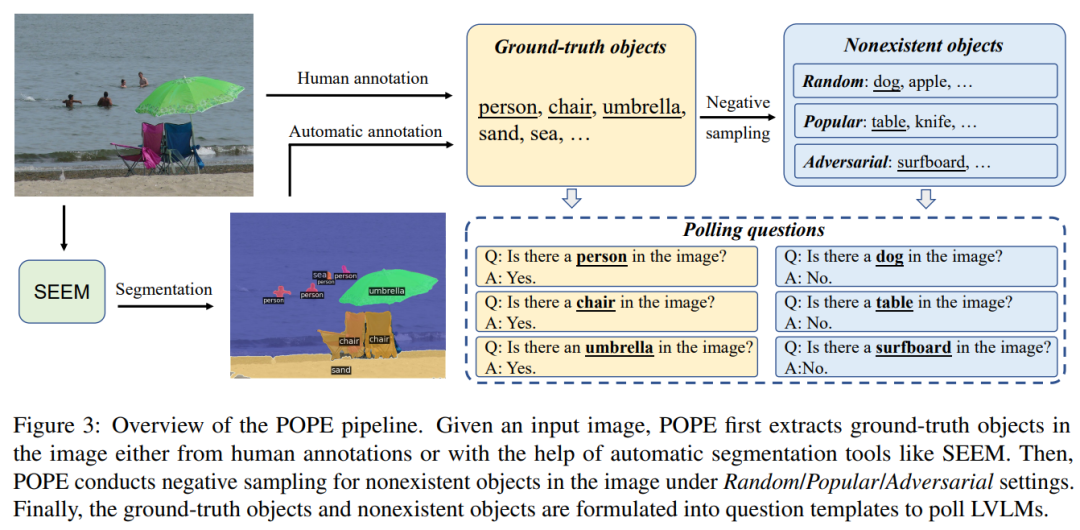
如上图所示,POPE 将幻觉评估转换为让模型回答一系列关于物体是否存在于图像中的判断题(例如'Is there a car in the image?')。具体而言,给定一个图像数据集和每张图像包含的物体标注,POPE将构造一系列由图像,问题和回答组成的三元组,可形式化表示为: 其中 表示图像,是待测试的物体,既可以是图像中真实存在的物体,也可以是自定义的不存在于图像中的物体,是测试物体 的问题, 是对该问题的回答('Yes' 或 'No')。 实验细节方面,我们将图像中真实存在的物体和不存在的物体之间的比例设置为1:1,并且使用二分类任务常用的 Accuracy, Recall, Precision 和 F1 Score 作为评测指标。此外为了更好的分析模型行为,我们还记录了模型回答 'Yes' 的比例。 关于图像中未出现物体的选择,我们受此前关于多模态指令数据对幻觉影响的分析启发设计了三种采样策略:
- Random sampling:随机选取不在图像中的物体
- Popular sampling: 优先选取出现频率较高的物体
- Adversarial sampling: 优先选取和图像中物体频繁共现的物体
评测结果
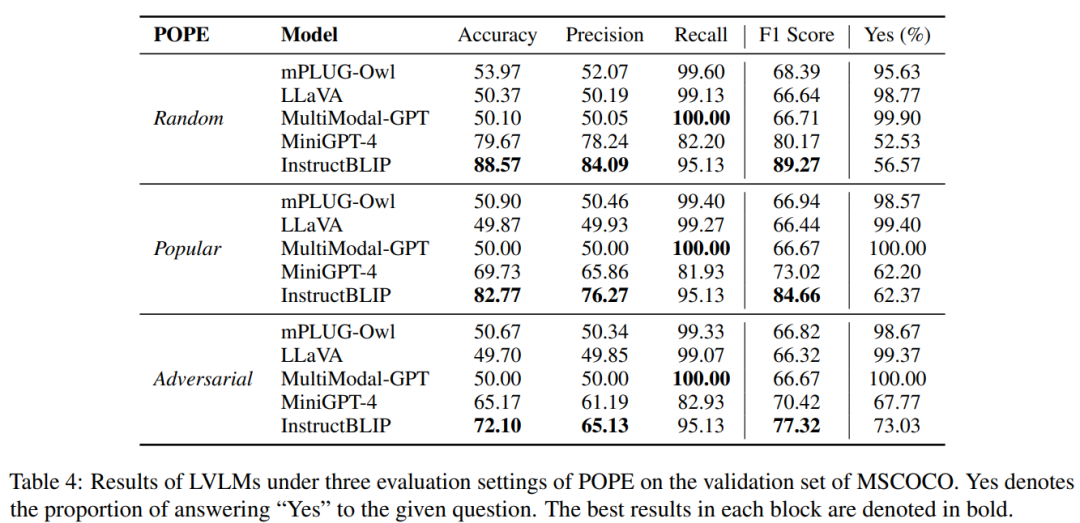
实验结果如上图所示,各模型的表现和此前的 CHAIR 指标基本一致,即 InstructBLIP 表现较好,而 mPLUG-Owl, LLaVA 和 Multimodal-GPT 幻觉较严重。可以注意到根据 F1-Score 判断,三种采样方式下的 POPE 的难度有所不同,体现为 Adversarial > Popular > Random,这也进一步验证了我们此前的分析,即多模态指令数据集中的频繁出现/共现物体更容易产生幻觉。此外我们还观察到部分 LVLMs 倾向于对所有的问题都回答 'Yes'。
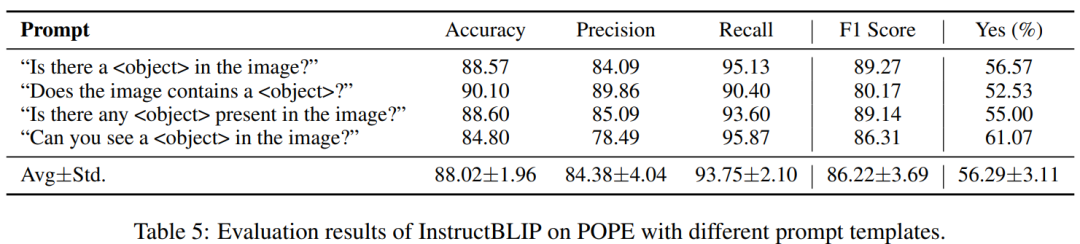
为了测试 POPE 的稳定性,我们还设计了另外3中问题模板,并在InstructBLIP上进行了测试,同时计算了其均值和标准差,结果如上表所示。可以看出 POPE 在使用不同问题模板的情况下各项指标变化幅度不大,较为稳定。
无标注数据集评测
通过和 SEEM 等自动分割工具结合,POPE 也可以被拓展到无标注的图像数据集上用于测试。为了验证 POPE 在无标注数据集上的性能,我们用 SEEM 标注了 MSCOCO, A-OKVQA 和 GQA 三个数据集中的各500张图片,并沿用此前的方法构造了三种 POPE。我们测试了 LLaVA,MiniGPT-4 和 InstructBLIP 的表现,并且还测试了幻觉较轻的 BLIP 作为参照。MSCOCO 上的实验结果如下表所示。
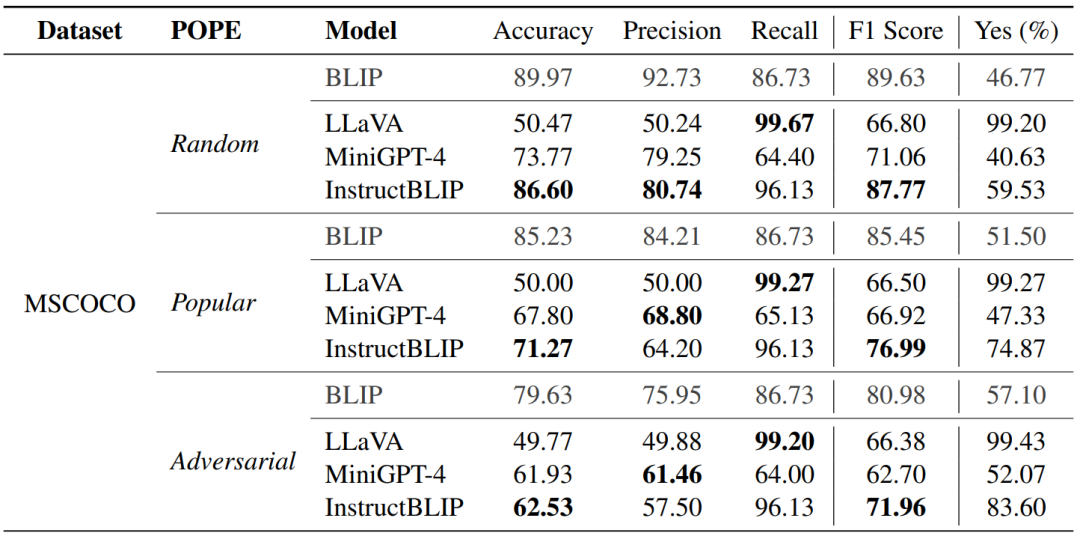
实验结果显示使用 SEEM 构建的 POPE 依然具有相同的难度趋势 (Adversarial > Popular > Random),在大部分指标上也和使用人工标注构建的 POPE较为一致。我们也注意到部分指标上二者存在一定差异,例如 MiniGPT-4 在 Adversarial 采样下的 F1 Score。我们认为这是由于 SEEM 的分割结果相较于 MSCOCO 中的人工标注粒度更细,模型做出判断的难度更大,导致结果相对较低。
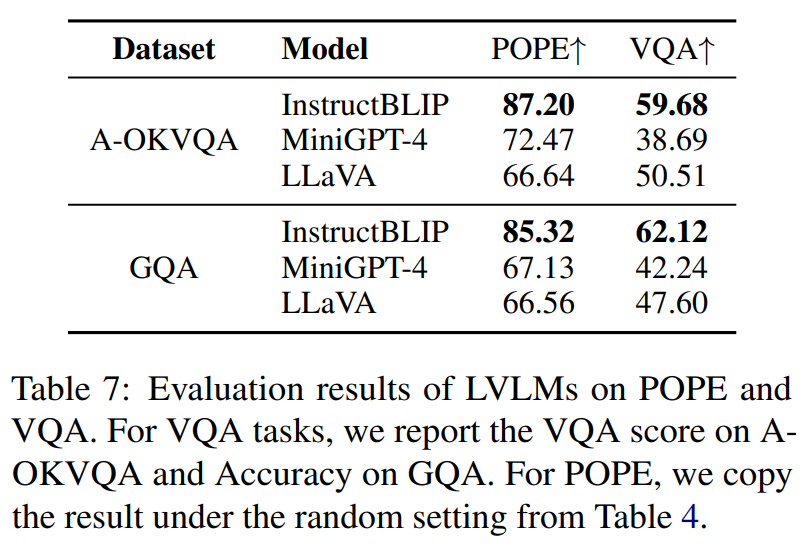
幻觉与VQA性能的关系
为了进一步研究幻觉问题和 LVLMs 性能之间的关系,我们在 A-OKVQA 和 GQA 上测试了部分 LVLMs 的性能。由于 LVLMs 的回答大都属于较长的开放式回答,我们难以继续使用传统的 VQA 评测方法。为此我们借助了 ChatGPT 来辅助测评,我们提供给 ChatGPT 的 prompt 如下:
- “You are an examiner who can judge whether a student’s answer matches the correct answers. Next, I will provide you with the correct answer and a student’s answer. Please judge whether the student’s answer matches the correct answers.”
测评结果如下表所示。InstructBLIP 在幻觉和 VQA 任务中都取得了最好的表现,而 MiniGPT-4 和 LLaVA 在二者上的结果趋势并不一致。我们认为这些差异和 LVLMs 的使用的指令形式有关,例如 MiniGPT-4 的指令是较简单的图像描述任务,而 LLaVA 的指令包含更多较复杂的对话或推理任务,使其更擅长处理 VQA 任务。总之,上述结果说明在评估现有 LVLMs 的性能时,幻觉和 VQA 性能都需要被考虑。
总结
我们测试了多个LVLMs在物体幻觉问题上的表现。我们通过实验发现,视觉指令数据集中的物体分布会影响LVLMs的物体幻觉。此外,我们还发现现有的幻觉评估方法可能受到输入指令影响,从而导致评估结果不够可靠。为此我们提出了一种基于轮询的物体探测评估方法,称为POPE。实验结果表明,我们提出的POPE方法在评估LVLMs的对象幻觉问题上更为有效。