
© 作者|杨锦霞 机构|中国人民大学研究方向|多模态学习
引言:近期,大型语言模型在各种任务上展现出优异的性能,展示了广阔的应用前景。然而,在医学领域,现有的模型主要是单一任务系统,缺乏足够的表达能力和交互能力。因此,目前的模型与实际临床工作流程中对它们的期望之间存在差距。虽然大型语言模型的出现和发展为交互式医学系统带来了希望,但由于其可能生成错误的输出和产生幻觉等问题,不能直接应用于实际场景。目前关于大模型在医学领域的研究主要集中在评估现有模型性能、构建适用的数据集以及指令微调等方面。文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
Large Language Models Encode Clinical Knowledge http://arxiv.org/abs/2212.13138 本文的主要工作包括benchmark构建、LLM评测和指令微调。
提出一个涵盖医学检查、医学研究和消费者医疗问题的医学问答benchmark:MultiMedQA。这是一个由七个医学问答数据集组成的基准,包括六个现有数据集和新引入的一个数据集。这是一个评估LLM临床知识和问答能力的多样化基准,包括多项选择题、需要对医疗专业人员的问题进行较长格式回答的数据集,以及需要对非专业人员可能提出的问题进行较长格式回答的数据集。本文还提出了一个医生和非专业用户评估框架,从多个维度来评估LLM性能。
本文在MultiMedQA上评估了PaLM及Flan-PaLM。通过结合各种提示策略(few-shot, chain-of-thought and self-consistency prompting),Flan-PaLM在MedQA(USMLE),MedMCQA,PubMedQA和MMLU临床主题上超过了SOTA性能。特别是,它比之前的MedQA上的SOTA(USMLE)提高了17%以上。
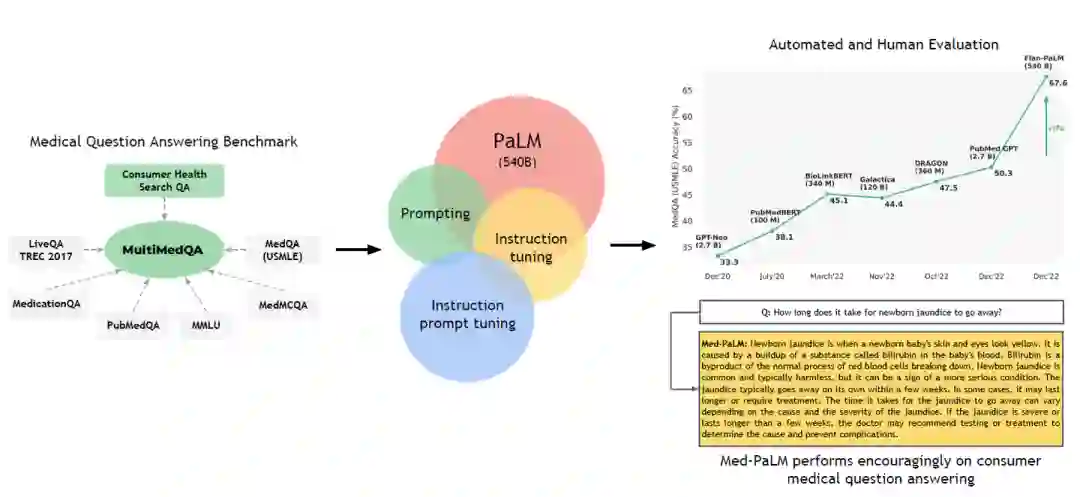
由于在生成长文本的数据集上,Flan-PaLM和临床医生的结果显示出一定gap。本文提出了使用Instruction Prompt Tuning对Flan-PaLM进行微调。使用soft prompt作为在多个医学数据集之间共享的初始前缀,然后是相关的特定于任务的prompt(由instructions和/或few-shot示例组成,可能是CoT)以及实际问题和上下文。通过随计选取和人工评估过滤,最终使用40个来自HealthSearchQA,MedicineQA和LiveQA的例子用于Instruction Prompt Tuning训练,得到Med-PaLM模型。

Towards Expert-Level Medical Question Answering with Large Language Models http://arxiv.org/abs/2305.09617 本文提出了Med-PaLM 2,是上面Med-PaLM工作的改进,它通过结合PaLM 2、医学领域微调和提示策略(包括一种新颖的ensemble refinement策略)来提升性能。Med-PaLM 2 在 MedQA 数据集上的得分高达 86.5%,比 Med-PaLM 提高了19%。
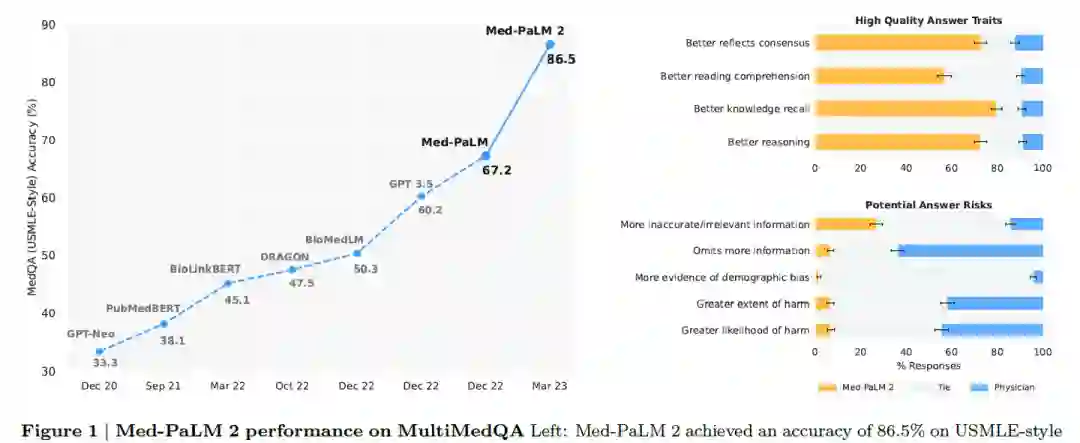
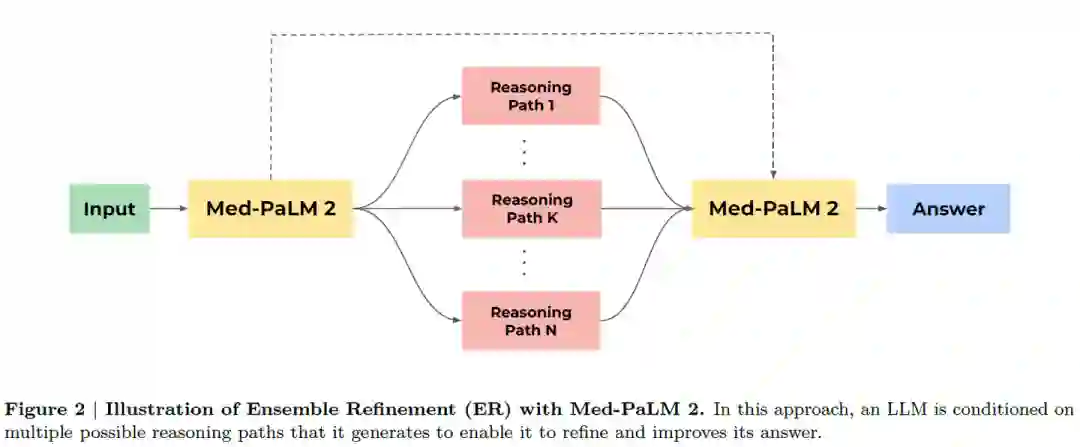
在CoT和self-consistency的基础上,本文提出了一个新的提示策略:ensemble refinement (ER)。ER涉及两个阶段:首先,给定一个prompt和一个问题,模型输出多个解释和答案。然后,以原始prompt、问题和上一步的生成输出为条件进行提示,模型会生成更加精细的解释和答案。这可以理解为self-consistency的泛化,LLM汇总第一阶段的答案而不是简单的投票,使LLM能够考虑其生成的解释的优点和缺点。在这里,为了提高性能而多次执行第二阶段,然后最后对这些生成的答案进行多数投票以确定最终答案。
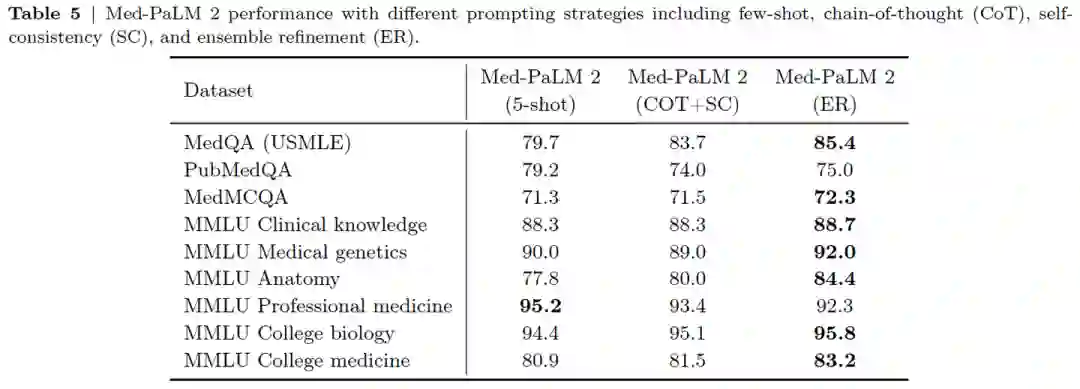
下表展示了Med-PaLM 2 在不同的提示策略下的性能。可以看出ensemble refinement改进了CoT和SC,从而促使策略在这些基准测试中获得了更好的结果。
本文还引入了两个对抗性问题数据集来探索这些模型的安全性和局限性。 ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge http://arxiv.org/abs/2303.14070 ChatDoctor是一个主要在LLaMA上微调的医学领域的大语言模型。 * 收集对话数据集:出于真实性的考虑,本文从在线医疗咨询网站“HealthCareMagic”收集了约10万条真实的医患对话,并对这些数据进行了人工和自动过滤等预处理,并命名为 HealthCareMagic-100k。此外,从在线医疗咨询网站 iCliniq2 收集了大约1万条医患对话用于以评估模型的性能。 * 外部知识大脑:如果模型能够根据给定的权威可靠知识进行回答,那么模型的准确性将大大提高。对于医疗场景中的问答,本文收集并编译了一个数据库,其中包括大约 700 种疾病及其相关症状、进一步的医学测试或措施以及推荐的药物治疗。该数据库可以随时更新,无需重新训练模型。除了疾病数据库,一些权威的信息源也可以作为外部知识大脑,例如维基百科。
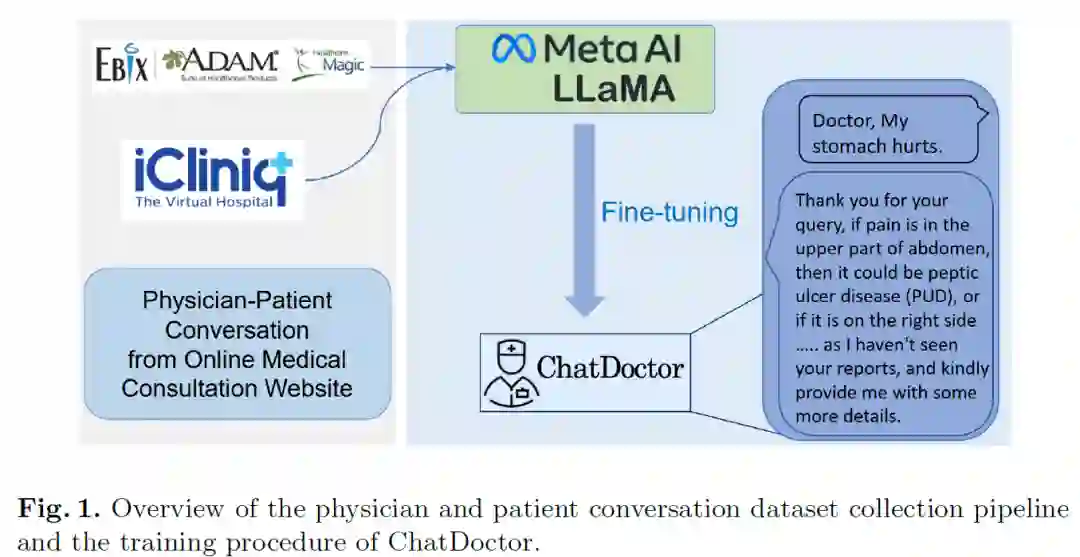
ChatDoctor可以检索相应的知识和可靠的来源,以更准确地回答患者的询问。构建完外部知识大脑后,通过构造适当的prompt让ChatDoctor自主检索其所需要的知识。
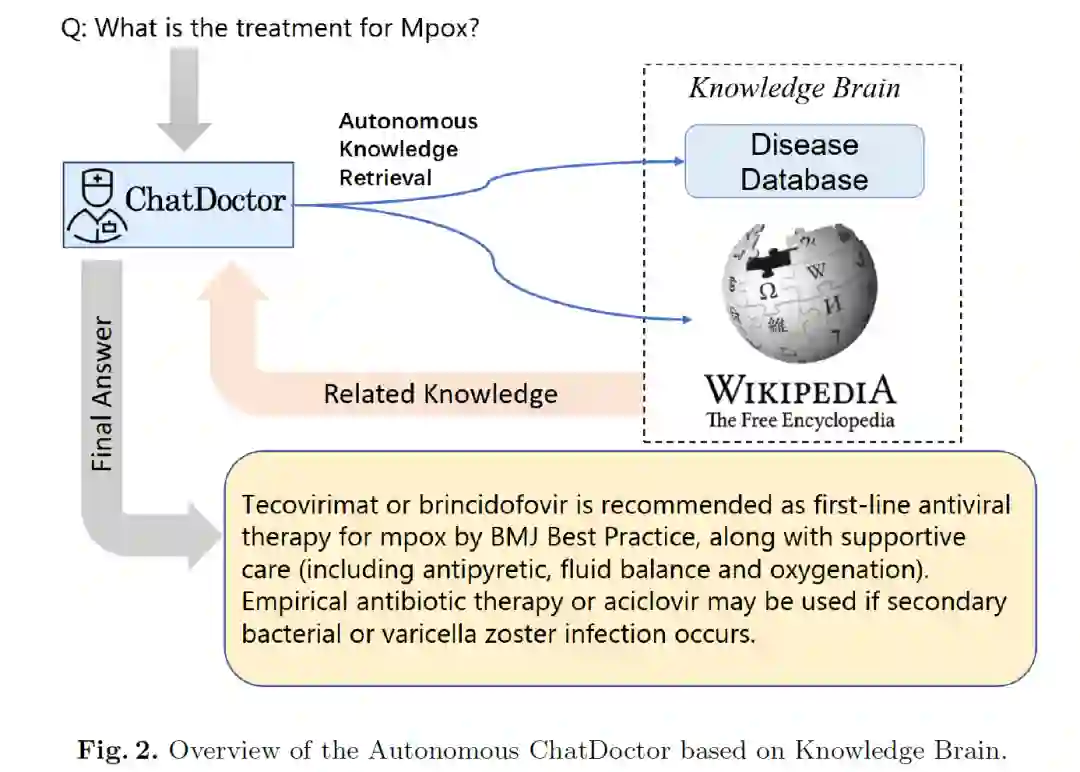
本文先通过Stanford Alpaca的数据微调以获得对话的能力,然后在收集的医学对话数据集上微调。为了测试基于知识大脑的ChatDoctor模型的能力,向该模型询问了一些最近的医学问题,例如上图中的Mpox(monkeypox,猴痘),由于这是一个新术语,ChatGPT 完全无法回答它,而 ChatDoctor 可以自主检索 Mpox 的维基百科内容并给出准确的答案。
BenTsao: Tuning LLaMA Model With Chinese Medical Instructions http://arxiv.org/abs/2304.06975 本文提出了本草模型(原叫“华驼“),一个生物医学领域的中文LLM。BenTsao建立在开源LLaMa-7B模型的基础上,整合了来自中国医学知识图谱(CMeKG)的结构化和非结构化医学知识,并采用基于知识的指令数据进行微调。

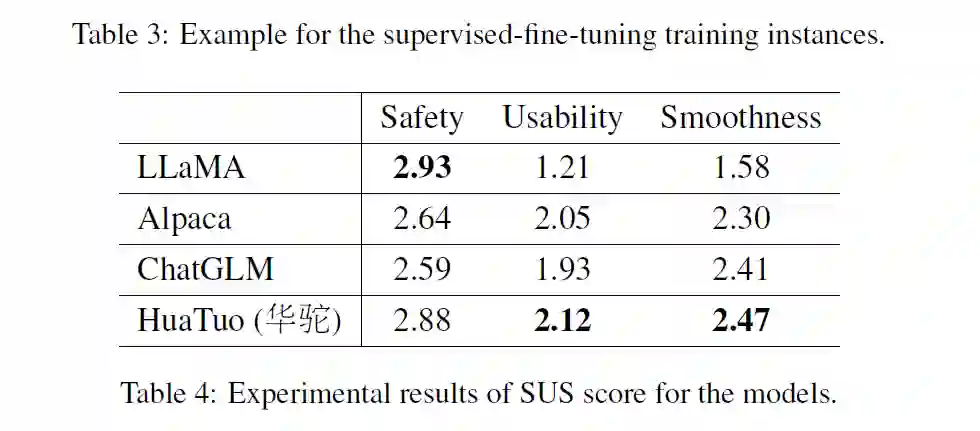
数据集:医学知识有各种类型,一般包括结构化的医学知识,如医学知识图谱,和非结构化的医学知识,如医学指南等。本文利用了中国医学知识图谱CMeKG,该图谱提供了有关疾病、药物、症状等的医学知识,并借助ChatGPT构造了8000 多个指令数据形成指令数据集,用于监督微调。 指标:对于医学问答任务,本文引入了一个新的评估指标 SUS。SUS 指标由三个维度组成:安全性 Safety,可用性Usability和流畅性 Smoothness。Safety 评估生成的响应是否有可能误导用户并对他们的健康构成威胁,Usability 评估生成的响应反映医学专业知识的程度,Smoothness 衡量生成的流畅度。 本文构建了一组中文对话场景测试集,同时为了评估模型性能招募了五名具有医学背景的注释员通过SUS维度进行评分。平均SUS分数如下表所示。尽管LLaMA获得了最高的安全分数,但其回答中信息含量较低。本文的华拓模型显着提高了知识的可用性。
Galactica: A Large Language Model for Science http://arxiv.org/abs/2211.09085 本文指出,计算的最初希望是解决科学中的信息过载问题。本文训练了一个大语言模型Galactica,能够更好的自动组织科学知识。Galactica是在人类科学知识的大型语料库上进行训练的,语料库包括4800 万篇论文、教科书和讲义、数百万种化合物和蛋白质、科学网站、百科全书等。 本文提出了一组专门的tokenization用于不同的输入模态。对于引用、氨基酸序列、DNA序列等输入,使用[START_{ }]和[END_{ }]来包装文本。比如,对于引用,使用[START_REF] 和 [END_REF]来包装。本文还引入

本文将prompts与通用语料库一起包含在预训练中,并对Galactica各种科学任务上进行了测试。在医学问答数据集 PubMedQA 上结果为77.6%,在MedMCQA上结果为52.9%,均在当时达到最高水平。
Are Large Language Models Ready for Healthcare? A Comparative Study on Clinical Language Understanding http://arxiv.org/abs/2304.05368 本文在临床语言理解任务上对GPT-3.5、GPT-4 和 Bard 进行了全面评估。任务包括命名实体识别、关系提取、自然语言推理、语义文本相似性、文档分类和问答,并在此过程中提出了一种新颖的提示策略,self-questioning prompting(SQP)。SQP旨在通过鼓励模型更加了解自己的思维过程来提高模型性能,使他们能够更好地理解相关概念从而达到更深入的理解。下图是 SQP 的一般构建过程:
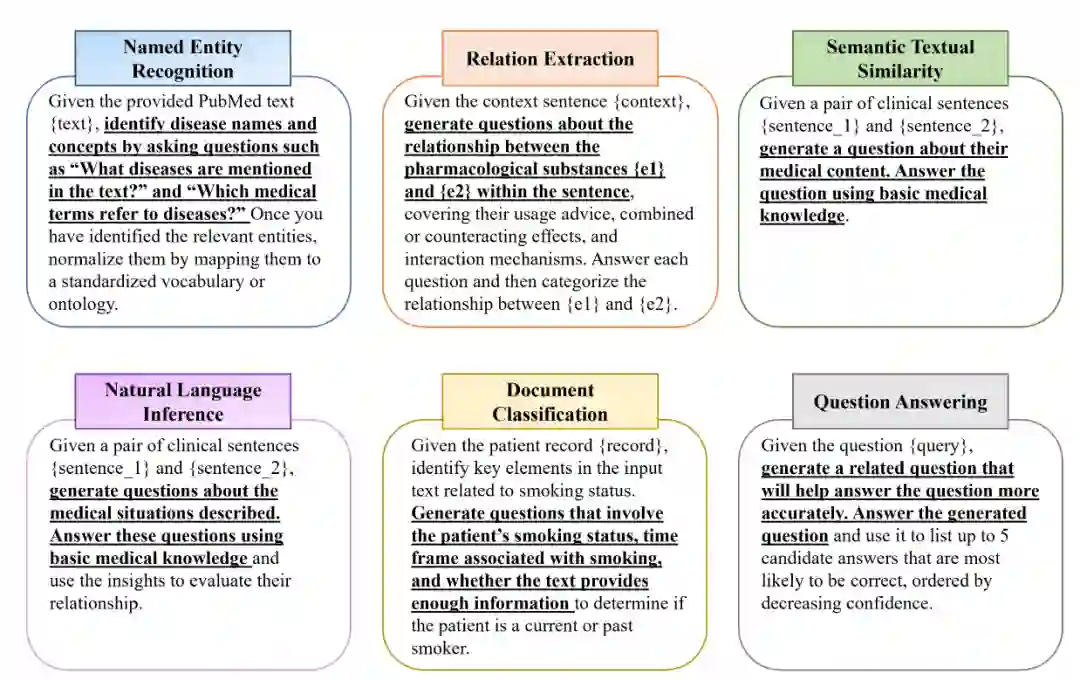
下表将提出的SQP与现有的提示方法进行了比较,突出显示了各自的指导方针和目的。
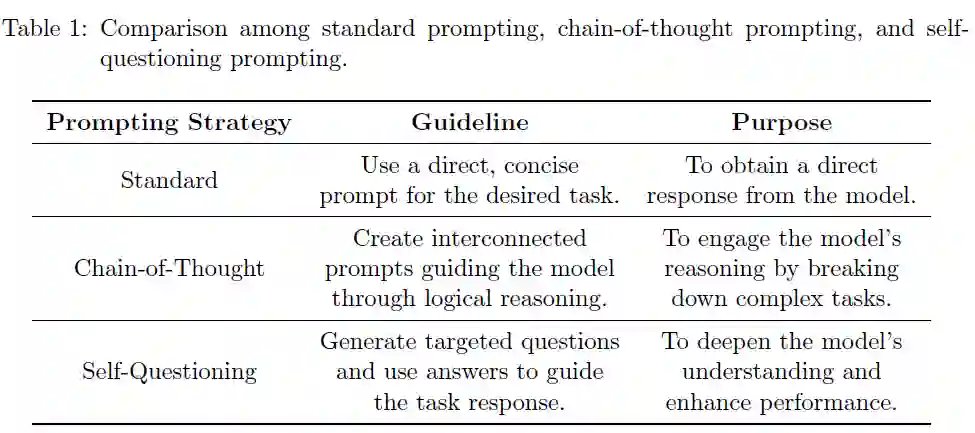
下面展示了六个任务的SQP模板,每个模板中突出显示了核心的自我提问过程。这些带下划线和粗体的部分说明了 SQP 如何生成与任务相关的目标问题和答案,从而指导模型的推理。
本文的评估强调了采用特定任务学习策略和提示技术(如 SQP)的重要性,以最大限度地提高 LLM 在医疗保健相关任务中的有效性。实验结果显示 GPT-4 的整体性能更好,5-shot SQP 提示策略更好。 CAN LARGE LANGUAGE MODELS REASON ABOUT MEDICAL QUESTIONS? http://arxiv.org/abs/2207.08143 本文主要测试 GPT-3.5(Codex 和 InstructGPT)是否可用于回答和推理基于现实世界的困难问题,即医学问题。主使用两个多项选择的医学考试问题和一个医学阅读理解数据集进行测试。本文研究了多种提示场景:CoT、zero- and few-shot和retrieval augmentation。

Retrieval augmentation探究了将模型与额外的上下文联系起来是否可以提高回答的准确性,使用BM25检索器和维基百科作为知识库。给定一个问题 、一个答案选项 ,对文章 进行检索:
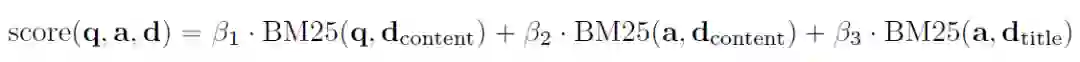
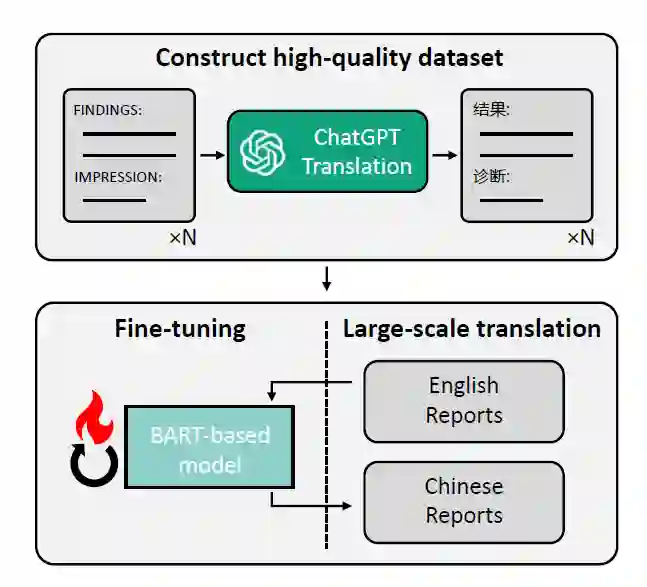
DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task http://arxiv.org/abs/2304.01097 本文在ChatGLM的基础上构造中文的医学模型。 数据集构建:通过翻译 ChatDoctor的数据集来利用英文的高质量数据集。考虑到专业的大规模翻译代价较高,这里作者通过利用 ChatGPT 来采用一种简单且低成本的方法进行大规模翻译。首先构建高质量数据集:通过ChatGPT翻译选取的示例;然后使用这部分数据配对的中英文数据微调一个语言模型(如BART-based model),该语言模型就能获得专家级的知识并作为大语言模型的一个替代从而降低大规模翻译成本。对于疾病数据库里的知识,作者也利用 ChatGPT来构造指令数据。
Prompt Designer:为了得到更加可靠的模型输出,本文利用Prompt Designer来预处理用户输入。Prompt Designer首先从输入中提取相关关键字,如疾病名称或症状,然后使用疾病名称作为标签并根据疾病知识库生成简短描述。Prompt Designer的输出包括有关疾病症状、诊断、治疗方案和预防措施的信息。然后将这部分输出作为DoctorGLM输入的Info {...}部分。通过提供专业生成的提示,提示设计者扩展了DoctorGLM针对特定疾病的专业知识和可靠性。
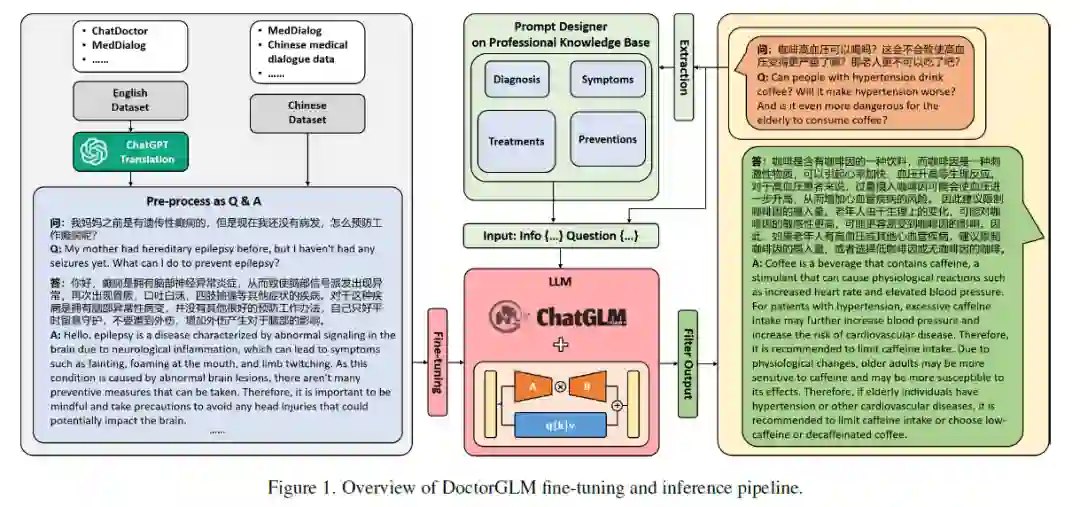
Visual Med-Alpaca: A Parameter-Efficient Biomedical LLM with Visual Capabilities 本文提出Visual Med-Alpaca,是一个开源的、参数高效的生物医学基础模型,可以与医学“视觉专家”集成以进行多模态生物医学任务。该模型建立在LLaMa-7B架构上,使用由GPT-3.5-Turbo和人类专家协作策划的指令集进行训练。利用几个小时的指令调整和即插即用的视觉模块,Visual Med-Alpaca 可以执行各种医学任务。 数据集构建:从 BigBIO 存储库中的各种医学数据集中提取医学问题,然后提示 GPT-3.5-Turbo 合成这些问题的答案,之后执行多轮人工过滤和编辑来优化问答对,从而产生包含 54k 指令的高质量指令集。 视觉模态:Visual Med-Alpaca 支持两个不同的视觉expert:Med-GIT 和 DePlot。Med-GIT 是一个用于图像到文本生成的模型,这里使用 ROCO 数据集进行微调,以促进专门的放射学图像字幕生成。DePlot可以将图形或图表的图像转换为表格,其输出可以直接用于提示预训练的大型语言模型。 由于基础模型提供了一个模块化且适应性强的框架用于整合各种视觉模块,在此框架内,任何多模态的任务都可可以分为两个基本阶段:图像到文本的转换和基于文本的推理。在本文中,视觉专家(即视觉基础模型)将医学图像转换为中间文本表示,然后将转换后的数据用于提示预训练的 LLM,利用 LLM 固有的推理能力来生成适当的响应。 Visual Med-Alpaca 通过提示增强方法连接了文本和视觉模态。首先,图像输入被送入类型分类器,选择对应的视觉模型后得到文本输出,然后将其附加到文本输入以用于后续推理过程。然后,prompt manager将从图像和文本输入中提取的文本信息合并到 Med-Alpaca 的prompt中,之后再进行文本的推理产生输出。
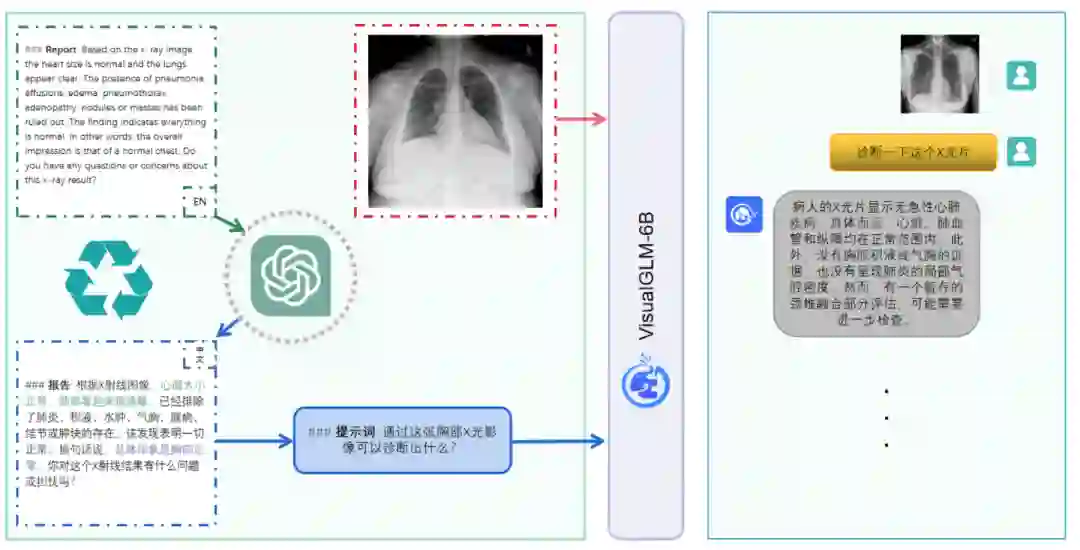
XrayGLM: The first Chinese Medical Multimodal Model that Chest Radiographs Summarization
最近,大型通用语言模型取得了显著的成功,能够遵循指令并生成与人类类似的回应。这种成功在一定程度上推动了多模态大模型的研究和发展,例如MiniGPT-4等。然而,这些多模态模型在医学领域的研究中很少见,虽然visual-med-alpaca在医学多模态模型方面取得了一些有成效的工作,但其数据仅限于英文诊断报告,对于推动中文医学多模态模型的研究和发展并不利。因此,为了解决这个问题,本文开发了XrayGLM模型。 本文借助ChatGPT和公开的胸片图文对数据集,构造了中文的X光片-诊断报告数据集,并使用该数据集在 VisualGLM-6B上进行微调训练。
总结:现有的大语言模型在医学方面的工作集中在评测、微调、多语言、多模态、数据集构建等方面,仍然处于探索和初步阶段,医学领域的安全性问题更加重要,交互式医学系统还需要进一步发展和完善。

