
© 作者|王禹淏
机构|中国人民大学研究方向|自然语言处理 引言:最近,大型语言模型(LLM)在解决知识密集型任务展现出强大的性能。然而,目前尚不清楚LLM对其知识边界的感知能力,以及引入检索增强后会对上述能力有何影响。对此,我们小组的最新工作,初步分析了LLM在开放域问答任务上的性能、感知其知识边界的能力,并研究了引入检索增强后如何影响上述能力。研究 主要回答了以下三个问题: * LLM感知其事实知识边界的能力如何? * 检索增强对LLM有什么影响? * 具有不同特征的辅助文档如何影响LLM?
我们的论文可参考以下链接: 论文链接:http://arxiv.org/abs/2307.11019 开源项目:https://github.com/RUCAIBox/LLM-Knowledge-Boundary

一、简介
通常而言,开放领域问答任务要求模型利用外部文本语料库,通过信息检索系统获得相关文档并生成答案。最近兴起的LLM,由于其已经在参数中编码大量的世界知识,可以直接完成一些开放领域问答任务。目前,领域内缺乏对LLM事实知识边界的深入了解。LLM能否较好地完成开放领域问答问题?LLM是否知道自身的事实知识边界?针对已有的回答,LLM能否准确判断答案的正误?在引入检索增强后,LLM的上述性能有何变化?提供不同质量的参考文档会对LLM生成结果带来怎样的影响? 我们将深入分析检索增强对LLM生成质量的影响,尤其是LLM的问答性能和对其事实知识边界的感知能力。为了衡量LLM感知知识边界的能力,我们使用两种方法:一种是先验判断,引导LLM判断能否准确回答;另一种是后验判断,令LLM评估已有回答是否正确。同时,我们利用多种检索模型为LLM提供辅助文档,包括稀疏检索、稠密检索,以及LLM仅使用自身知识生成的文档。通过精心设计的提示,LLM能够参考给定的辅助文档作出反馈。 本文依据GPT系列的LLM展开研究,主要结论为: * LLM对事实知识边界的感知是不准确的,并对自身结果过度自信。 * LLM不能充分利用它们所拥有的知识,而检索增强可以一定程度上弥补这一缺陷。 * 提供高质量的辅助文档时,LLM性能更佳且更加自信;LLM倾向于依赖所提供的辅助文档生成反馈。辅助文档与问题的相关性越强,LLM越自信,也更加依赖辅助文档。
二、实验设置
开放域问答的任务是指:给定自然语言中的问题和维基百科等大型文档集,模型需要使用所提供的语料库生成答案。在过去的研究中,通常先通过检索模型获得相关的辅助文档,再通过阅读模型提取答案。在LLM时代,LLM可以使用输入提示,以端到端的方式直接解决开放域问答任务:。当引入检索增强辅助LLM生成时,一个典型的方法是设计合适的指令格式,引导LLM依据检索模型获得的辅助文档来生成答案:。
2.1 任务形式
基于上述任务,我们主要设计了三个任务:问答任务(QA),先验判断(Priori judgement),及后验判断(Posteriori judgement)。前者用于评估LLM的开放领域问答能力,而后两者用于评估LLM感知自身知识边界的能力。图1展示了提示及对应的任务。
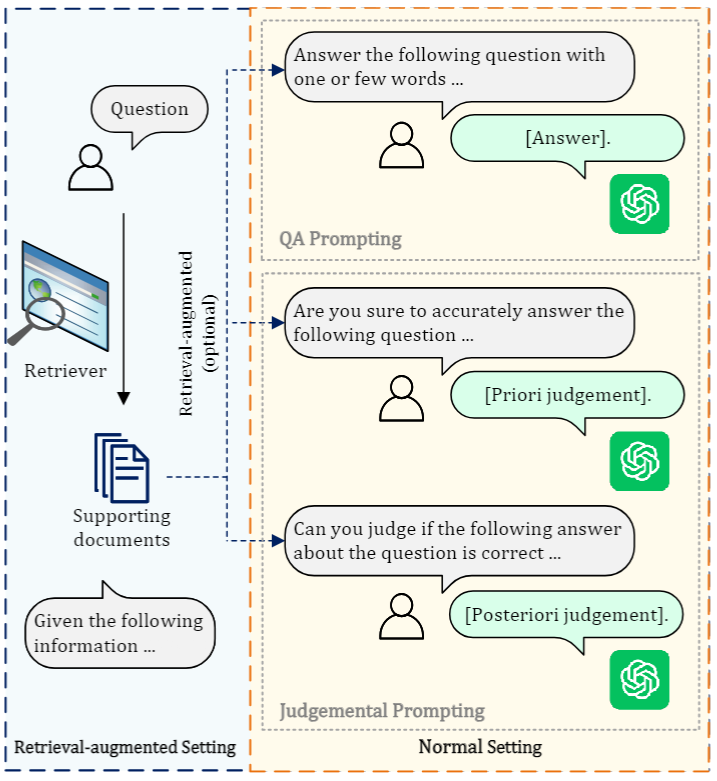
图1 实验设置及提示示意图 问答任务。在问答任务中,我们通过设计合适的问答提示,引导LLM顺从地回答问题,以评估其问答能力。其中包括LLM直接回答和LLM借助参考文档回答两种任务。在评估指标方面,我们使用Exact Match(EM)和 F1 来汇报模型性能。 先验判断。要求LLM判断它们是否能够提供问题的答案。我们引导LLM基于已有的自身知识或结合参考文档,判断其能否回答问题。并结合其问答任务上的回答结果,获得其先验放弃作答的可靠性。 后验判断。要求LLM判断给定的答案是否正确。我们引导LLM基于自身知识或结合参考文档,判断其自身作答结果是否正确。通过答案本身是否正确,获得其后验评估的准确性。
2.2 参考文档
实验中,我们主要在提供无参考文档、稀疏检索结果、稠密检索结果、稠密+稀疏检索结果以及LLM利用其自身知识生成的文档的情况下,完成上述三种任务。特别地,我们还基于稠密检索模型的检索结果,筛选出正类文档、强相关负类文档、弱相关负类文档,以及从语料库随机获得的随机负类文档,来更好地研究引入检索对模型生成的影响。图1展示了常规设置及检索增强下的实验设置。
2.3 设置细节
本文以GPT系列的LLM:Davinci003(text-davinci-003)和ChatGPT(gpt-3.5-turbo)作为研究对象;分别在Natural Questions,TriviaQA和HotpotQA上展开实验;稀疏检索模型选择BM25,稠密检索模型选择使用没有重排序的RocketQAv2,我们选择使用ChatGPT依据问题生成辅助文档作为LLM生成的辅助文档;选择检索结果中的前10个文档作为参考文档。具体实验细节详见论文。
三、实验结果分析
实验结果分析部分,我们继续围绕先前提出的三个问题展开:LLM感知其事实知识边界的能力如何、检索增强对LLM有什么影响、具有不同特征的辅助文档如何影响LLM。
3.1 LLM感知其事实知识边界的能力如何?
为了回答这个问题,我们依然从问答任务、先验判断、后验判断三个维度分析,并分别通过:问答任务准确性、先验判断的可靠性以及后验判断的准确率来衡量。 结论1:LLM对其事实知识边界的感知不准确,并对自身结果过度自信。在表1中,我们发现,与之前的研究类似,即使在没有辅助文档的情况下,LLM仍然有较强的问答能力。 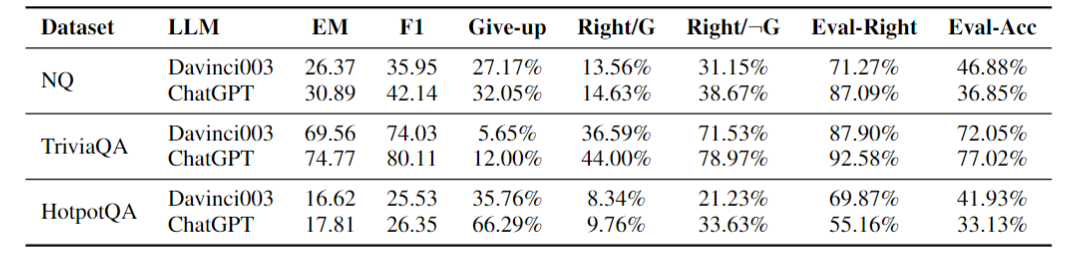
3.2 检索增强对LLM有什么影响?
通过引入2.2节提到的各类参考文档,我们进行了问答实验,评估LLM在引入检索增强后的问答能力;与此同时,我们也引导LLM借助辅助文档,同样进行先验和后验判断。 结论2:LLM不能充分利用它们所拥有的知识,而检索增强可以一定程度上弥补这一缺陷。
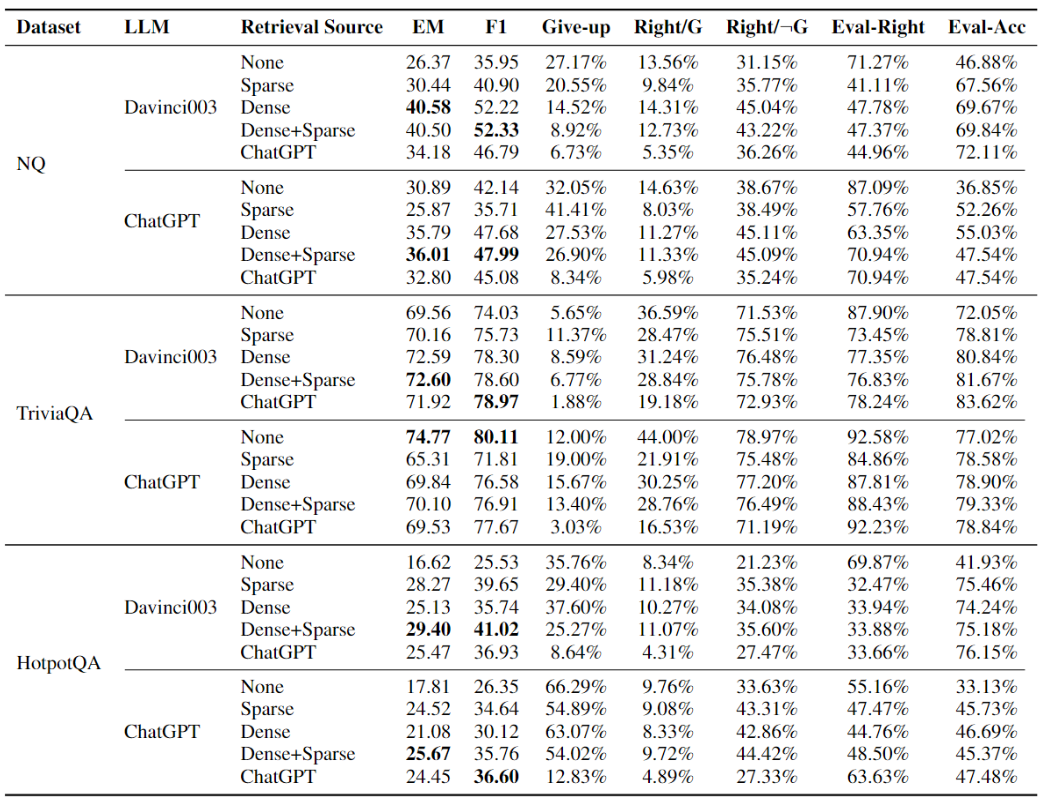
表2 引入检索增强后,LLM在三个数据集上的表现 在表2中,我们比较了利用不同检索模型获得的辅助文档对LLM生成结果的影响。可以观察到,在大多数情况下,提供辅助文档时的性能优于无参考文档时,并且将稠密和稀疏检索的检索结果组合为辅助文档(dense+sparse)通常会获得最佳性能。此外,尽管LLM在预训练期间从包括维基百科在内的现有语料库中学习了大量知识,向他们提供维基百科的辅助文档仍可以提升其的问答能力。这样表明LLM无法有效地利用他们的知识。Davinci003通过引入检索增强的性能改进大大超过了ChatGPT。我们猜测,这种差异可能归因于与Davinci003相比,ChatGPT理解长文本输入的能力较弱。同时,我们观察到,即使在整个过程中没有访问额外的语料库的情况下,使用ChatGPT获取辅助文档仍能提升模型性能。我们将这种方法视为思维链方法(CoT),它首先引导LLM生成包含相关知识的文档,再从中提取信息,获得最终答案。 我们还观察到,在TriviaQA上引入辅助文档时,ChatGPT的性能有所下降。为了调查原因,我们检查了ChatGPT引入参考文档后将答案改错的情况。据观察,这些案例中有很大一部分是由于ChatGPT从辅助文档中提取了错误的答案。鉴于ChatGPT在无参考文档设置下,即可在TriviaQA上的表现出较好的性能,我们认为多个辅助文档可能会引入显著的噪声,这也在一定程度上限制了检索增强对LLM问答性能提升效果。 结论3:检索增强提高了LLM感知其事实知识边界的能力。 从表2中,我们发现在提供了稀疏或稠密检索模型的辅助文档后,LLM自我评估的准确性有所提高。具体而言,Right/G显著增加,Right/G由于问答性能的显著提高而减少或略有增加。结果表明,检索增强后,LLM的先验判断更加准确。此外,Eval-Right显著降低,这与实际精度更加一致,因而Eval-Acc显著提升。结果表明,检索增强还可以提高LLM后验判断的准确性。 为了进一步验证其感知事实知识边界的能力提升,我们利用先验判断确定是否引入检索增强。具体来说,给定一个问题,若LLM放弃在无参考文档情况下回答,则会引入相关文档来生成答案;同样,如果LLM在检索增强设置下放弃回答某个问题,则应在没有辅助文档的情况下回答该问题。我们在ChatGPT上进行了实验,使用了来自稠密检索模型的辅助文档。
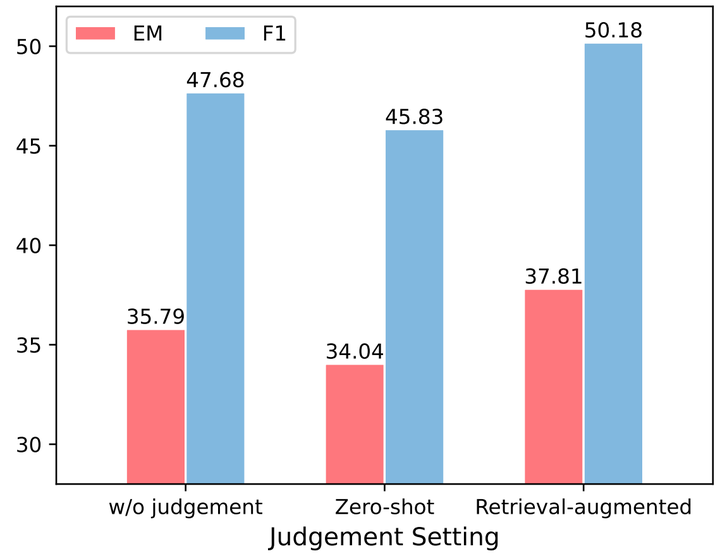
图2 不同的策略下,根据判断结果动态引入检索增强的结果 图2比较了在不同的策略下,根据判断结果动态引入检索增强的结果。我们设置基线为无条件引入检索结果时模型的性能(w/o judgement)。如使用没有参考文档辅助的先验判断进行决策(Zero-shot),与基线相比,回答准确性往往较低。而使用引入辅助文档判断时(Retrieval-augmented),准确性超过了总是引入检索增强的基线。这一结果表明,在检索增强的设置下,根据LLM的先验判断,动态引入LLM的辅助文档来提供答案是有效的。这也进一步表明,检索增强可以提高LLM对其知识边界的认识。
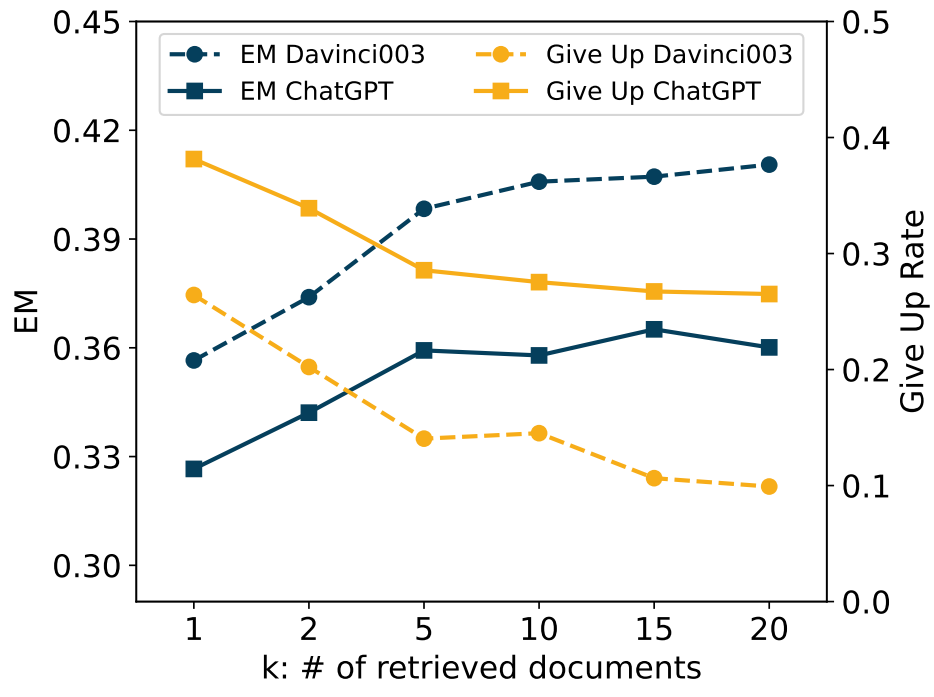
图3 辅助文档数量对检索增强LLM性能的影响 在图3中,我们展示了辅助文档数量变化对检索增强LLM性能的影响。结果表明,随着辅助文档数量的增加,我们观察到问答性能持续改善、LLM放弃率持续下降(变得更加自信),这种趋势随着辅助文档的数量的增加而逐渐放缓。我们还观察到,辅助文档数量的增加所带来的改进并不能归因于召回率的提升。由于即使辅助都是正类文档,提升辅助文档数量仍然会提升回答准确率。此外,LLM似乎对辅助文档的排序不敏感,因此即使辅助文档被颠倒或打乱,性能也不会受到影响。 结论4:检索增强可以改变LLM对不同问题类别的偏好。
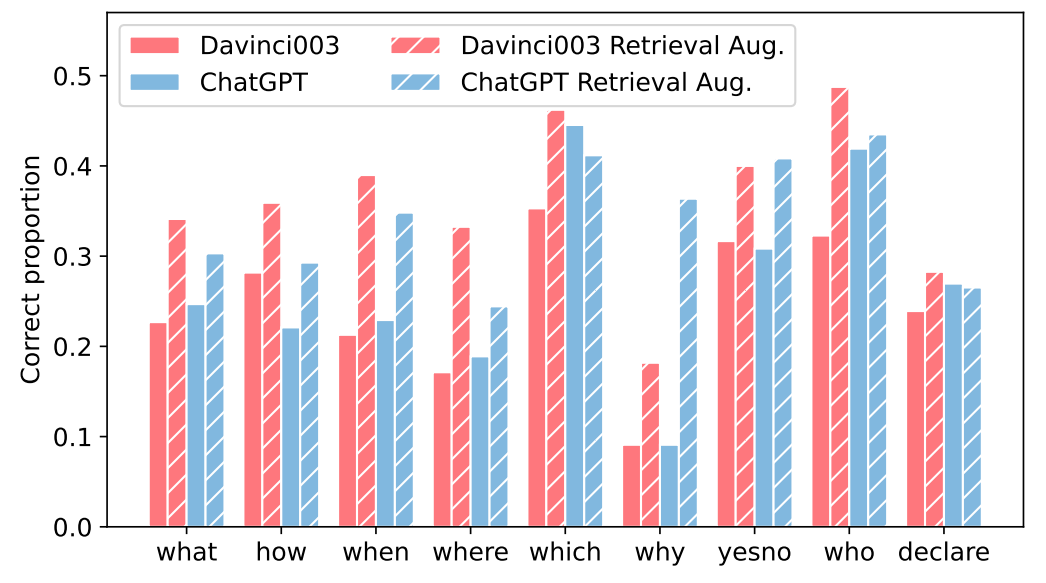
图4 在两种问答设置下,LLM在不同问题类别中正确回答的比例 为了研究LLM处理不同特征问题的倾向,我们分别计算了LLM在不同问题类别中的回答准确性。如图4所示,我们可以看到,LLM在处理“which”类别的问题时达到了最高的准确性,表明这类问题可能是LLM的强项。另一方面,LLM可能不足以满足知识密集型场景中“why”的问题类型。引入检索增强后,LLM的偏好发生了变化。LLM的总体回答准确率得到了提高,并且大多数类别的准确率成比例地增加。特别是,LLM在问题类型“who”上表现最好。然而,对于属于“where”和“declare”类别的问题,ChatGPT的准确性会下降。这表明检索增强不能有效地增强ChatGPT回答此类问题的能力。相比之下,Davinci003在所有类别的问题中都表现出了改进的准确性,展示了其利用检索增强的卓越能力。
3.3 具有不同特征的辅助文档如何影响LLM?
我们已经探讨了检索增强对LLM的性能和知识边界的影响。通常,检索结果由具有不同特征的文档组成,这可能导致不同的检索增强效果。为此,我们继续研究辅助文档的不同特征如何影响LLM。在我们的实验中,我们通过以下因素来描述文档特征:包括文档和问题之间的相关性、文档中是否存在答案以及正例文档的数量和比例。 结论5:当提供更高质量的辅助文档时,LLM在问答和知识边界感知方面表现出更强的能力。 我们采用2.2节中的策略为每个问题生成五种类型的辅助文档,表3显示了Davinci003和ChatGPT的结果。我们可以看到,与使用检索结果作为辅助文档相比,使用高质量文档作为辅助文档会产生更好的性能。然而,如果使用低质量的文档作为辅助文档,包括强相关的负类文档、弱相关的负类文档和随机负类文档,则LLM的性能将劣于使用检索结果作为辅助文档。
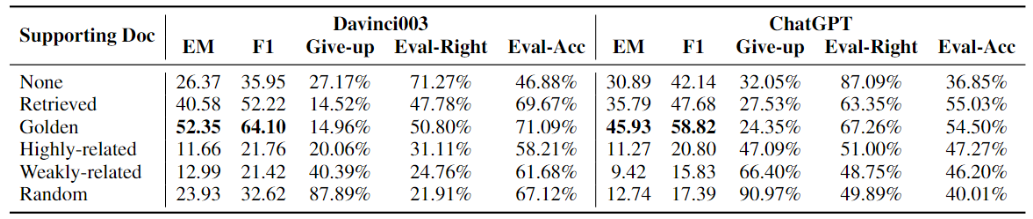
表3 在NQ数据集上使用不同质量辅助文档的生成结果 此外,LLM的放弃率随着辅助文档质量的提高而降低,这表明当使用高质量的辅助文档进行增强时,LLM更加自信。有了更高质量的辅助文档,LLM的Eval-Acc就会增加,这表明LLM在感知其知识边界方面表现出更高的准确性。 结论6:LLM倾向于依靠给定的辅助文档来回答。 基于上述观察,当LLM使用低质量的辅助文档生成反馈时,其性能不如基于其自身知识生成响应。这种现象表明LLM在生成过程中严重依赖于给定的支持文档。我们还努力用更详细的提示来指导LLM,使他们能够在支持文档质量较差的情况下在不增加检索的情况下回答。然而,这种尝试并没有带来任何明显的提升。 结论7:LLM的自信程度和对辅助文档的依赖程度取决于问题与辅助文档之间的相关性。 根据辅助的获得方法,不同文档和问题之间的相关性可以高到低依次按以下顺序排列:正例文档>稠密检索文档>强相关负例文档>弱相关负例文档>随机负例文档。在表3中,我们观察到LLM的相关性和置信度之间存在明显的反比关系(即放弃回答并评估其答案正确的比率)。此外,使用与问题无关的随机负类文档作为辅助文档的效果优于使用相关性更高的负类文档(即强相关/弱相关的负类文档)。这一观察结果进一步表明,LLM在生成反馈时更关注相关文档。
四、总结
本文研究了LLM在开放领域问答上通过检索增强对事实知识边界的感知能力。我们提出了先验和后验判断,除了问答外,还进行了检索增强评估。我们得出了几个主要结论: * LLM对自己回答问题的能力和答案的质量表现出盲目的信心,表明他们无法准确地感知自己的事实知识边界; * LLM无法充分利用他们所拥有的知识,并且检索增强的结合有效地增强了他们感知事实知识边界的能力,从而提高了判断能力。 * LLM在回答问题时往往严重依赖给定的检索结果,而支持文档的特征显著影响了他们的依赖性。
根据这些发现,我们采用了一种简单的方法:该方法不再一味地使用辅助文档,而是基于先验判断动态地引入检索。经验证该方法很好地提升了性能。
