

本多模态大型语言模型(MLLMs)的综述和应用指南探讨了MLLMs这一快速发展的领域,深入分析了其架构、应用及其对人工智能和生成模型的影响。首先介绍了基础概念,详细阐述了MLLMs如何整合多种数据类型,包括文本、图像、视频和音频,以实现复杂的跨模态理解和生成能力的AI系统。内容涵盖了训练方法、架构组成以及在各个领域中的实际应用,如视觉故事讲述和增强无障碍访问。通过详细的案例研究和技术分析,本书考察了当前重要的MLLM实现方案,同时关注在扩展性、稳健性和跨模态学习方面的关键挑战。最后,对伦理问题、负责任的AI开发和未来发展方向进行了讨论。这本权威资源既提供了理论框架,也带来了实际见解,为对自然语言处理与计算机视觉交叉领域感兴趣的研究人员、从业者和学生提供了平衡的视角,对MLLMs的开发和部署中的机遇与挑战进行了全面的阐述。
1.1 MLLMs的定义与重要性
多模态大型语言模型(MLLMs)代表了人工智能(AI)领域的一项重要进化,使得对多种输入类型(如文本、图像、音频和视频)的整合和理解成为可能。不同于仅处理单一输入类型的单模态模型,MLLMs可以同时处理多种模态,从而提供更全面的理解,反映出真实世界的交互方式。MLLMs的关键特性和重要性包括: 跨模态学习:MLLMs在包含文本、视觉、听觉,有时甚至是传感数据的大规模数据集上进行训练。此功能使其能够在不同模态之间建立联系,从而支持需要跨多种数据类型理解和生成内容的任务。例如: * 文本生成图像:MLLMs能够根据文本描述生成详细图像,革新了图形设计和广告等创意行业。设想描述“黄昏时的未来城市景观”,并让AI生成相应的图像。 * 视觉问答:这些模型可以分析图像并准确回答自然语言问题,增强了教育工具和无障碍技术。例如,MLLM可以回答关于照片内容的问题,如“这张图片中的狗是什么品种?” * 多模态内容创作:MLLMs促进了整合文本、视觉和音频内容的创作,如插画故事或多媒体展示。这可能包括基于简要提示生成具有匹配插图的连贯故事。
统一表示:MLLMs通过统一的编码库和联合嵌入空间,实现了多模态数据的集成表示,从而能够无缝处理不同模态。这种架构设计提供了几项关键能力: * 模态之间的无缝转换(如描述照片或从文本生成图像)。 * 跨模态检索,模型可以根据文本查询找到相关图像,或将声音与视觉内容匹配。 * 提供更自然和直观的人机交互方式。
要理解统一表示,可以想象一个图书馆,其中书籍、图像和音频记录都使用相同的系统进行分类,这样便可以轻松找到跨不同媒体类型的相关内容。 增强的上下文理解:通过整合多种模态,MLLMs能够生成更准确和具备上下文意识的响应。这一能力在以下领域尤为重要: * 医疗:结合医学影像、患者记录和医生笔记以提供更精确的诊断。例如,MLLM可以将患者的X光片、病史和症状结合在一起,提出可能的诊断建议。 * 安防:结合视频监控和音频数据以实现全面的情境感知。这可能涉及分析视频流和音频记录以检测潜在的安全威胁。 * 电子商务:通过理解文本查询和视觉产品特征来增强产品搜索功能。MLLM可以帮助客户找到“蓝色花卉夏季连衣裙”,既理解文本描述,也识别产品的视觉特征。
跨模态的泛化能力:MLLMs展现了在不同模态中处理多种任务的灵活性,包括: * 图像描述生成和视觉问答。 * 跨模态检索和内容生成。 * 音视频整合用于视频字幕或口型同步任务。 * 多模态翻译,例如将视频内容转换为文本摘要。 * 通过同时解读手势、面部表情、语音和文本,提升人机交互体验。
机器人与具身AI的进步:在机器人领域,MLLMs帮助系统更有效地感知和交互环境。通过处理视觉、听觉和传感数据,MLLMs支持的机器人可以执行复杂任务,如物体操作、导航和人机交互。例如,家用机器人可以结合语言理解、视觉识别和空间导航,执行“请从厨房柜台拿来红色杯子”这样的口头指令。 现实应用潜力:MLLMs处理多种数据类型的能力使其在信息形式多样的实际应用中具有重要价值。例如: * 在自动驾驶车辆中,这些模型可以整合来自摄像头的视觉数据与地图和交通报告的文本信息,从而增强导航和安全功能。MLLM可以帮助自动驾驶汽车识别路标、解释其含义并相应调整车辆行为。 * 在科学研究中,MLLMs可以同时分析分子结构、研究论文和实验数据,以识别潜在的新药物化合物。这将通过识别人工可能忽略的跨多数据集模式,加速寻找新疗法的过程。
弥合AI与人类认知之间的差距:MLLMs处理多模态数据的能力更贴近人类的认知过程,优于单模态模型。这种与人类认知的契合有助于构建更直观、能够理解复杂上下文的AI系统。例如,基于MLLM的虚拟助手可以根据用户的语气、面部表情和用词选择来理解和回应用户的情绪,就像人类一样。
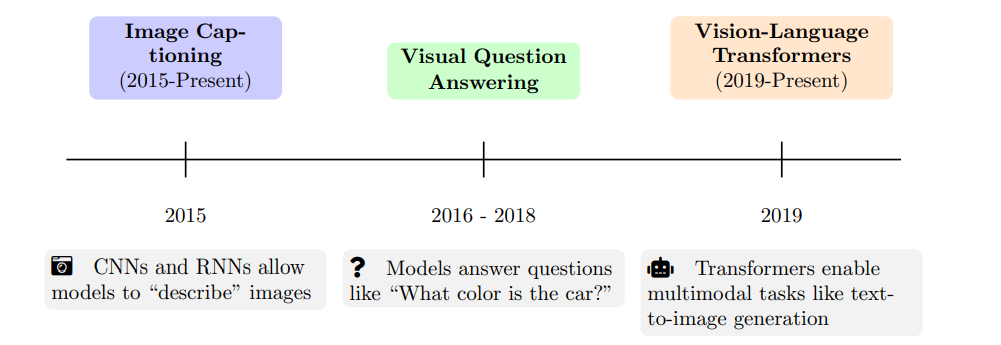
1.2 自然语言处理(NLP)与计算机视觉的融合:MLLMs的崛起
自然语言处理(NLP)和计算机视觉的融合彻底改变了AI的发展,催生了多模态大型语言模型(MLLMs)。这种融合使机器能够跨模态进行推理,从而对世界有更全面的理解。 关键历史里程碑: * 图像描述生成(2015至今):早期模型如“Show, Attend, and Tell”将卷积神经网络(CNN)用于图像分析,并结合循环神经网络(RNN)生成文本。这标志着机器能够“描述”它们“看到”的内容的开端。 * 视觉问答(VQA):这些任务要求模型结合视觉和文本输入生成有意义的答案。例如,模型可能被问到“汽车是什么颜色?”并看到一张红色汽车的图片。 * 视觉-语言Transformer(2019至今):诸如ViLBERT、CLIP和DALLE的模型展示了Transformer架构可以扩展到多模态应用。这些模型能够执行从文本描述生成图像或从文本查询找到相关图像等任务。
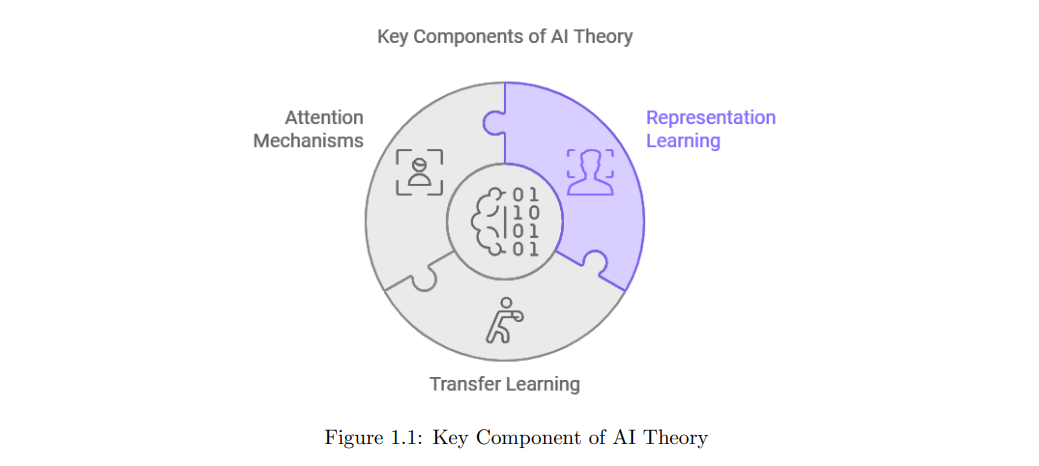
理论基础:NLP和计算机视觉的融合基于以下几个关键理论基础: * 表示学习:这使MLLMs能够创建跨模态的联合嵌入,捕捉语义关系。简而言之,它使模型能够理解语言中的概念与视觉元素的关系。例如,模型会学习到“猫”这个词与胡须、尖耳朵和毛茸茸的身体等视觉特征相关联。 * 迁移学习:这种技术使模型能够将从一项任务中获得的知识应用于新的相关任务。对于MLLMs,这意味着它们可以利用从大数据集获得的通用知识,以最少的额外训练在特定任务中表现良好。类似于人类会将骑自行车的平衡和协调技能应用于学习骑摩托车。 * 注意力机制:最初为NLP开发的注意力机制使模型能够关注输入的相关部分。在MLLMs中,这种机制扩展为关注不同模态中的相关方面,使多模态数据的处理更加有效。可以将其类比为人在嘈杂环境中听懂讲话者的声音时集中注意力在说话者嘴唇上的过程。
架构创新:几项关键的架构创新推动了MLLMs的发展: * 编码器-解码器框架:此架构用于诸如DALL-E等模型,允许文本和图像域之间的映射。编码器处理输入(如文本),解码器生成输出(如图像)。类似于一个将文字故事转换为绘画的翻译者。 * 跨模态Transformer:这些模型为每种模态使用单独的Transformer,并通过跨模态注意力层融合信息。模型可以先分别处理文本和图像,然后将信息结合起来。这类似于人们先阅读书籍再看插图,然后结合这些信息以更全面地理解。 * 视觉Transformer(ViT):这些将Transformer架构直接应用于图像块,使视觉和语言模型的整合更加无缝。ViT将图像分解为较小的块并依次处理,类似于Transformer处理句子中的单词。
对AI应用的影响:NLP和计算机视觉的融合使得MLLMs在各种AI应用中展现了新能力: * 多模态聊天机器人,可以理解和生成文本和图像。例如,一个客户服务机器人能够理解产品图片,并提供文字解释和视觉辅助。 * 内容审核系统能够同时分析文本和图像,为社交媒体平台提供更具上下文意识的不当内容过滤。 * 为视障用户生成图像描述的无障碍工具,使他们通过详细的文字描述“看到”图像。 * 增强自动驾驶系统中的人机交互,车辆能够理解来自环境的语言命令和视觉提示。
挑战与未来方向:尽管MLLMs取得了显著进展,仍然面临一些挑战: * 偏见与公平性:MLLMs可能会延续或放大训练数据中存在的偏见,特别是在文本和视觉域中。例如,由于训练数据不平衡,它们可能在图像识别中错误地识别个体。解决此问题需要仔细的数据集筛选、多样化的数据表示,以及对模型输出的持续监控和调整。研究人员正在探索对抗去偏技术和公平性学习等方法来缓解这些问题。 * 可解释性:理解MLLMs如何在不同模态间进行决策对于建立信任至关重要。这涉及开发解释模型决策的技术,创建能够有效表示不同模态在模型推理过程中的相互作用的可视化工具。例如,注意力可视化和显著性映射等技术正被应用于多模态环境,以提供对模型决策过程的洞察。 * 效率:当前MLLMs通常需要大量计算资源。研究者正在积极研究更高效的架构和训练方法。潜在的解决方案包括:
模型剪枝:删除不必要的参数,创建更小、更快的模型,同时性能损失较小。 * 知识蒸馏:创建较小的模型模仿较大模型的行为,类似于学生从老师那里学习。 * 量化:减少模型参数的精度以降低内存和计算要求。 * 伦理考量:随着MLLMs变得更强大,一些伦理挑战出现了:
与多模态个人数据的处理和潜在滥用相关的隐私问题。研究人员正在探索如联邦学习和差分隐私等隐私保护技术来应对这些问题。 * 对透明决策过程的需求,特别是在医疗和自动化系统等关键应用中。这涉及开发可解释的AI技术,提供清晰的MLLM决策理由。 * 可能用于创建深度伪造或其他误导性内容,混合操控文本和图像。为此,正在开发对抗合成媒体的检测系统,并建立关于MLLMs在内容创作中使用的伦理准则。 * 跨模态一致性:确保不同模态之间的一致性是一个重大挑战。这包括开发在生成文本和图像之间保持语义一致性的方法,并解决多模态信息整合时可能产生的冲突。研究人员正在探索如一致性正则化和多任务学习等技术,以提高MLLM输出的跨模态一致性。
随着该领域研究的进展,MLLMs在理解和生成跨多模态内容方面的能力将变得更强,这有可能导致AI系统在人类般的世界理解上取得更大进展。MLLMs的持续进步不断推动AI的创新和应用边界,在不同领域中开启了新的发展机遇。
1.3 结论与未来展望
多模态大型语言模型(MLLMs)代表了人工智能技术的重大飞跃,弥合了不同信息处理模式之间的差距,使我们更接近于开发出能够更像人类一样理解和与世界互动的AI系统。MLLMs同时整合和处理多种类型数据的能力,拓展了其在各个行业和领域中的广泛应用前景。 展望未来,MLLMs的潜在影响广泛且具变革性: * 在医疗领域,MLLMs能够通过整合视觉医学数据、文本化的患者病史和最新研究成果,彻底革新诊断和治疗规划。例如,MLLM可以分析患者的MRI扫描、病史和最新的医学文献,以建议个性化的治疗方案。 * 在教育领域,这些模型可以通过根据学生的多模态互动来调整内容,创造更加引人入胜和个性化的学习体验。基于MLLM的辅导系统可以根据学生的口头回应、面部表情和在视觉任务中的表现来调整教学风格。 * 在科学研究中,MLLMs可以通过分析复杂的多模态数据集并识别可能被人类研究者忽略的模式,加速科学发现。例如,在气候科学领域,MLLM可以整合卫星图像、气象数据和科学论文,以识别气候变化中的新模式。 * 在创意产业中,MLLMs可以成为内容创作的强大工具,推动互动性和沉浸式叙事的新形式。设想一款能够根据玩家的行为和偏好生成独特故事情节和视觉内容的视频游戏。
然而,在我们拥抱MLLMs的潜力的同时,也必须警惕其带来的挑战。解决偏见问题、确保道德使用、提高效率和增强可解释性将是充分实现这些强大模型潜力的关键。 对研究人员和实践者的行动呼吁: * 开发强有力的技术来减轻多模态数据集和模型输出中的偏见。 * 创建更高效的MLLM架构,以减少计算需求和环境影响。 * 探索改进MLLM输出的跨模态一致性和连贯性的新方法。 * 研究MLLMs与其他新兴技术(如增强现实和物联网)的集成。 * 制定跨行业开发和部署MLLMs的伦理准则和最佳实践。
MLLMs的发展不仅是技术进步,还代表了我们在人工智能领域方法的根本转变。通过模仿人类处理和整合多种信息类型的能力,MLLMs正使我们更接近于创建真正智能的系统,这些系统能够以更细致全面的方式理解和互动世界。 随着该领域研究的不断发展,我们可以期待更加复杂的MLLMs,它们将进一步突破AI的可能性。未来的道路充满了激动人心的可能性和挑战,而MLLMs的持续发展无疑将在塑造人工智能的未来及其对社会的影响中发挥关键作用。研究人员、从业者和政策制定者有责任以负责任的方式引导这一发展,确保MLLMs的利益得到实现,同时减轻潜在的风险和伦理问题。


