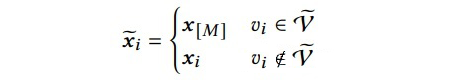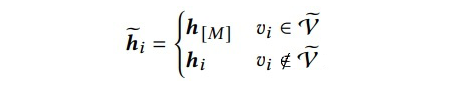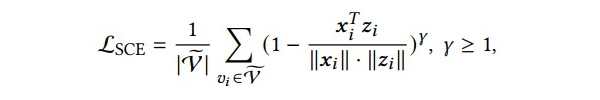![]()
©作者 | 张欣
单位 | 香港理工大学
研究方向 | 图神经网络、自监督学习
![]()
论文标题:
GraphMAE: Self-Supervised Masked Graph Autoencoders
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, Jie Tang
KDD 2022
Background
自监督学习
(Self-supervised Learning SSL)在计算机视觉(CV)和自然语言处理(NLP)中得到了广泛的应用。它一般可分为生成性(generative)方法和对比性(contrastive)方法。对比性 SSL 方法在之前两年很火,比如 MoCo,但生成性 SSL 方法也在稳步提升,比如 NLP 中的 BERT 和 GPT,以及最近在 CV 中出现的 MAE。
然而,在图(graph)的自监督学习领域,对比性 SSL 方法一直在占据主流,特别是在两类重要的下游任务上——节点分类(node classification)和图分类(graph classification)。对比性 SSL 方法的成功在图(graph)上的成功主要建立在相对复杂的训练策略上,比如具有动量更新(momentum updates)和指数移动平均(exponential moving average)的双编码器(bi-encoders)。
此外,负样本(negative samples)对大部分对比性学习(contrastive learning)的目标函数(objective)来说是必须的,但构建负样本(negative samples)通常需要付出大量的成本来取样或从图中构建。最后,对比性 SSL 方法严重依赖于数据增强(data augmentation),但数据增强的有效性在不同的图之间有很大的差异,这会导致对比性 SSL 方法性能的不稳定。
Motivation
自监督图自动编码器(GAE)作为一种生成性 SSL 方法,可以避免在 background 中对比性 SSL 方法中的三个问题,因为它的学习目标(learning objective)是直接重构(reconstruct)输入的图数据。尽管如此,自监督图自动编码器(GAE)的发展一直落后于对比性学习。
到目前为止,还没有一个 GAEs 能超越对比性 SSL 方法的性能,尤其是在节点分类(node classification)和图分类(graph classification)任务上。基于此,这篇文章想要提出一个用于自监督学习的改良版 GAE 模型,使得这个模型的表现可以超过或至少接近于图对比性学习模型。
Challenge
要改良 GAE 并使其的表现超过或至少接近于图对比性学习模型这件事并不容易,这是因为现有的 GAE 模型有以下 4 个问题。
大部分 GAE 模型的学习目标是重构节点与节点间的边(link reconstruction),以此来鼓励邻居节点在拓扑(topological)结构上的紧密性。因此,GAE 通常在链接预测(即预测节点与节点间是否有边 link prediction)和节点聚类(node clustering)方面表现良好,但在节点和图的分类方面的表现却不尽人意。
一些 GAE 模型的学习目标是重构节点的特征,但他们仍然采用原来的结构,这会导致模型只能学到浅薄的结果(即学到的表征趋向相同),导致不稳定。但是在 NLP 领域,去噪的 GAE 会先破坏一部分输入的特征,然后再试图恢复它,使得整体表现相对稳定。这可能也适用于图领域。
尽我们所知,所有利用特征重建作为学习目标的 GAE 都是用 MSE 作为评价标准(criterion)。然而,MSE 会受到不同特征的向量规范和维度的影响,导致自动编码器的训练崩溃。
大部分 GAE 都利用 MLP 作为其解码器(decoder)。由于在图(graph)中,目标大多是信息量较小的特征向量,MLP 作为解码器可能不够强大,无法弥补编码器表示和解码器目标之间的差距。
Method
![]()
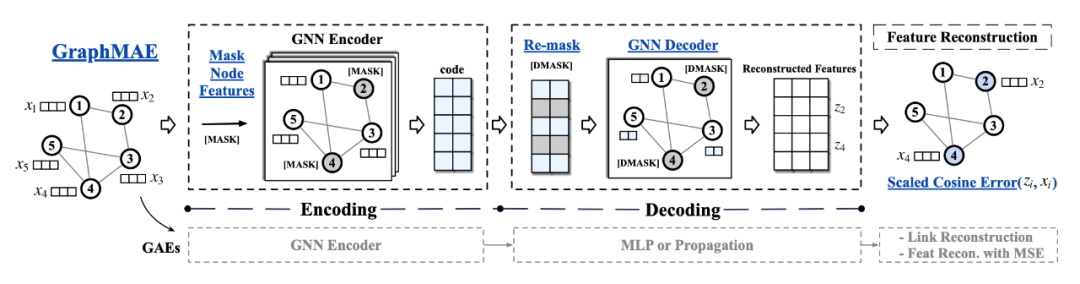
为了缓解现有 GAE 所面临的 4 个问题及使得 GAE 的表现能与对比图学习(contrastive graph learning)的相匹配或超越,这篇文章提出了一个用于自监督学习的屏蔽图自动编码器(masked graph autoencoder)——GraphMAE。GraphMAE 的核心思想在于重建被遮蔽的节点特征(masked node features)。具体来说,GraphMAE 引入了带有二次遮蔽策略(re-mask decoding strategy)的 GNN 作为解码器(decoder),而不是 MLP。
此外,为了训练的稳定,GraphMAE 采用可缩放的余弦误差(scaled cosine error)作为特征重建好坏的标准。
图 1 展示了 GraphMAE 的框架图。以下内容仅对 GraphMAE 进行介绍,对于 GraphMAE 设计的具体原因及相关工作不做赘述,有兴趣的读者可自行阅读全文。
4.1 重建被遮蔽的节点特征
给定一张图
,其中
是节点的集合(node set),
是邻接矩阵(adjacency matrix),
是节点特征矩阵(node feature matrix)。我们抽取一个节点子集
并对子集中每个节点的特征根据掩码(mask token)[MASK] 进行遮蔽。这样一来,对于
在遮蔽的特征矩阵
中的节点特征
可被定义为:
![]()
其中
是可学习的(learnable)。GraphMAE 的目标是在给定
和
的条件下,重构
中被遮蔽掉的那部分节点特征。
GraphMAE 采用无放回的均匀随机采样来抽取屏蔽的节点子集
,这种抽样策略有助于防止潜在的偏差(bias center),即一个节点的邻居既不是全部被掩盖,也不是全部可见。此外,与 CV 中的 MAE 类似,在大部分情况下,一个相对较大的遮蔽率(如 50%)可以减少图中的冗余信息,从而给模型的自监督学习造成一定的挑战来让模型学习到更有意义的节点表征。
4.2 带有二次遮蔽的GNN解码器
解码器(decoder)
将编码器(encoder)
输出的隐编码(latent code)
映射回
。解码器的设计一般取决于目标
的语义水平(semantic level)。目标
含有的语义信息越多(比如
是独热矩阵),解码器(decoder)就可以选取比较简单的模型,如 MLP。目标
含有的语义信息越少,就需要越复杂的解码器(decoder)。
在图(graph)中,解码器重构的是语义信息量相对较少的多维节点特征。传统的 GAE 都采用简单的 MLP 进行解码,表现力较差,导致学习到的隐编码
倾向于与输入特征
几乎一致。所以 GraphMAE 采用了更具表现力的 1 层 GNN 作为其解码器(decoder)。以 GNN 作为解码器可以利用节点的邻居信息来恢复该节点的特征,而不是仅能利用节点本身。这样一来,就可以帮助编码器学习更富有信息量的隐编码
。
为了进一步鼓励编码器(encoder)学习表征,我们提出了一种二次遮蔽策略(re-mask decoding technique)来帮助隐码
进行解码。我们使用另一个掩码(mask token)[DMASK],即解码器的掩码,对隐编码
进行二次遮蔽(mask)。具体来说,对于
在二次遮蔽的隐编码
中的
可被定义为:
![]()
在带有二次遮蔽策略的 GNN 解码器中,被遮蔽的节点被迫从它未被遮蔽邻居节点的隐编码中重构其输入特征。
请注意,解码器只在自监督训练阶段用于执行节点特征重建任务。因此,解码器可使用任何类型的 GNN 模型。
4.3 可缩放的余弦误差
GraphMAE 的目标是重建每个被屏蔽节点的原始特征,但由于节点特征是多维且连续的,使用传统 MSE 作为特征重建好坏的标准并不合适。具体来说,我们在实验中发现 MSE 损失可以最小化到接近零,这不足以进行特征重建。此外,MSE 存在敏感性(sensitivity)和低分离度(low selectivity)的问题。敏感性是指 MSE 对向量范数(vector norms)和维度敏感。某些特征维度的极端值也会导致 MSE 对它们过拟合。低分离度表示 MSE 的分离性不够,无法让 GraphMAE 的重心放在更难学习的样本上。
为了解决敏感性的问题,我们决定使用余弦误差(cosine error)作为重建原始节点特征的标准,从而摆脱了维度和向量范数的影响。余弦误差中的
范数能将向量映射到单位超球面(unit hypersphere),从而大大改善了表示学习(representation learning)的训练稳定性。
为了提高分离度(selectivity),我们引入可伸缩的余弦误差(scaled cosine error SCE)。我们认为,我们可以通过将余弦误差以
的幂数进行缩放,来降低容易学习的样本(easy samples)在训练中的贡献。对于高置信度的预测,其相应的余弦误差通常小于 1。这样一来,当缩放因子(scaling factor)
时,余弦误差会更快地衰减为零。正式来说,给定原始特征
和重建的输出
,SCE 被定义如下:
![]()
缩放因子
是在不同数据集上可调整的一个超参数。这种缩放技术可以被看做是自适应的样本再评估,每个样本的权重随着重建误差而再次调整。
4.4 训练和预测
图 1 总结了 GraphMAE 的整体训练流程。首先,给定一个输入图,我们随机选择一定比例的节点,用掩码 [MASK] 替换其节点特征。然后,我们将遮蔽过特征的图送入编码器(encoder),来生成节点表示/隐编码。在解码的过程中,我们对选定的节点进行重新屏蔽,并用另一个掩码 [DMASK] 替换其特征。最后,解码器被应用于重新屏蔽的图,使用拟议的可缩放得余弦误差作为标准来重建原始的节点特征。
在推理(inference)阶段,编码器被直接应用于输入的图上来生成节点的表征(node embedding)。这个表征可用于各种图学习任务,如节点分类(node classification)和图分类(graph classification)。对于图层面的任务(graph-level task),我们使用非参数化的图池化(pooling)函数,比如 MaxPooling,MeanPooling,来以获得图层面的表示
。
![]()
Experiment
实验部分可分为如下章节,实验设置在这里不过多赘述,有兴趣的读者可以自行阅读全文。
5.1 Node Classification
-
对比性的自监督模型(contrastive self-supervised models):DGI, MVGRL, GRACE, BGRL, InfoGCL,和 CCA-SSG。
-
生成性的自监督模型(generative self-supervised models):GAE, GPT-GNN,和 GATE。
3. 有监督模型(supervised models):GCN 和 GAT。
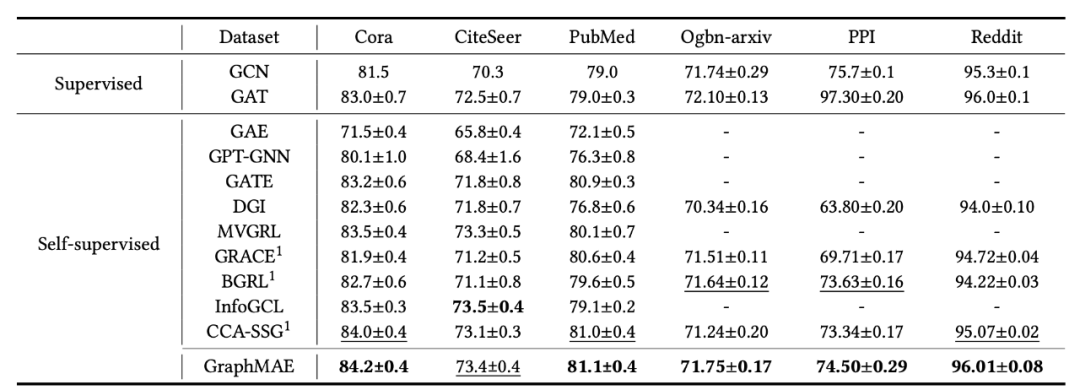
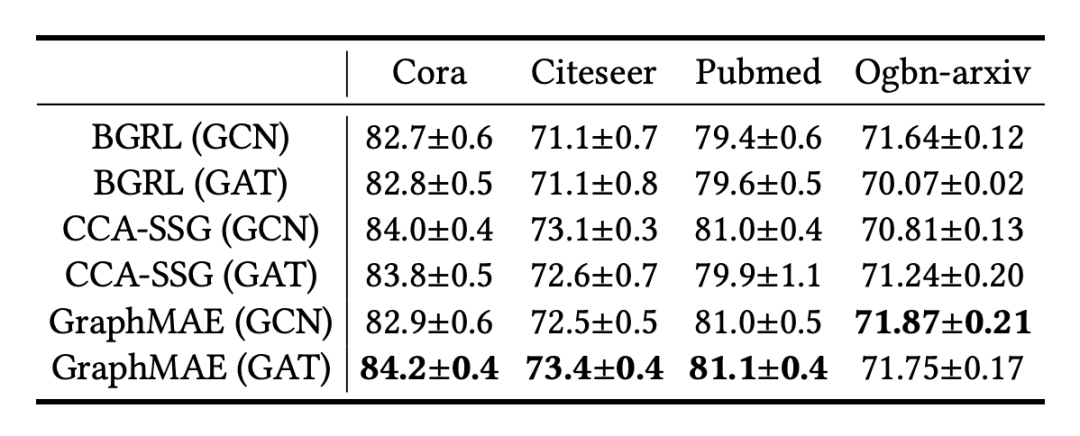
实验结果如表 1 所示,与 SOTA 的自监督模型相比,GraphMAE 在所有的数据集上都取得了最好或相当的(comparable)表现,且 GraphMAE 的表现大大超过了现有的生成性自监督模型。
![]()
▲表1. 节点分类的实验结果。我们汇报了在PPI数据集上的Micro-F1得分及在其他数据集上的分类准确率
5.2 Graph Classification
-
经典的图核模型(graph kernel methods):Weisfeiler-Lehman 子树核(sub-tree kernel WL)和深图核(deep graph kernel DGK)。
-
-
对比性的自监督模型:Infograph, GraphCL, JOAO, GCC, MVGRL 和 InfoGCL。
有监督模型:GIN 和 DiffPool。
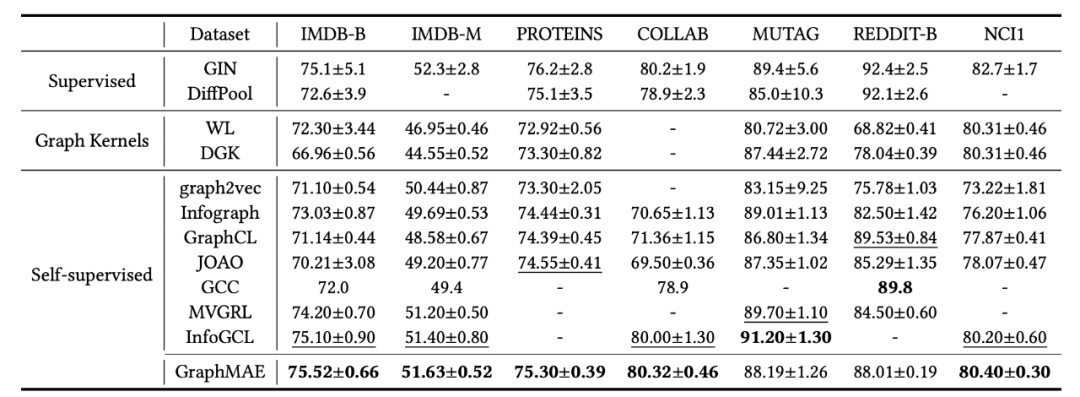
实验结果如表 2 所示,GraphMAE 在 7 个数据集中的 5 个上超过了所有的无监督基线,在另 2 个数据集上也表现相当。这些数据集的节点特征都是独热向量,信息量相对节点分类的数据集较少。GraphMAE 在这些数据集上的较好表现证明了生成式自动编码(generative auto-encoding)可以学习到更有意义的信息,并在图级任务(graph-level tasks)中具有潜力。
![]()
▲表2. 图分类的实验结果。我们汇报了在所有数据集上的分类准确率。
5.3 Transfer Learning
在迁移学习(transfer learning)任务中,基线主要有以下两种:
-
无监督模型:Infomax,AttrMasking 和 ContextPred。
-
对比性的自监督模型:GraphCL,JOAO 和 GraphLoG。
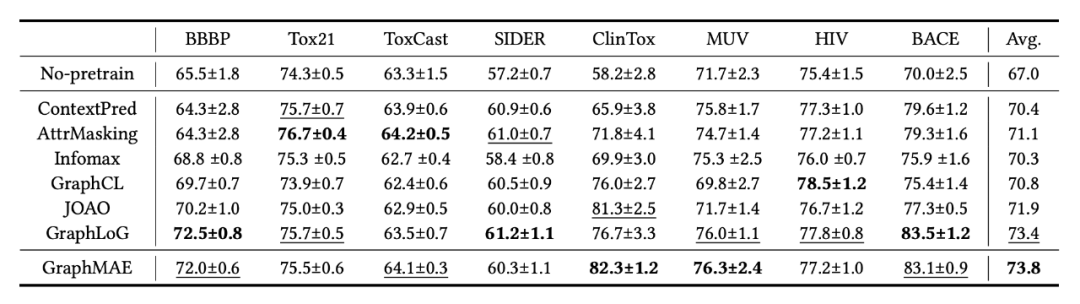
实验结果如表 3 所示,GraphMAE 在迁移学习任务上的表现与基线相当(comparable)。其中,GraphMAE 取得了最好的平均分数,且在 2 个数据集中比基线的最佳结果有小的提升。这证明了 GraphMAE 强大的可迁移性。
![]()
▲表3. 迁移学习的实验结果。我们汇报了在所有数据集上的ROC-AUC得分
5.4 Ablation Studies
为了验证 GraphMAE 主要组成部分的效果,我们进一步进行了一系列的消融研究。实验设置及细节不多做赘述,有兴趣的读者可自行阅读全文。
5.4.1 重建特征标准的影响effect of reconstruction criterion
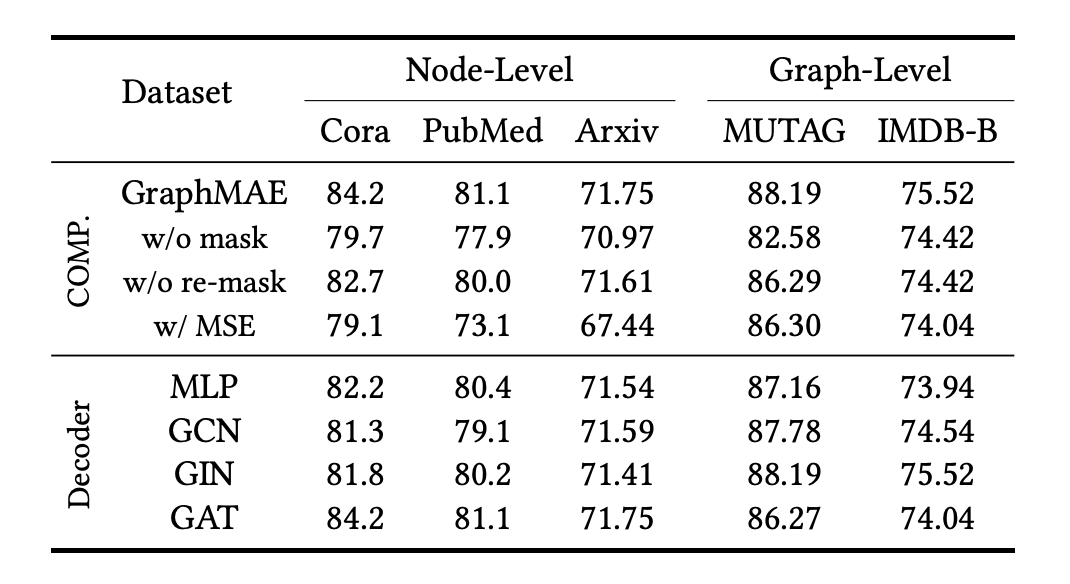
表 4 显示了 MSE 和我们提出的 SCE 损失函数在节点和图层面上的实验结果。实验结果表明,在节点分类任务中,SCE 比 MSE 有明显的优势,表现提升的绝对值为 1.5%~8.0%。在图分类任务中,使用 MSE 或 SCE 都可以提高分类的准确率。总体来说,SCE 比 MSE在节点分类任务上有一定的优势。
![]()
▲表4. 在节点和图层面对解码器类型、二次遮蔽和重建特征的标准进行消融研究。
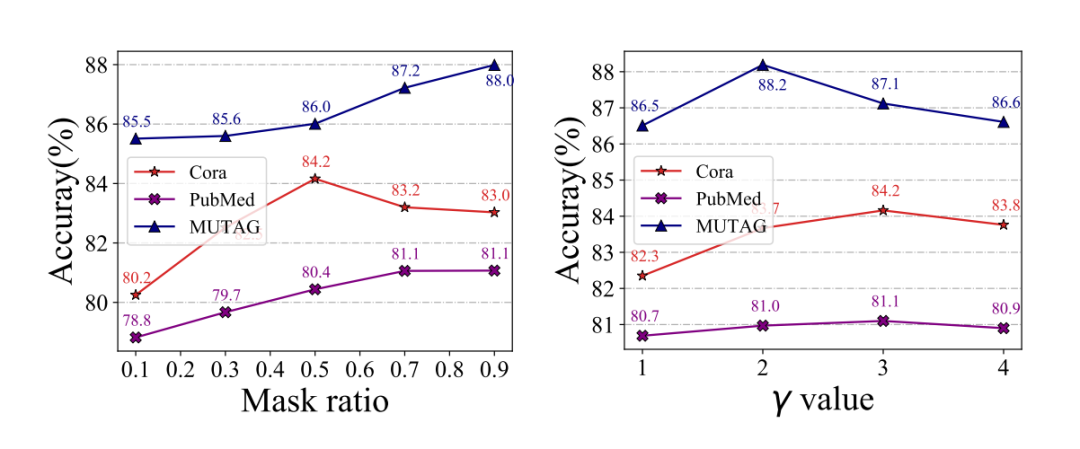
图2展示了缩放系数
对 GraphMAE 表现的影响。实验结果表明,
在大多数情况下有好处,特别是在节点分类中。然而,在 MUTAG 中,较大的
值损害了性能。总体来说,缩放
可以带来改善
。
![]()
▲图2. 遮蔽率和缩放系数的消融研究
5.4.2 Effect of mask and re-mask
遮蔽(masking)在我们的方法中起着重要作用
。GraphMAE 采用了两种遮蔽的策略——在进入编码器前遮蔽输入的特征和在进入解码器前二次遮蔽已编码的特征。表 4 展示了遮蔽对 GraphMAE 表现的影响。我们观察到,如果不对输入的特征进行遮蔽,GraphMAE 的性能会明显下降,这表明对输入的特征进行遮蔽的策略对于避免简单的解法(trivial solution)至关重要。对于二次遮蔽策略,如果没有该操作,GraphMAE 的准确性会下降 0.1%∼1.9%。二次遮蔽策略是为 GNN 解码器设计的,可被视为一种正则化(regularization),使自监督任务更具挑战性。
5.4.3 Effect of mask ratio
图 2 遮蔽率(mask ratio)的影响。在大多数情况下,低遮蔽率的表现并不好,且最佳的遮蔽率在不同的图(graph)中是不一样的。
5.4.4 Effect of decoder type
在表 4 中,我们比较了不同的解码器模型,包括 MLP、GCN、GIN 和 GAT。从结果可知,使用 GNN 解码器通常可以提高性能。与 MLP 相比,GNN 从编码器得到的潜在表征(latent representations)中重建原始特征,GNN可以让被遮蔽的节点从它的邻居节点中提取与其原始特征相关的信息。
5.4.5 Effect of encoder architecture
在表 5 中,我们在节点分类任务上比较了不同的编码器模型,包括 GCN 和 GAT。我们观察到,使用 GAT 作为编码器的 GraphMAE 表现优于基线,是一个更好的选择。
![]()
▲表5. 在节点分类任务中使用不同编码器模型的实验结果
Conclusion
在这个工作中,我们探索了图(graph)的生成性自监督学习(generative self-supervised learning),并确定了图自动编码器(graph autoencoders)所面临的常见问题。因而,我们提出了 GraphMAE——一个简单的遮蔽图自动编码器(masked graph autoencoder),从重建目标、学习过程、损失函数和模型框架的角度来解决这些问题。
在 GraphMAE中,我们设计了遮蔽特征重建策略(masked feature reconstruction strategy)和可缩放的余弦误差(scaled cosine error)。我们进行了广泛的实验,结果证明了 GraphMAE 的有效性(effectiveness)和普适性(generalizability)。我们的工作表明生成性 SSL 可以为图表示学习提供巨大的潜力,值得我们在未来的工作中进行更深入的探索。
Personal Comments
这篇工作提出了一个新的生成性自监督学习模型 GraphMAE,利用遮蔽策略使其获得超过对比学习的表现。这个题材(topic)应该受到 kaiming he 老师的 MAE 的启发,将其迁移到了图上。整体模型简单,架构新颖,但性能在图分类和节点分类任务上提升有限。
且根据表 4,将解码器从 MLP 换成 GNN,除 GAT 之外的其他 GNN 表现基本和 MLP 接近,则解码器表现力有限的论点有点站不住脚。且论文中很多章节(比如方法论 method、实验部分)的论点比较重复,行文比较乱,写得也有一些故作高深。笔者本人不是很欣赏这篇论文的文风。这篇论文精读的方法论部分笔者自己有做过修改。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()