

这篇综述深入分析了大型语言模型(LLMs)中的知识冲突问题,突出了它们在融合上下文和参数知识时遇到的复杂挑战。我们关注三类知识冲突:上下文记忆冲突、跨上下文冲突和内部记忆冲突。这些冲突可能显著影响LLMs的可信度和性能,特别是在噪声和误信息普遍存在的现实世界应用中。通过对这些冲突的分类、探索原因、检查LLMs在此类冲突下的行为,并回顾可用的解决方案,此综述旨在阐明提高LLMs鲁棒性的策略,因而为这一不断发展领域的研究进步提供了宝贵的资源。
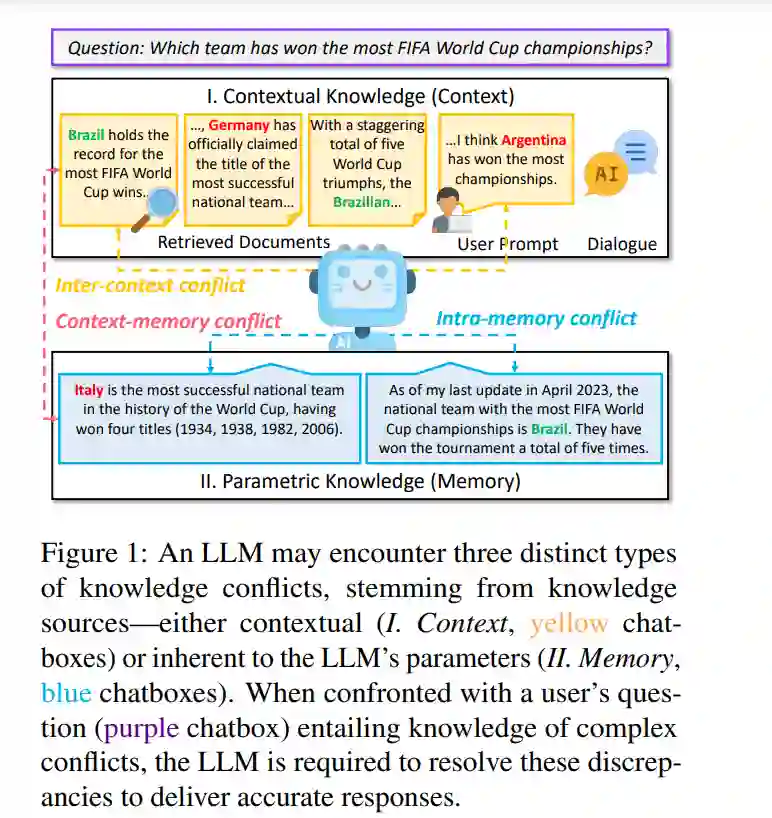
大型语言模型(LLMs)(Brown et al., 2020;Touvron et al., 2023;Achiam et al., 2024)因包含广泛的世界知识库(被称为参数知识)而闻名(Petroni et al., 2019;Roberts et al., 2020)。这些模型在包括问答(QA)(Petroni et al., 2019)、事实核查(Gao et al., 2023a)、知识生成(Chen et al., 2023c)等知识密集型任务中表现出色。与此同时,LLMs在部署后继续与外部上下文知识交互,包括用户提示(Liu et al., 2023a)、交互式对话(Zhang et al., 2020)或从Web检索的文档(Lewis et al., 2020;Shi et al., 2023c)以及工具(Schick et al., 2023;Zhuang et al., 2023)。将上下文知识整合到LLMs中,使它们能够跟上当前事件(Kasai et al., 2022)并生成更准确的回应(Shuster et al., 2021),但由于知识来源丰富,这也存在冲突的风险。上下文与模型的参数知识之间的差异被称为知识冲突(Chen et al., 2022;Xie et al., 2023)。在本文中,我们分类三种不同类型的知识冲突,如图1所示。如图1中的例子所示,当使用LLM回答用户问题时,用户可能会提供补充提示,而LLM也利用搜索引擎从Web收集相关文档以增强其知识(Lewis et al., 2020)。用户提示、对话历史和检索的文档的组合构成上下文知识(上下文)。上下文知识可能与LLM参数内封装的参数知识(记忆)发生冲突,我们将这种现象称为上下文-记忆冲突(CM,§ 2)。在现实世界场景中,外部文档可能充满噪声(Zhang and Choi, 2021)甚至是故意制造的错误信息(Du et al., 2022b;Pan et al., 2023a),这使得它们的处理和准确响应能力复杂化(Chen et al., 2022)。我们将不同上下文知识之间的冲突称为跨上下文冲突(IC,§ 3)。为了减少回应中的不确定性,用户可能以不同形式提出问题。因此,LLM的参数知识可能对这些不同措辞的问题产生不同的回应。这种变化可以归因于LLM参数中嵌入的冲突知识,这源于复杂和多样化的预训练数据集中存在的不一致性(Huang et al., 2023)。这就引发了我们所称的内存冲突(IM,§ 4)。
知识冲突最初源于开放领域问答(QA)研究。这一概念在 Longpre et al. (2021) 的研究中获得关注,该研究聚焦于参数知识与外部文段之间基于实体的冲突。同时,也细致审视了多个文段之间的差异(Chen et al., 2022)。随着大型语言模型(LLMs)的最近出现,知识冲突引起了显著注意。例如,近期研究发现LLMs既遵循参数知识又易受上下文影响(Xie et al., 2023),当这些外部知识在事实上不正确时可能会出现问题(Pan et al., 2023b)。考虑到对LLMs的可信度(Du et al., 2022b)、实时准确性(Kasai et al., 2022)和鲁棒性(Ying et al., 2023)的影响,深入理解和解决知识冲突变得至关重要(Xie et al., 2023; Wang et al., 2023g)。
截至撰写本文时,据我们所知,还没有专门用于调查知识冲突的系统性综述。现有的综述(Zhang et al., 2023d; Wang et al., 2023a; Feng et al., 2023)将知识冲突作为其更广泛内容中的一个子话题触及。虽然Feng et al. (2023) 对知识冲突进行了更系统的考察,将它们分类为外部和内部冲突。然而,他们的综述只是简要概述了相关工作,并主要关注特定场景。为了填补这一空白,我们旨在提供一个全面的综述,包括对各种知识冲突的分类、原因与行为分析,以及解决方案。
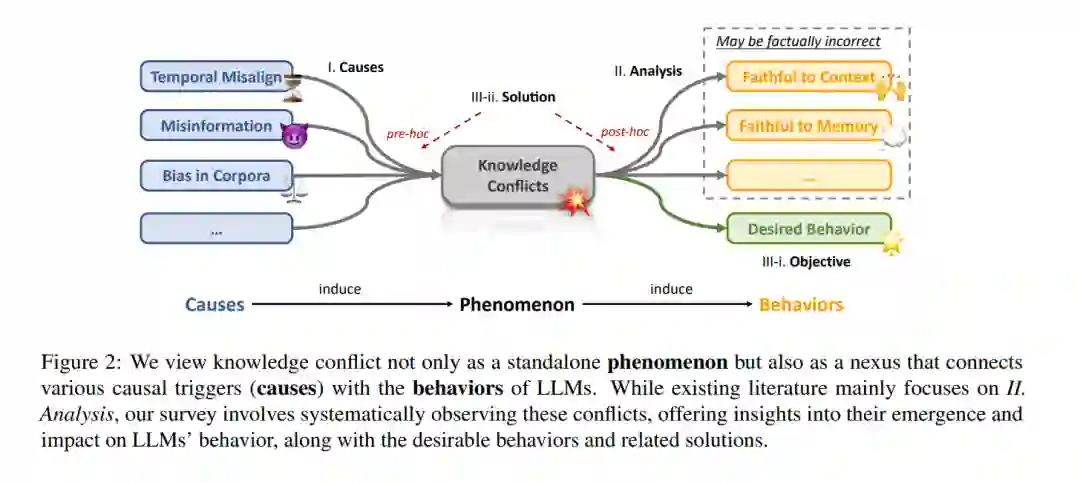
我们综述的方法论如图2所示,我们将知识冲突的生命周期概念化为既是导致模型出现各种行为的原因,也是从知识的复杂性质中产生的效果。知识冲突是原因与模型行为之间的关键中介。例如,它们显著地贡献于模型生成事实上不正确的信息,即幻觉(Ji et al., 2023; Zhang et al., 2023d)。我们的研究,类似于弗洛伊德式的精神分析,强调了理解这些冲突起源的重要性。尽管现有分析(Chen et al., 2022; Xie et al., 2023; Wang et al., 2023g)倾向于人为构造这些冲突,我们认为这些分析没有充分解决问题的相互连通性。
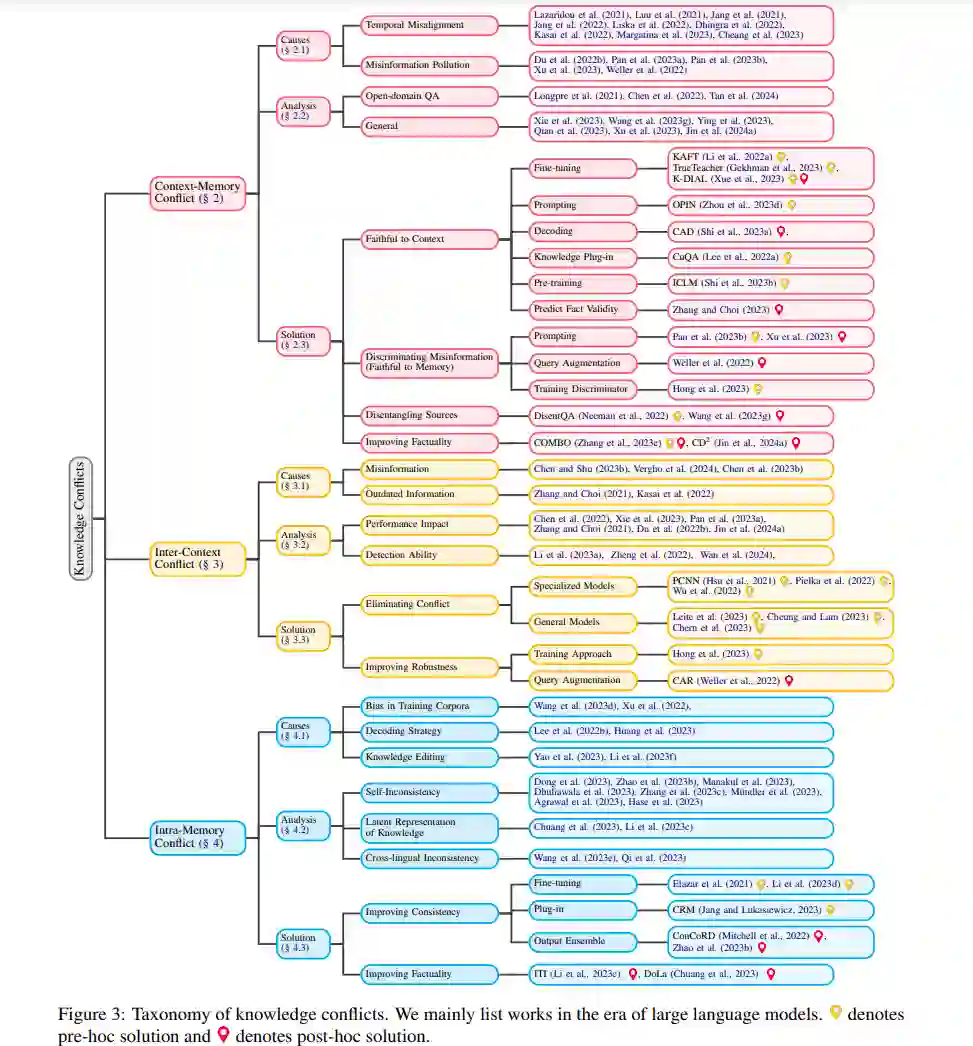
我们不仅回顾和分析原因和行为,而且深入提供解决方案的系统综述,这些解决方案用于最小化知识冲突的不希望出现的后果,即鼓励模型展现出符合特定目标的期望行为(请注意,这些目标可能基于特定场景而有所不同)。根据与潜在冲突相关的时机,策略分为预事前和事后两大类。它们之间的主要区别在于是在潜在冲突出现前还是后进行调整。知识冲突的分类在图3中概述。我们依次讨论三种知识冲突,详细说明每种冲突的原因、模型行为的分析,以及根据各自目标组织的可用解决方案。相关数据集可在表1中找到。

上下文-记忆冲突是三种类型冲突中研究最为广泛的。LLMs由固定的参数知识特征化,这是大量相关处理过程的结果(Sharir et al., 2020; Hoffmann et al., 2022; Smith, 2023)。这种静态的参数知识与外部信息的动态本质形成鲜明对比,后者以迅速的速度发展变化(De Cao et al., 2021; Kasai et al., 2022)。
上下文-记忆冲突的核心在于LLMs的参数知识与接收到的、更新的外部信息之间存在不一致。LLMs在被训练的时候,固化了大量的信息和知识,但这些信息随着时间的推移可能会过时或与新的外部信息产生冲突。这种固化的参数知识与不断更新的外部环境之间的差异,导致了上下文-记忆冲突的出现。 处理这种冲突的关键在于如何有效地整合这两种类型的知识,确保LLMs在提供响应时既能反映其深厚的内在知识库,又能适应外部环境的变化。研究者们正在探索各种方法,以减少这种冲突对LLMs性能的影响,从而提高它们的实时准确性、可信度和鲁棒性。
跨上下文冲突在LLMs中体现在整合外部信息源时,这一挑战通过引入RAG(检索增强生成)技术而变得更加显著。RAG通过将检索到的文档内容整合到上下文中,丰富了LLM的响应。然而,这种整合可能导致提供的上下文内部出现不一致性,因为外部文档可能包含相互冲突的信息(Zhang and Choi, 2021; Kasai et al., 2022; Li et al., 2023a)。
在使用RAG技术时,LLMs需要从多个检索到的文档中提取信息,以生成回应。这些文档来自于互联网或其他数据库,每个文档都可能基于不同的视角、来源或时效性提供信息。当这些文档之间的信息存在矛盾时,就会出现跨上下文冲突。例如,两个不同的文档可能对同一事件提供截然不同的解释或数据。LLMs在尝试整合这些信息以形成一致的回应时,可能会因为这些冲突而难以做出决定。
解决跨上下文冲突的策略包括改进LLMs的信息评估和整合能力,例如通过增强模型的理解和判断力来识别和调和这些冲突。此外,可以通过优化检索算法来提高文档选择的准确性和相关性,减少引入冲突信息的可能性。研究者们正致力于开发这些策略,以提高LLMs处理跨上下文冲突的能力,确保它们在面对复杂多变的外部信息时仍能生成准确、一致的回应.
随着大型语言模型(LLMs)的发展,LLMs在知识密集型问答系统中得到了广泛应用(Gao et al., 2023b; Yu et al., 2022; Petroni et al., 2019; Chen et al., 2023c)。有效部署LLMs的一个关键方面是确保它们对具有相似含义或意图的各种表达生成一致的输出。尽管这一点至关重要,但内存冲突—一种LLMs对语义上等价但句法上不同的输入展现出不可预测行为并生成不同响应的情况—却是一个显著的挑战(Chang and Bergen, 2023; Chen et al., 2023a; Raj et al., 2023; Rabinovich et al., 2023; Raj et al., 2022; Bartsch et al., 2023)。内存冲突实质上通过在它们的输出中引入一定程度的不确定性,削弱了LLMs的可靠性和实用性。
内存冲突揭示了LLMs在处理语言的深层次一致性方面的局限性。虽然这些模型在大规模的数据训练中学习了广泛的语言模式和知识,但它们仍然难以在语义上等价的表达之间做出一致的推断。这种冲突不仅影响了模型在问答系统、文本摘要、语言翻译等任务中的表现,也对开发更高效、更准确的LLMs提出了挑战。 为解决内存冲突问题,研究人员正在探索不同的方法,包括改进模型的训练过程以提高其对语义等价性的理解,开发新的模型架构以更好地处理句法多样性,以及采用后处理技术来纠正模型输出中的不一致性。通过这些努力,我们可以期待在未来LLMs将在保持输出一致性方面取得显著进步,从而增强其在各种应用场景中的可靠性和实用性。
通过这项综述,我们广泛调查了知识冲突,阐明了它们的分类、原因、LLMs对这些冲突的响应以及可能的解决方案。我们的发现揭示了知识冲突是一个多方面的问题,模型的行为与特定类型的冲突知识密切相关。此外,三种类型的冲突之间似乎存在更复杂的相互作用。进一步来说,我们观察到现有解决方案主要针对人为构建的场景,忽略了依靠假设的先验知识所带来的冲突细微之处,因此牺牲了细致度和广度。 考虑到检索增强型语言模型(RALMs)的使用日益增长,我们预计LLMs面临的知识冲突只会变得更加复杂,这强调了在这一领域进行更全面研究的必要性。随着技术的不断进步和复杂性的增加,寻找解决这些挑战的方法将变得尤为重要,以确保LLMs在各种应用中的可靠性和有效性。这要求研究者们不仅要深入探索知识冲突的本质,还要开发新的方法来应对这些冲突,从而推动LLMs技术的进一步发展。
