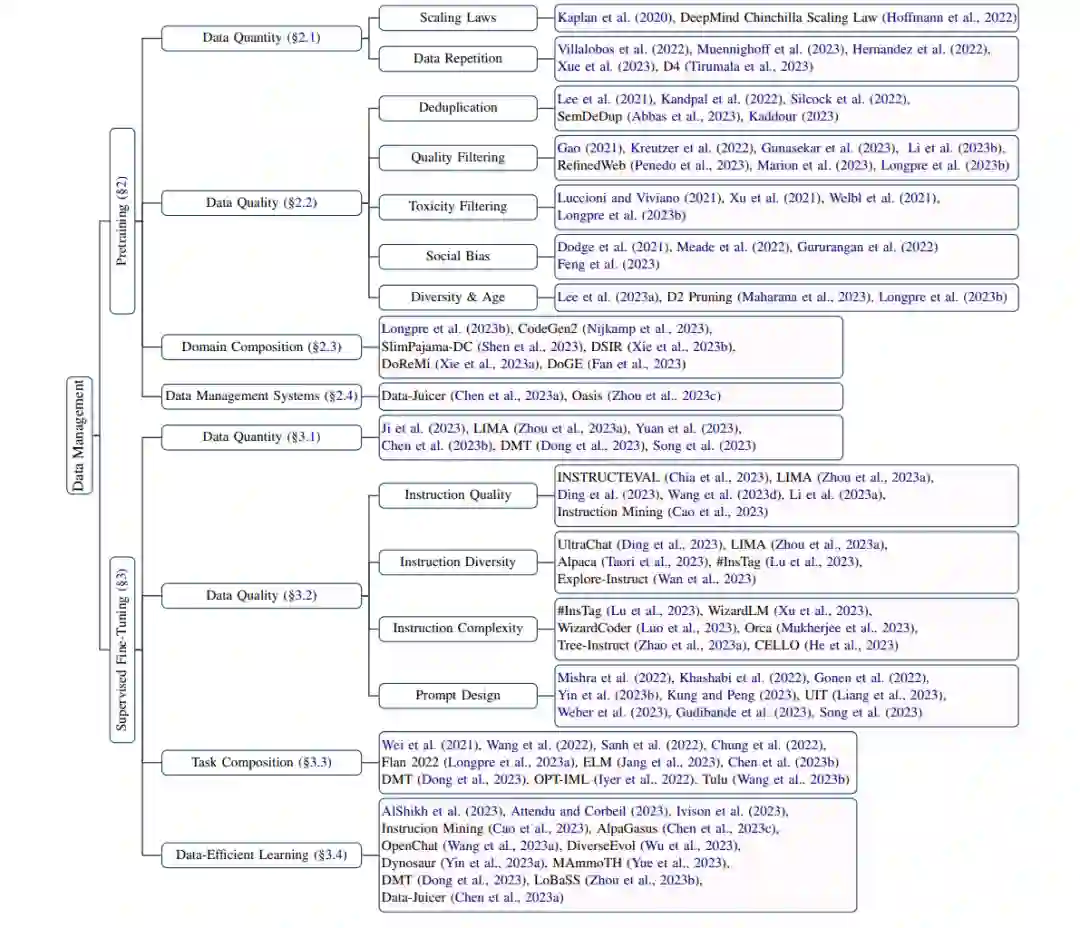
数据在大型语言模型(LLM)训练中扮演了基础性的角色。有效的数据管理,尤其是在构建适合的训练数据集方面,对于提升模型性能和提高预训练及监督式微调阶段的训练效率至关重要。尽管数据管理的重要性不言而喻,目前的研究界仍在提供系统性分析管理策略选择背后的理由、其后果效应、评估策划数据集的方法论,以及持续改进策略方面存在不足。因此,数据管理的探索在研究界越来越受到关注。本综述提供了一个关于LLM预训练和监督式微调阶段内数据管理的全面概览,涵盖了数据管理策略设计的各个值得注意的方面:数据量、数据质量、领域/任务组成等。展望未来,我们推断现有挑战,并勾勒出这一领域发展的有希望的方向。因此,本综述可作为希望通过有效数据管理实践构建强大LLM的从业者的指导资源。最新论文的集合可在 https://github.com/ZigeW/data_management_LLM 获取。
https://www.zhuanzhi.ai/paper/aa29cf2a66cbca5f590a18c23e853212
大型语言模型(LLM)以其强大的性能和新兴能力震惊了自然语言处理(NLP)社区(OpenAI, 2023; Touvron et al., 2023a; Wei et al., 2022)。根据之前的研究(Kaplan et al., 2020; Hoffmann et al., 2022),LLM的成就在很大程度上依赖于对大量文本数据进行自监督式预训练。近期的研究(Zhou et al., 2023a; Ouyang et al., 2022)进一步通过对精心策划的指令数据集进行监督式微调,增强了LLM的指令遵循能力和下游任务的性能。
我们定义的数据管理——构建适合的训练数据集,在LLM的预训练和监督式微调(SFT)阶段都至关重要且充满挑战。在预训练阶段,构建包含高质量和最有用数据的数据集对于高效训练是必不可少的(Jain et al., 2020; Gupta et al., 2021)。为了赋予LLM一般性能力,也需要具有多种领域混合的异质数据集组成(Gao et al., 2020; Longpre et al., 2023b; Shen et al., 2023)。然而,许多著名的LLM并没有透露(Anil et al., 2023; OpenAI, 2023)或仅记录了预训练数据构建中选择的过程(Brown et al., 2020; Workshop et al., 2022; Touvron et al., 2023a),使其背后的理由缺失。在SFT阶段,LLM的性能和指令遵循能力在很大程度上由精心设计的指令数据集所唤起(Sanh et al., 2022; Ouyang et al., 2022)。尽管已有一些带有人类注释的指令数据集/基准被提出(Wang et al., 2022; Köpf et al., 2023),自我指令(Wang et al., 2023c; Taori et al., 2023)或现有数据集的收集(Si et al., 2023; Anand et al., 2023),从业者仍对指令数据集对微调LLM的性能的影响感到困惑,导致在LLM微调实践中选择合适的数据管理策略困难重重。
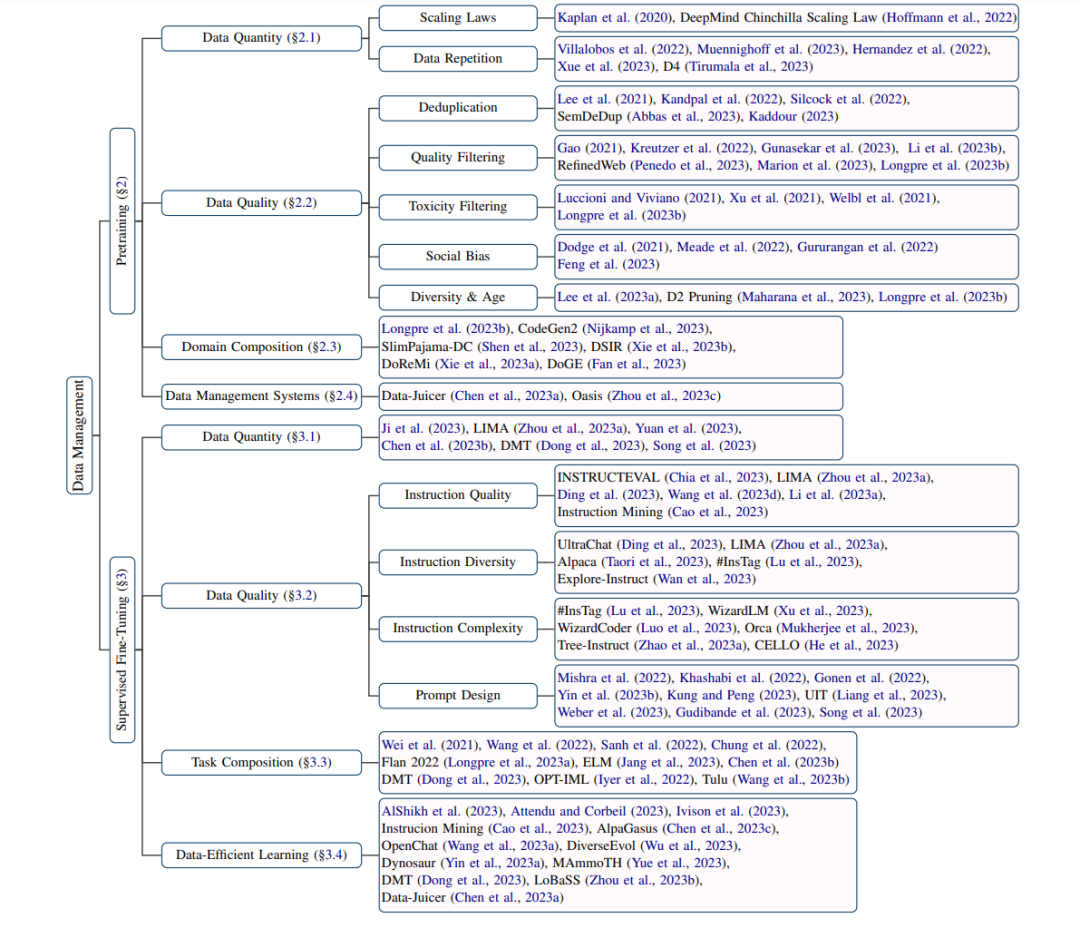
为了应对这些挑战,需要对数据管理进行系统性分析,包括管理策略选择背后的理由及其后果效应、策划训练数据集的评估,以及改进策略的追求。因此,本综述旨在提供当前数据管理研究的全面概览,如图1所示。在第2部分,我们关注预训练数据管理,包括数据量、数据质量、领域组成和数据管理系统的研究。在第3部分,我们讨论LLM监督式微调(SFT)阶段的数据量、数据质量、任务组成和数据高效学习。在第4部分,展望未来,我们提出了LLM训练数据管理中现存的挑战和有希望的未来发展方向。通过本综述,我们致力于为试图通过有效和高效的数据管理实践构建强大LLM的从业者提供指导资源。
大模型预训练
数据管理在许多著名大型语言模型(LLM)的预训练中被发现非常重要(OpenAI, 2023; Touvron et al., 2023a; Wei et al., 2022)。虽然大多数LLM没有报告它们的数据管理程序,或者只报告了它们采用的策略,但选择特定策略的原因和数据管理策略的效果对于构建更强大的LLM至关重要。在这一部分,我们首先回顾研究训练数据集规模定律的研究,包括有/无数据重复的情况。然后,探讨与去重、质量过滤、有害内容过滤、社会偏见以及数据多样性和时效性相关的数据质量问题。之后,讨论领域组成和领域重新加权方法。最后,介绍了两个最近提出的实施预训练数据管理流程的数据管理系统。
2.1 数据量
LLM高效预训练所需的数据量是NLP社区持续研究的话题。提出了规模定律来描述模型大小和训练数据集大小之间的关系。随着模型大小的不断增加,文本数据的耗尽引起了研究人员对LLM预训练中数据重复的关注。 2.1.1 规模定律 在LLM普及之前,研究者就已经关注训练数据集大小与具有变压器架构(Vaswani et al., 2017)的语言模型性能之间的关系。Kaplan et al.(2020)研究了变压器语言模型在交叉熵损失上的经验性规模定律,发现模型性能与训练数据集大小之间存在幂律关系,当不受模型大小和训练计算预算的限制时。他们还得出结论,只要模型大小和训练数据集大小同时扩展,模型性能就会可预测地提高,但如果其中一个固定而另一个增加,则会遇到过拟合。他们提出的性能惩罚预测比例显示,模型大小应该比训练数据集大小增长得更快。 继Kaplan et al.(2020)提出的幂律关系后,Hoffmann et al.(2022)对更大的语言模型进行了实验,得出不同的结论,即模型大小和数据集大小应该以大致相同的速率随着更多的计算预算而扩展。
2.1.2 数据重复
尽管Kaplan et al.(2020)和Hoffmann et al.(2022)关注的是唯一数据训练一个时期的规模定律,Hernandez et al.(2022)解决了训练数据集中文本重叠的问题,并研究了包含少量重复数据的规模定律。他们观察到强烈的双下降现象(Nakkiran et al., 2021),其中重复数据导致训练过程中途测试损失增加,并发现可预测的重复频率范围会导致严重的性能下降。 随着模型大小的增长,根据规模定律,需要更多的训练数据,引起了关于耗尽高质量训练数据的担忧(Villalobos et al., 2022; Hoffmann et al., 2022)。克服这一问题的一种直接方法是对数据进行重复训练。然而,如上所述,数据重复众所周知会导致性能下降。受到这一矛盾的启发,几项工作研究了对数据集进行多个时期的重复预训练的后果。Muennighoff et al.(2023)发现,在受限的数据和固定的计算预算下,对相同的数据重复训练多达4个时期与训练唯一数据相比,对损失的变化微不足道。他们还提出了一个规模定律,考虑到了重复和过多参数的回报递减。Xue et al.(2023)也观察到模型性能的多时期退化,并发现数据集大小、模型参数和训练目标是这一现象的关键因素。他们进一步发现,常用的正则化技术在缓解多时期退化方面没有帮助,除了dropout。质疑以前的发现,Tirumala et al.(2023)展示了对精心选择的重复数据进行训练可以胜过对随机选择的新数据进行训练,而对随机选择的重复数据进行训练则不行,这表明了重复使用智能选择数据的可行方法。
2.2 数据质量
根据以往研究(Jain et al., 2020; Gupta et al., 2021),高质量数据在机器学习任务训练中至关重要。在LLM的预训练中,也采用了质量保证技术,通常形成数据管理流程(Rae et al., 2021; Nguyen et al., 2023; Tirumala et al., 2023),包括去重、质量过滤和有毒内容过滤。社会偏见、数据多样性和数据时效性等方面也是研究社区感兴趣的话题。
2.2.1 去重
去重在许多著名LLM的数据管理程序和公开可用数据集的预处理中被广泛使用(Brown et al., 2020; Workshop et al., 2022; Touvron et al., 2023a; Raffel et al., 2020)。Lee et al.(2021)使用N-gram相似性与MinHash(Broder, 1997)来检测训练数据集中的重复,并发现去重有助于减轻记忆效应、避免训练-测试重叠,并保持模型困惑度的同时提高训练效率。Kandpal et al.(2022)还表明,去重可以显著降低针对模型记忆的隐私攻击的成功率。 在去重实践中,N-gram-and-hashing是最常用的技术(Lee et al., 2021; Borgeaud et al., 2022; Rae et al., 2021)。Silcock et al.(2022)将其与神经方法进行比较,即对比训练的双编码器和结合双编码器和交叉编码器的“重排”风格方法,得出结论神经方法可以显著优于传统的N-gram-and-hashing方法。Abbas et al.(2023)提出SemDeDup来移除位于预训练模型嵌入空间中靠近的语义重复,并应用聚类来减少搜索计算。同样,Kaddour(2023)通过过滤掉低质量嵌入集群,构建了Pile(Gao et al., 2020)的子集MiniPile。
2.2.2 质量过滤
质量过滤是构建适合预训练数据集的另一个关键步骤,因为像Common Crawl 1和多语言数据集(Kreutzer et al., 2022)这样的公共数据集通常包含低质量数据,这会妨碍LLM的训练。现有工作通常使用分类器(Brown et al., 2020; Gao et al., 2020; Du et al., 2022; Touvron et al., 2023a)、手工制定的启发式规则(Yang et al., 2019; Raffel et al., 2020; Nijkamp et al., 2022)或使用困惑度等标准进行阈值过滤(Wenzek et al., 2020; Muennighoff et al., 2023)来进行质量过滤。 质量过滤通常被证明有利于提升模型性能(Longpre et al., 2023b),尽管这会减少训练数据的数量和多样性。轻量级语言模型phi-1和phi-1.5,拥有13亿参数,分别在精心选取的高质量数据和合成数据上训练,展现了在编码任务和常识推理上的出色表现。Penedo等人(2023年)构建了RefinedWeb数据集,包括适当过滤和去重的高质量网络数据,其性能超过了在Pile(Gao et al., 2020)上训练的模型。与常见结论相反,Gao(2021年)发现,由于过滤目标不够稳健,对GPT类LLM的大范围任务进行激进过滤可能导致性能下降。为了解决这个问题,Marion等人(2023年)研究了三种数据质量估计器:困惑度、错误L2范数(EL2N)和记忆因子,并通过数据修剪进行测试。令人惊讶的是,他们发现基于困惑度修剪数据集的表现远远优于更复杂的技术,如记忆。
2.2.3 有害内容过滤
有害内容指的是粗鲁、不尊重或不合理的语言,可能会导致某人离开讨论(Gehman et al., 2020; Welbl et al., 2021)。由于原始文本语料库通常包含有害文本(Luccioni和Viviano,2021;Longpre et al., 2023b),有害内容过滤旨在从预训练数据集中移除不希望出现的有害文本,进一步防止LLM生成有害话语。与质量过滤类似,启发式和基于规则的过滤(Lees et al., 2022; Gargee et al., 2022; Friedl, 2023)和N-gram分类器(Raffel et al., 2020)被用作有害内容过滤器。尽管有效地进行模型解毒,Longpre等人(2023b)发现,有害内容过滤减少了生成有害内容的风险,但同时降低了模型的泛化和识别有害内容的能力。此外,Xu等人(2021年)和Welbl等人(2021年)均发现,训练数据集的解毒处理会导致边缘化少数群体,如方言和少数族裔身份提及。
2.2.4 社会偏见
除了数据解毒导致的少数群体边缘化之外,一些工作(Kurita et al., 2019; Nangia et al., 2020; Meade et al., 2022; Feng et al., 2023)发现预训练的LLM可以捕捉到大量训练文本中包含的社会偏见。Dodge等人(2021年)评估了C4(Raffel et al., 2020)数据集,建议记录大型网络文本语料库中的社会偏见和代表性伤害,以及被排除的声音和身份。Gururangan等人(2022年)使用美国高中报纸文章的新数据集,也指出GPT-3使用的质量过滤器倾向于选择更大学校在更富裕、受过教育和城市邮政编码地区发布的报纸,从而导致一种语言意识形态。Feng等人(2023年)进行了一项全面的案例研究,重点关注预训练语料库中媒体政治偏见对仇恨言论检测和错误信息检测公平性的影响,以及它如何传播到语言模型,甚至进一步影响到下游任务。
2.2.5 多样性和时效性
在LLM预训练阶段的数据管理中,也有研究关注数据的其他方面,例如多样性和时效性。 例如,Lee等人(2023a)展示了,当用最近提出的Task2Vec多样性系数(Miranda et al., 2022)来衡量时,公开可用的预训练数据集在形式上的多样性很高。他们还证明了该系数与多样性的直观特性是一致的,并建议在构建更多样的数据集时使用它。Maharana等人(2023年)提出了一种新的修剪方法D2修剪,通过将数据集表示为一个带有难度分数的无向图,并采用正向和反向信息传递策略,来选择一个包含数据集空间中多样化和困难区域的核心子集,以平衡数据多样性和难度选择。
Longpre等人(2023b)探讨了评估数据集的时效性,并得出结论,评估数据与预训练数据之间的时间偏移会导致性能估计不准确,而且时间不一致无法通过微调来克服,尤其是对于更大的模型。
2.3 领域组成
公开可用的预训练数据集通常包含从多个来源和领域收集的数据混合体,例如Pile(Gao et al., 2020)包含了来自Common Crawl、维基百科、书籍以及医学、学术、编程和数学、法律和社会资源的网页文档。许多著名模型也是在不同领域的数据混合体上进行训练的,例如LaMDA(Thoppilan et al., 2022)是在来自公共论坛的对话数据、C4数据、编程相关问答网站和教程的代码文档、英文维基百科、英语网页文档和非英语网页文档上进行训练的。
研究人员努力探索领域混合对预训练模型性能的影响。Longpre等人(2023b)将Pile(Gao et al., 2020)数据分为九个领域,并进行了逐个删减实验,展示了不同领域的影响。他们得出结论,高质量(如书籍)和高多样性(如网页)的领域普遍有帮助,即使它们与下游任务相关性较低,包含尽可能多的数据源也是有益的。SlimPajama-DC(Shen et al., 2023)也得出相同的结论,即合并所有领域通常比有意选择的组合效果更好,前提是进行了全局去重,以消除不同领域数据集之间的重叠。Longpre等人(2023b)和Shen等人(2023)都认为,特定的混合体可能在针对特定任务的评估基准上表现出色,但与包含多样化的网络领域相比,优先级并不总是存在。CodeGen2(Nijkamp et al., 2023)研究了编程语言和自然语言混合体对模型性能的影响,并发现,在相同的计算预算下,使用混合体训练的模型的性能并不比与领域匹配的模型好,但接近。
还有几种方法被提出来找到适当的领域组成权重。DSIR(Xie et al., 2023b)将问题形式化为在给定一些未标记目标样本的情况下,选择原始未标记数据集的子集以匹配目标分布。具体来说,它利用经典的重要性重采样方法(Rubin, 1988)并使用n-gram特征和KL降低来估计重要性权重。没有下游任务的知识,DoReMi(Xie et al., 2023a)使用小型代理模型通过Group Domain Robust Optimization(Group DRO)(Oren et al., 2019; Sagawa* et al., 2020)生成领域权重。它通过增加在评估模型与预训练参考模型之间具有最大损失差距的领域的权重,提高了所有领域的模型性能。在DoReMi(Xie et al., 2023a)的基础上改进,Fan等人(2023)提出了DoGE,它对训练领域进行加权,以最小化所有训练领域或特定未见领域的平均验证损失。最终的泛化目标通过基于梯度的泛化估计函数来访问,该函数测量每个领域对其他领域的贡献。然后,对其他领域的学习贡献更大的领域将获得更大的权重。
2.4 数据管理系统
针对预训练数据管理的困难,集成数据管理系统对于有不同需求的LLM从业者来说是必要的。Chen等人(2023a)提供了一个数据处理系统Data-Juicer,它具有生成超过50种多功能数据管理操作符和专用工具的多样化数据配方功能,针对零代码数据处理、低代码定制和现成数据处理组件。它还支持在数据配方和LLM的多个开发阶段提供及时的反馈循环。Zhou等人(2023c)还提出了一个预训练数据策划和评估系统Oasis,其中包含一个交互式模块化规则过滤模块、一个去偏神经质量过滤模块、一个自适应文档去重模块和一个全面的数据评估模块。
监督式微调大型语言模型
基于在预训练阶段学到的通用知识和能力,提出了监督式微调(SFT)来进一步提高LLM的指令遵循能力和与人类期望的一致性(Wei et al., 2021; Sanh et al., 2022; Ouyang et al., 2022)。许多工作已经投入到使用人类注释(Wang et al., 2022; Köpf et al., 2023)、自我指令(Wang et al., 2023c; Taori et al., 2023)或现有数据集的集合(Si et al., 2023; Anand et al., 2023)来构建指令数据。尽管使用现有指令数据集微调的LLM在各种NLP任务中取得了显著的性能,但指令数据管理对微调模型性能的影响仍然存在争议。与之前有关LLM预训练的讨论一致,在本节中,我们总结了LLM SFT的研究探索,涵盖了数据量、数据质量(包括指令质量)、多样性、复杂性和提示设计,以及任务组成。此外,还包括了数据高效SFT,讨论了从数据角度出发的高效SFT的当前努力。
3.1 数据量 关于指令数据量的增加与微调模型性能之间关系的探索分为两个方向。一方面的研究专注于缩减指令数据量以提高训练效率。例如,LIMA(Zhou et al., 2023a)精心策划了1,000个高质量样本,并通过实验验证了他们的假设,即只需要有限的指令调整数据就足以展示LLM在预训练期间已经获得的知识和能力。Chen等人(2023b)观察到,对于单一任务特定的LLM微调,可能只需要一条指令,而1.9M标记的16K样本可能就足以训练专门从事自然语言推理(NLI)任务的模型。另一方面的研究则认为增加指令数据量对于成功至关重要(Wei et al., 2021; Sanh et al., 2022)。
为了解决这一冲突,几项工作试图分析不同任务或模型能力的扩展模式。Ji等人(2023)对12个主要的现实世界在线用户案例进行了实证研究,并展示了增加指令数据量会在提取、分类、封闭式问答和总结等任务中带来持续改进,而在数学、编码和思维链等任务中几乎没有改进。与Ji等人(2023)的观点不同,Dong等人(2023)发现一般能力可以通过大约1,000个样本得到增强,并在此后缓慢提升,而数学推理和代码生成则随着数据量的增加而持续提升。类似地,Yuan等人(2023)观察到指令数据量与模型数学推理性能之间存在对数线性关系,但预训练更强的模型对于更大的微调数据集改进较少。Song等人(2023)进行了涵盖十种不同能力的实验,并展示了大多数能力与数据扩展一致。然而,每种能力在指令调整期间的发展速度不同,一些能力甚至显示出完全不同的模式。
3.2 数据质量
在LLM的监督式微调中,数据质量始终是一个焦点,包括指令质量、多样性、复杂性和提示设计。这里我们更关注现有指令数据的管理和分析,而不是在之前的综述中已经讨论过的指令生成方法(Zhang et al., 2023b; Wang et al., 2023e)。
3.3 任务组成
由于LLM在处理各种NLP任务方面表现出惊人的新兴能力,多任务微调被视为进一步提高LLM在未见任务上泛化性能的有前景的方法。增加SFT中任务数量的好处已经在不同大小的模型上得到了实验证明,这些模型的参数范围从3B(Wang et al., 2022),11B(Sanh et al., 2022),137B(Wei et al., 2021)到540B(Chung et al., 2022)。
除了任务数量的扩展外,不同指令基准的混合比例和任务平衡也被发现对于有效的指令微调至关重要(Iyer et al., 2022; Longpre et al., 2023a)。Dong等人(2023)专注于数学推理、代码生成和一般人类对齐能力之间的任务组合,并发现在低资源混合数据下模型能力有所提升,但在高资源混合数据下相比于单一来源数据有所下降,即在高资源设置下观察到能力之间的冲突。为了进一步解释这些冲突,他们改变了一般和专业数据的比例,并得出结论,当SFT任务之间在任务格式和数据分布上存在显著差异时,数据比例的影响可以忽略,相反,当存在一定程度的相似性时,数据比例会导致性能的明显变化。
与将多个任务合并在一起不同,一些工作声称在单一任务数据上调整的LLM可以胜过在多个任务上调整的LLM(Jang et al., 2023; Chen et al., 2023b)。Jang等人(2023)指出,训练专家LLM的优先事项可能在于避免负面任务转移,通过持续学习新任务而不重新训练来防止灾难性遗忘,以及在将各个专家合并在一起时出现的组合能力。Wang等人(2023b)对使用12个指令数据集训练的模型进行了事实知识、推理、多语言性、编码和开放式指令遵循能力的分析,并展示了不同的指令数据集可以解锁或提升特定能力。相比之下,没有单一的数据集组合可以在所有评估中提供最佳性能。
3.4 数据高效学习
基于对数据量、数据质量和任务组成对模型性能影响的探索,许多工作提出了通过子集选择或学习策略来更高效地微调LLM,这些策略针对指令数据的不同方面。
结论
本文首次尝试概述大型语言模型(LLM)训练中的数据管理。我们分别讨论了LLM的预训练和监督式微调阶段,并总结了至今为止在每个阶段中关于数据量、数据质量和领域/任务组成的研究努力。同时也讨论了预训练阶段的数据管理系统和监督式微调阶段的数据高效学习。最后,我们强调了LLM训练数据管理的几个挑战和有希望的未来发展方向。我们希望这篇综述能为从业者提供有洞察力的指导,并激发在有效和高效数据管理方面的进一步研究,以促进LLM的发展。