

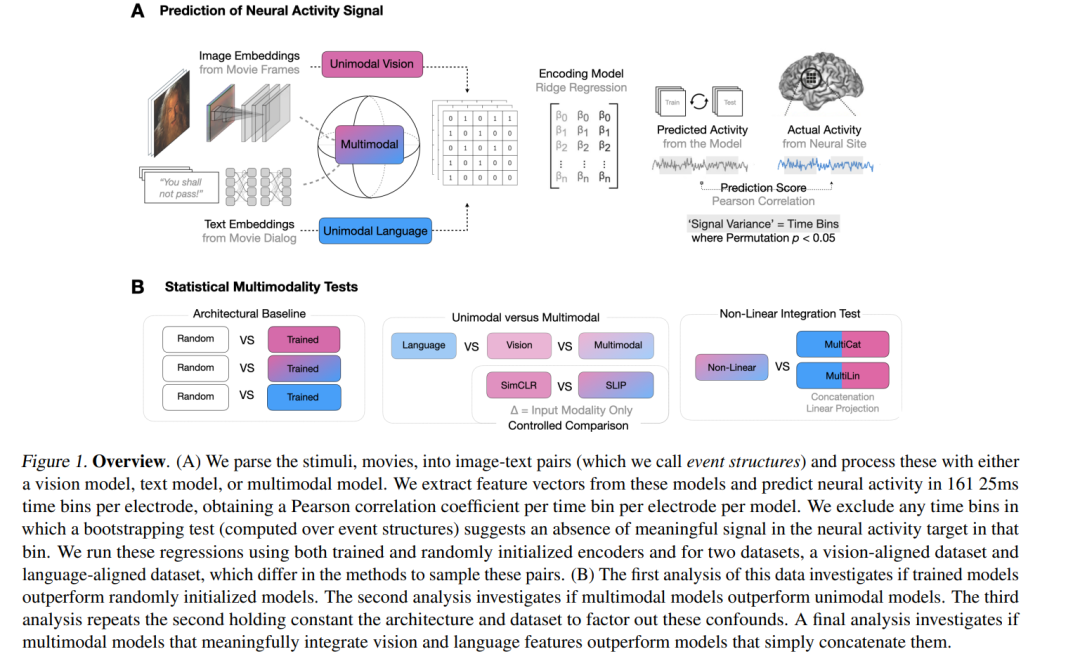
我们使用(多)模态深度神经网络(DNNs)来探测人类大脑中多模态整合的部位,通过预测人类受试者在观看电影时进行的立体脑电图(SEEG)记录来实现这一目标。我们将多模态整合的部位操作化为多模态视觉-语言模型比单模态语言、单模态视觉或线性整合的语言-视觉模型更好地预测记录的区域。我们的目标DNN模型涵盖不同的架构(如卷积网络和Transformer)和多模态训练技术(如交叉注意力和对比学习)。作为关键的启用步骤,我们首先证明了训练过的视觉和语言模型在预测SEEG信号的能力上系统地优于其随机初始化的对应模型。然后,我们将单模态和多模态模型进行比较。由于我们的目标DNN模型通常具有不同的架构、参数数量和训练集(可能掩盖因整合而产生的差异),我们对两个模型(SLIP和SimCLR)进行了受控比较,这两个模型除了输入模态外,其余属性保持相同。通过这种方法,我们确定了大量的神经部位(平均1090个总部位中的141个或12.94%)和大脑区域,在这些区域似乎发生了多模态整合。此外,我们发现,在我们评估的多模态训练技术变体中,CLIP风格的训练最适合下游神经活动预测。
成为VIP会员查看完整内容

相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日