
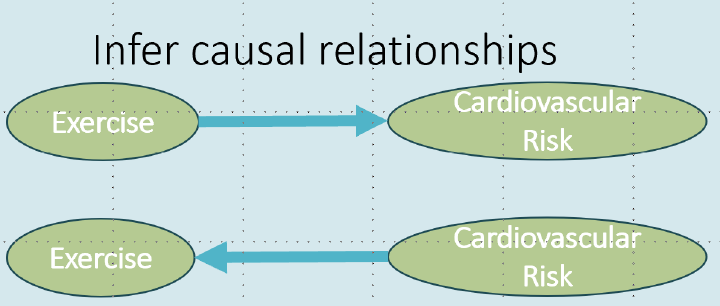
在进行因果分析的关键挑战是,确定正确的假设(如因果图)需要大量的手动努力。由于不能仅从数据中学习因果图,领域专家面临着提供并验证潜在因果关系的困难任务。在本次演讲中,我将讨论大型语言模型(LLMs)如何提供到目前为止被认为仅限于领域专家的新功能,例如推断因果关系的方向,识别任何缺失的关系,或验证因果分析中的基础假设。首先,我将展示LLMs在因果图发现方面的成果。基于GPT-3.5和4的算法在多种数据集上表现优于现有算法:涵盖物理学、工程学、生物学和土壤科学等领域的Tuebingen成对数据集(97%,13点增益)、北极海冰覆盖数据集(0.22汉明距离,11点增益)以及医疗疼痛诊断数据集。我们发现LLMs通过依赖如变量名等信息来推断因果关系,这一过程我们称之为基于知识的推理,它与非LLM基础的因果发现是不同且互补的。其次,我将描述这些LLMs的功能如何可以扩展用于因果推断流程中的有用任务:识别任何缺失的混淆变量,建议工具变量,建议可验证因果分析的特殊变量(如负对照),以及关于根本原因归因的推理。与此同时,LLMs展示了不可预测的故障模式,我将提供一些解释它们稳健性的技术,特别是与数据集记忆有关。展望未来,通过捕捉关于因果机制的领域知识,LLMs可能为推动因果推理研究开辟新的前沿,并促使因果方法的广泛采用。





成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日