
NeurIPS 是关于机器学习和计算神经科学的国际会议,宗旨是促进人工智能和机器学习研究进展的交流。NeurIPS 2025 会议将于12月2日至12月7日在圣地亚哥会议中心召开。

深度学习的发展依赖于梯度优化这一“黑暗艺术”。在深度学习中,优化过程往往呈现震荡、尖峰式变化和整体不稳定的特性。这些现象在经典优化理论中难以解释,因为传统理论主要研究的是良态、稳定的优化过程。然而,实践中效果最好的训练配置却始终运行在一种不稳定的 regime 下。 本教程将介绍近年来在理解训练不稳定性良性本质方面取得的理论进展,并从优化理论与统计学习的双重视角提供新的洞见。

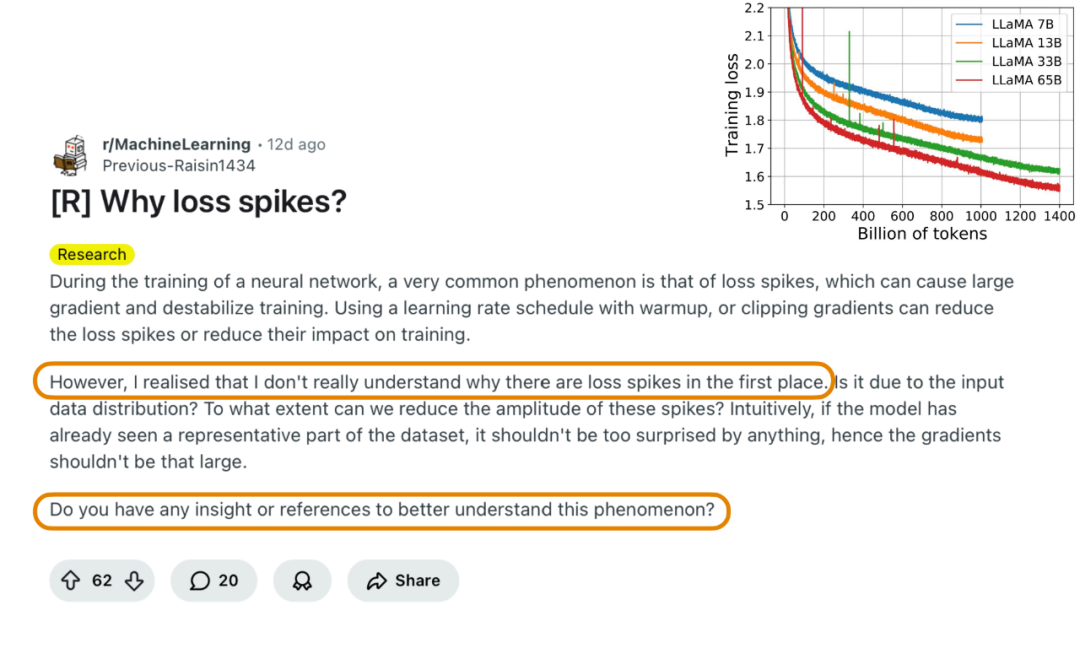
参考文献:
References
Large stepsizes accelerates optimization
- Large stepsize gradient descent for logistic loss: non-monotonicity of the loss improves optimization efficiency. Jingfeng Wu, Peter Bartlett, Matus Telgarsky, Bin Yu. COLT 2024.
- Large stepsizes accelerate gradient descent for regularized logistic regression. Jingfeng Wu, Pierre Marion, Peter Bartlett. NeurIPS 2025.
- Minimax optimal convergence of gradient descent in logistic regression via large and adaptive stepsizes. Ruiqi Zhang, Jingfeng Wu, Licong Lin, Peter Bartlett. ICML 2025.
- Acceleration by stepsize hedging II: silver stepsize schedule for smooth convex optimization. Jason M. Altschuler, Pablo A. Parrilo. Mathematical Programming, 2024.
- Composing optimized stepsize schedules for gradient descent. Benjamin Grimmer, Kevin Shu, Alex L. Wang. Mathematics of Operations Research, 2025.
成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日