

在短短几年内,大型语言模型(LLMs)从不存在到在机器学习领域无处不在。由于该领域的发展速度很快,很难确定剩下的挑战和已经产生成果的应用领域。在本文中,我们旨在建立一个系统的开放问题和应用成功的集合,这样机器学习研究者可以更快地理解该领域的当前状态并变得更加高效。
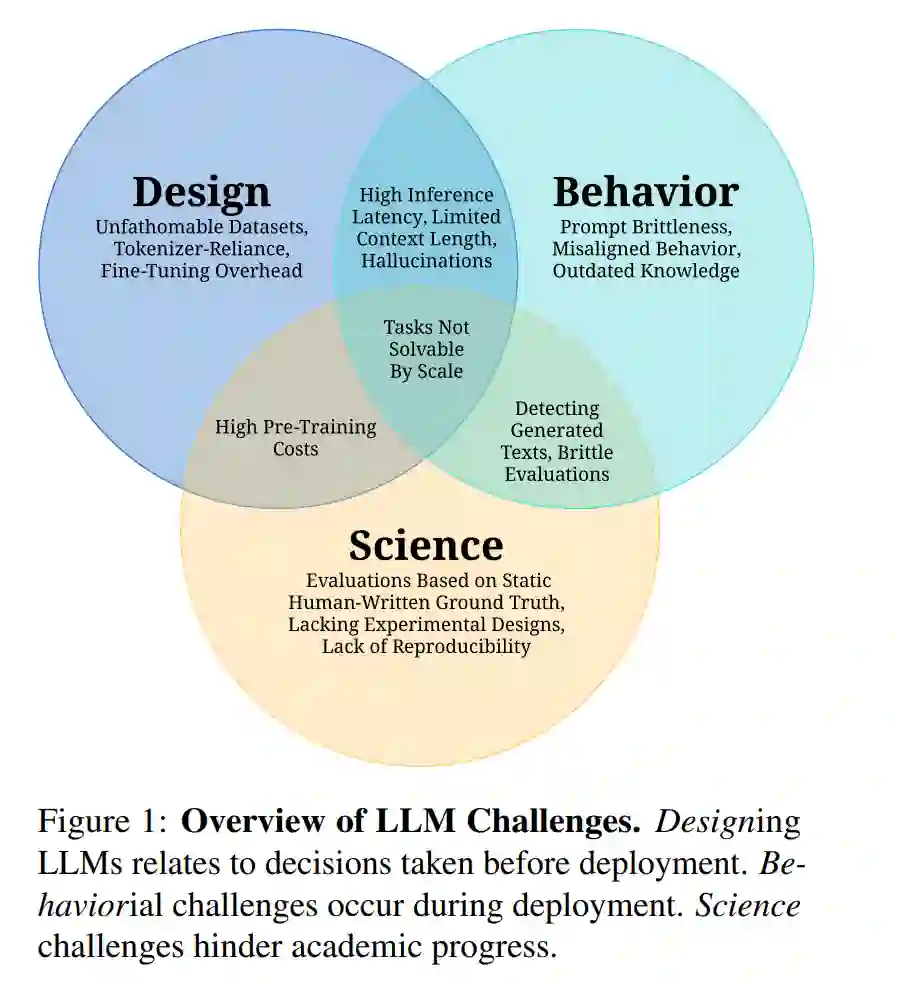
鉴于LLM研究论文的迅速增长,我们旨在回答两个问题:(1) 挑战:什么问题尚未解决? (2) 应用:LLMs目前应用在哪些领域,以及这些挑战是如何限制它们的? 对于(1),我们将图1中的挑战分为三个更广泛的类别:“设计”、“行为”和“科学”。为了回答(2),我们探讨了聊天机器人、计算生物学、计算机编程、创意工作、知识工作、法律、医学、推理、机器人技术和社会科学等领域。本文是一个带有观点的评论,并假设读者已熟悉LLMs及其工作方式(我们在第4节中提供了更多的入门作品)。此外,我们主要关注基于文本数据训练的模型。我们的目标读者是技术研究者,不讨论LLMs的政治、哲学或道德观点。
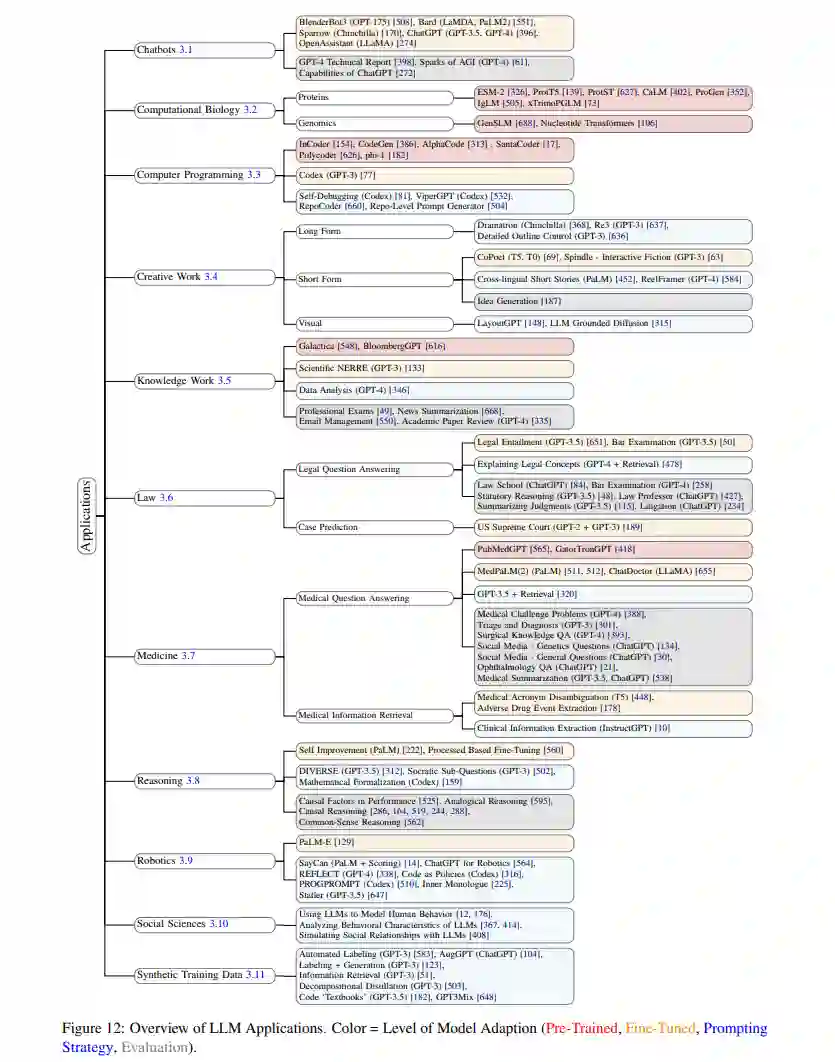
在本节中,我们旨在为实践者提供一个关于LLMs当前应用领域的宽泛概览,并突出跨领域的一些常见应用架构。与“挑战”部分类似,我们按如下方式突出每个应用领域的关键限制。
在这项工作中,我们确定了大型语言模型的几个尚未解决的挑战,提供了它们当前应用的概览,并讨论了前者如何限制后者。通过强调现有方法的局限性,我们希望促进未来针对这些问题的研究。我们还希望,通过提供在不同应用领域中使用的方法概览,我们可以促进域间的思想转移,并针对进一步的研究。


成为VIP会员查看完整内容
相关内容

Arxiv
87+阅读 · 2023年4月4日
Arxiv
153+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
87+阅读 · 2023年4月4日
Arxiv
153+阅读 · 2023年3月29日