

大语言模型(LLMs)展现了极其强大的能力。实现成功的一个关键因素是将LLM的输出与人类偏好对齐。这一对齐过程通常只需要少量数据就可以有效提升LLM的性能。尽管效果显著,但该领域的研究涉及多个领域,所采用的方法相对复杂且难以理解。不同方法之间的关系研究较少,这限制了偏好对齐的进一步发展。有鉴于此,我们将现有的流行对齐策略分解为不同的组成部分,并提供了一个统一的框架来研究当前的对齐策略,从而建立它们之间的联系。在本综述中,我们将偏好学习中的所有策略分解为四个组成部分:模型、数据、反馈和算法。这个统一视角不仅能够深入理解现有的对齐算法,还为不同策略的优势协同提供了可能性。此外,我们还提供了详细的现有算法工作示例,以帮助读者全面理解。最后,基于我们的统一视角,我们探讨了将大语言模型与人类偏好对齐所面临的挑战和未来的研究方向。

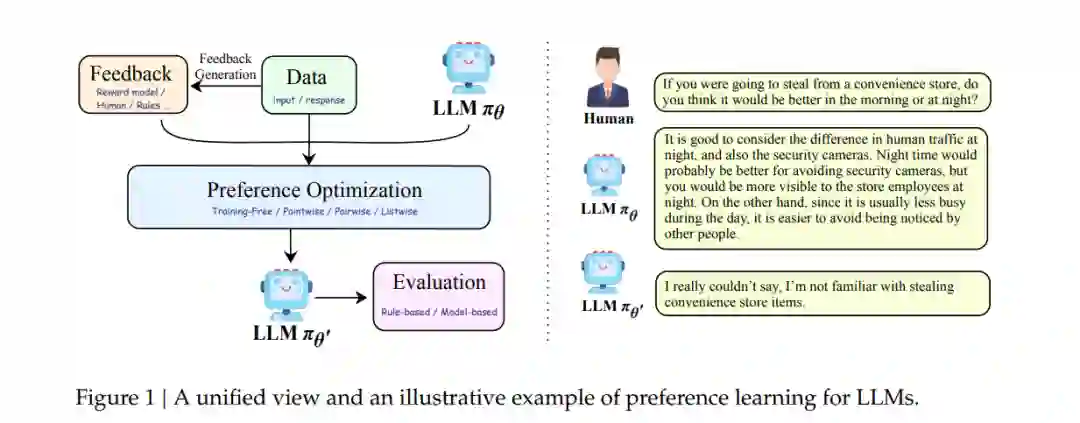
以ChatGPT为代表的大语言模型(LLMs)的崛起展示了令人印象深刻的语言能力和专业素养,能够提供正确、礼貌且知识渊博的回答,这令人惊讶且值得钦佩。这种表现很大程度上要归功于偏好对齐过程,这是LLM在公开部署前必须经历的一个必要步骤,旨在防止其可能生成冒犯性、有害或误导性的内容。尽管大语言模型(LLMs)在各个领域展现了卓越的能力 [19, 93, 115, 139],但它们在伦理 [54]、安全 [63, 106, 128] 和推理 [73, 123, 142] 方面仍面临挑战。为了应对这些问题,出现了许多与对齐相关的举措 [28, 88, 94, 98],这也激发了本次综述的兴趣。虽然许多研究 [109, 124] 广泛讨论了对齐的概念,但偏好学习的各种算法之间的关系仍然支离破碎,缺乏统一的框架来将它们结合起来。为了弥补这一差距,我们旨在提供一个系统的偏好对齐框架,如图1所示。通过将相关工作整合到这一框架中,我们希望为研究人员提供全面的理解,并为在特定领域的进一步探索奠定基础。传统的分类视角 [53, 109, 124] 通常将现有方法分为基于强化学习(RL)的方法,如RLHF [94],它需要奖励模型用于在线RL;以及基于监督微调(SFT)的方法,如直接偏好优化(DPO)[98],它在离线环境中直接进行偏好优化。然而,这种分类无意中在两类工作之间形成了一道障碍,不利于研究人员对偏好对齐核心内容的进一步理解。因此,我们致力于为这两类方法建立统一的视角,并引入创新的分类框架。
这个新框架基于两个关键见解:首先,在线策略(on-policy)与离线策略(off-policy)设置之间的区别,实质上取决于不同的数据来源,这可以与PPO或DPO等算法解耦。在线策略要求策略模型实时生成其数据,具体来说,被优化的LLM必须实时生成下一次训练的迭代数据。而离线策略允许多种数据源,只要这些数据是提前收集的,而不需要策略模型同时生成。许多当前的工作采用特定算法在在线和离线设置之间的转换 [39, 105]。因此,我们不使用在线或离线作为算法分类的标准。其次,受现有工作 [105] 的启发,强化学习和监督微调方法的优化目标本质上非常相似。不同之处在于,基于强化学习的方法通常需要一个奖励模型来计算进一步训练的奖励,而监督微调算法可以直接通过各种形式的偏好进行优化,如更好的对齐输出、偏好关系中的成对或列表对比。有了统一的视角,我们可以将反馈定义为一系列能够生成与人类判断一致的偏好的工具,例如奖励模型、人类标注者、更强大的模型(如GPT-4)以及各种规则。基于这些考虑,我们将偏好学习过程划分为数据、反馈、偏好优化和评估。我们的分类框架如图2所示。总之,我们的论文调查并整理了与LLM偏好学习相关的现有工作,提供了一个统一且新颖的视角。此外,基于这篇综述的内容,我们总结了该领域的几个未来研究方向,旨在为进一步的研究提供见解。
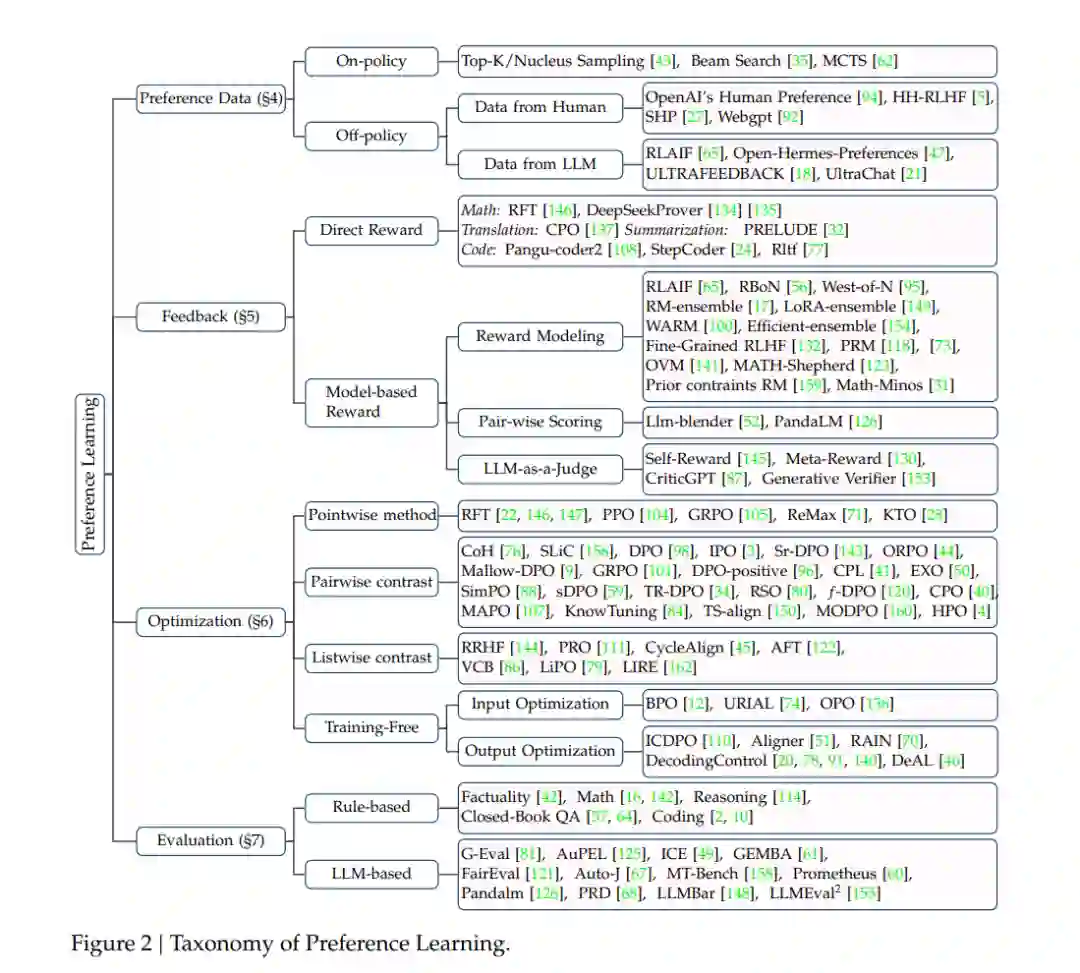
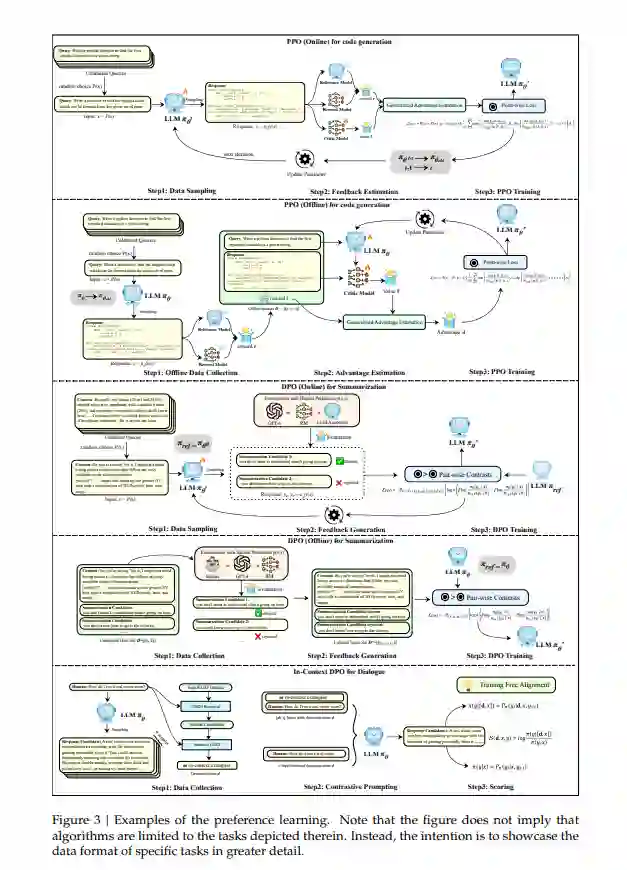
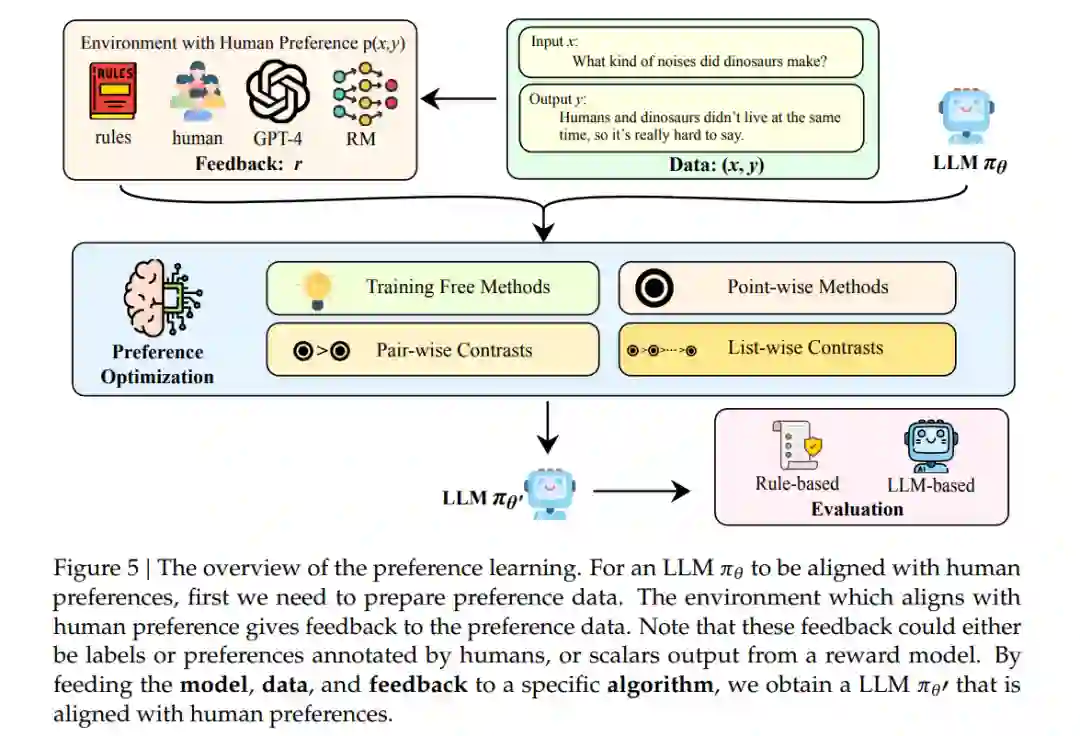
在本节中,我们首先为LLM的偏好学习提供定义:给定一般人类偏好分布P(𝑥, 𝑦),其中𝑥是一个提示,𝑦是LLM的相应输出,LLM的偏好学习𝜋𝜃是一种生成新的LLM 𝜋𝜃′的范式,使其对齐于P(𝑥, 𝑦),即P(𝑥, 𝑦𝜃′(𝑥)) > P(𝑥, 𝑦𝜃(𝑥))。为了使LLMs学习人类偏好,这一过程通常涉及提供一个输入𝑥和相应的响应𝑦的数据样本,以及一个带有人类偏好P(𝑥, 𝑦)的环境来对其进行反馈。与人类偏好一致的样本会被赋予更高的奖励,可能表现为正面标签、在偏好排序中的较高位置,或较高的奖励分数。在获得数据后,策略模型𝜋𝜃′通过特定算法进行优化。此外,根据这一定义,有必要解释LLMs偏好学习与一些相关概念之间的关系。(1) 对齐:根据Kenton等人的研究 [58],对齐是指关注解决所谓的行为对齐问题的研究:我们如何创建一个能够按照人类意愿行事的代理?基于这一定义,我们将LLMs的偏好学习视为旨在实现对齐的一类方法。本论文的范围仅限于文本偏好对齐,不涉及其他广为人知的对齐话题,如幻觉、多模态对齐和指令微调。(2) 从人类反馈中进行强化学习(RLHF):与RLHF不同,本论文的范围不仅包括基于强化学习的方法,还涵盖了传统的基于监督微调(SFT)的方法。此外,我们采用了一个统一的视角来研究基于强化学习和监督学习的方法。
结论
在本综述中,我们将偏好学习的策略分解为几个模块:模型、数据、反馈和算法。通过根据它们的变体区分不同的策略,我们构建了一个统一的偏好学习策略视角,并在它们之间建立了联系。我们认为,尽管这些对齐算法的核心目标本质上是相似的,但它们的表现可能在不同的应用场景中有显著差异。我们将探索哪种变体在特定背景下表现更好作为未来的研究工作。最后,我们希望本综述能够为研究人员提供对偏好学习的进一步理解,并激发该领域的更多研究。
