

多模态数据是信息科学领域的常见数据形态,如何有效融合不同模态信息进行分析决策是该领域的重要科学问题。从学习范式来看,现有传统多模态学习范式往往忽视了特征间的关联关系信息和特征的高阶信息;深度多模态学习范式则面临数据饥渴、融合过程语义解释性不强问题。尽管面向多模态信息处理已取得了一些进步,但仍然面临着不同模态语义统一表示难、融合效果提升难等挑战(图1)。
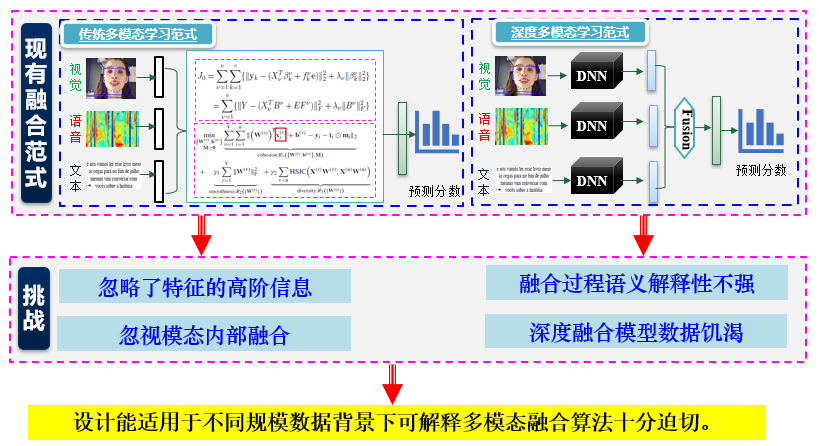
图 1 现有多模态学习范式面临的挑战
针对多模态机器学习面临的挑战,该研究通过采用将特征间的关联关系信息和高阶信息耦合到原数据空间的技术路线(图2),提出了关联关系驱动的融合方法(AF)。该方法首先使用具有语义的幂次函数来建模原始数据的高阶信息来提升数据的非线性表达能力,得到一个增强的特征空间;然后通过计算任意两个特征间的相关性得到关系融合矩阵,使用该融合矩阵将增强的特征空间映射到一个关联关系空间。与主流方法深度学习采用基于学习策略建模数据的非线性相比,AF提供了使用具有语义的函数建模数据非线性能力的新视角;此外,与深度学习采用学习策略得到融合参数矩阵方式相比,AF采用基于统计方法的关联指标计算特征间关系,该策略不仅具有语义,而且没引入额外的学习参数。AF所采用的建模数据非线性能力的方式有望为缓解现有深度学习模型面临的解释性瓶颈问题提供新视角。
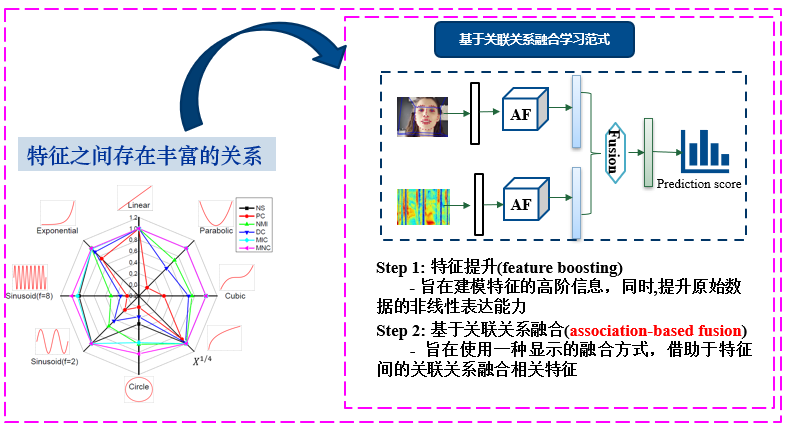
图 2 关联关系驱动的多模态融合理论与方法
总的来说,AF方法不仅将不同模态统一表示到语义一致的关联关系空间,也是一个可嵌入现有任意的多模态模型中的通用融合框架,为多模态融合领域面临的语义鸿沟瓶颈问题提供了一个有效解决方案。实验表明,耦合了关联关系的新表示具有更强区分能力(图3)。
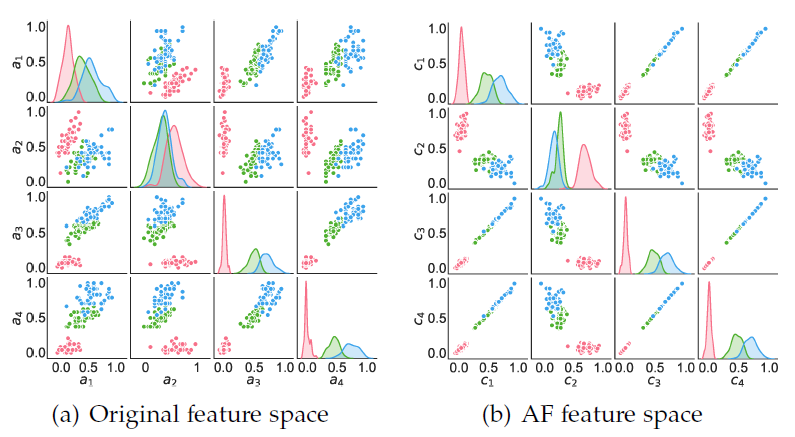
图 3 Iris 数据集在原始空间和 AF 空间中的散点图与可分性
研究团队通过耦合AF到最好模态融合、早期融合、晚期融合、模型融合以及深度模型中,提出五种增强的多模态分类算法,该方法在大量的真实数据上都统计优于增强前的方法(见图4、5)。
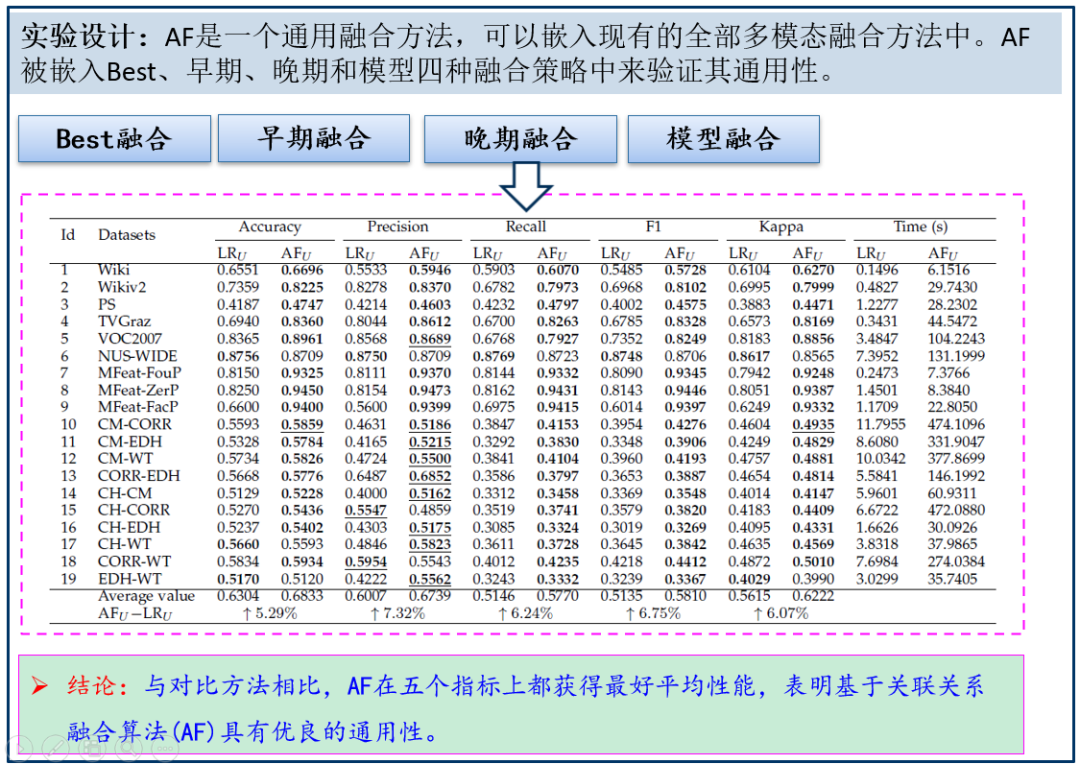
图 4 AF嵌入不同融合框架实验结果
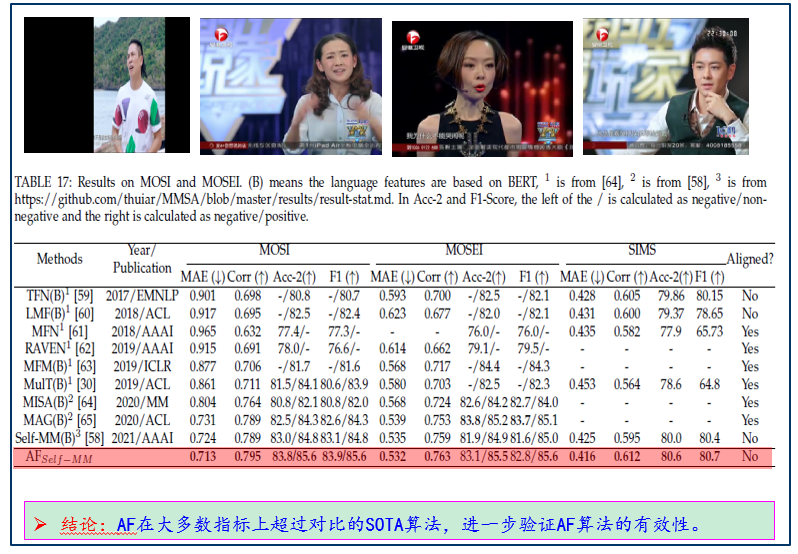
图 5 与最先进算法的比较结果
参考链接: https://news.sxu.edu.cn/jxky/6276291cb01643de87a858fc7807637b.htm

