
转载机器之心报道 编辑:陈萍、杜伟
刚刚,NLP 领域国际顶会 ACL2022 公布获奖论文信息,其中加州大学伯克利分校的增量句法表示研究被评为最佳论文。此外,最佳主题论文、杰出论文也揭晓。
ACL 是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会组织,每年举办一次。一直以来,ACL 在 NLP 领域的学术影响力都位列第一,它也是 CCF-A 类推荐会议。今年的 ACL 大会已是第 60 届,将于 5 月 22-5 月 27 在爱尔兰都柏林举办。

2 月 24 日,ACL 2022 录用结果公布。本届大会主会议共接收了 604 篇长论文和 97 篇短论文(以 ACL 2022 公布的论文列表查询为准)。
刚刚,大会官方公布了最佳论文、最佳主题论文、杰出论文以及最佳资源论文和最佳语言洞察力论文。其中,加州大学伯克利分校的获得最佳论文奖,加拿大国家研究委员会、爱丁堡大学等机构的研究者获得最佳主题论文奖。此外,多位华人学者参与的研究被评为杰出论文,包括陈丹琦、杨笛一等的研究。
最佳论文
ACL 2022 的最佳论文(Best Paper)来自加州大学伯克利分校研究团队,该研究提出了一种增量句法表示,与当前的 SOTA 解析模型相当。

题目:Learned Incremental Representations for Parsing 作者:Nikita Kitaev, Thomas Lu 、Dan Klein 机构:加州大学伯克利分校 链接:https://aclanthology.org/2022.acl-long.220.pdf
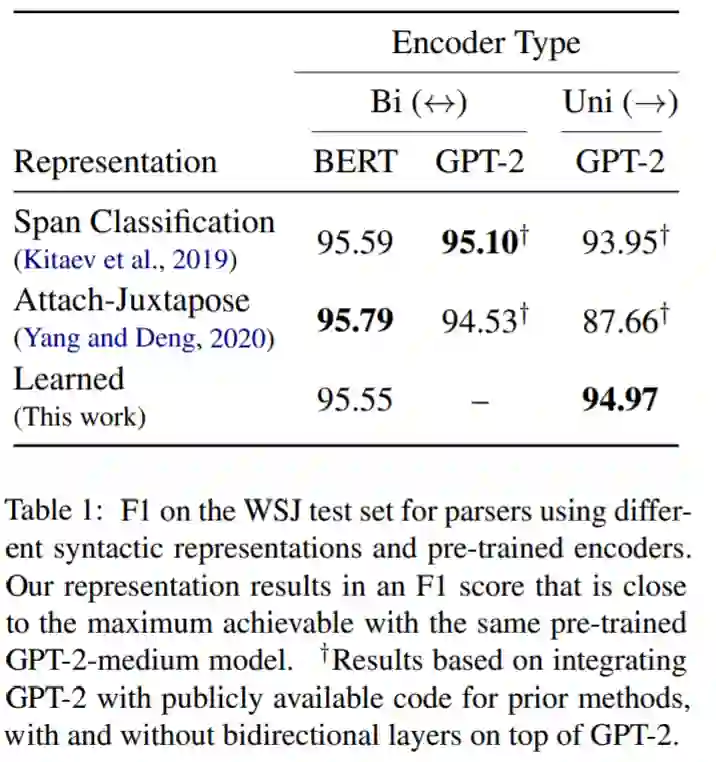
摘要:该研究提出了一种增量句法表示,该表示包括为句子中的每个单词分配一个离散标签,其中标签是使用句子前缀的严格增量处理来预测的,并且句子标签序列完全确定了解析树。该研究旨在诱导一种句法表示,它只在句法选择由输入逐渐显示时才确定这些选择,这与标准表示形成鲜明对比,标准表示必须进行输出选择,例如推测性的附件,然后抛出相互冲突的分析。
该研究学习的表示在 Penn Treebank 上达到了 93.72 F1,且每个单词只有 5 bit;在每个单词为 8 bit 时,该研究在 Penn Treebank 上达到了 94.97 F1,这和使用相同的预训练嵌入时的 SOTA 解析模型相当。该研究还对系统学习到的表示进行了分析,他们研究了系统捕获的可解释句法特征等属性,以及句法歧义的延迟解决机制。
最佳主题论文
今年的最佳主题论文(Best Special Theme Paper )研究来自加拿大国家研究委员会、爱丁堡大学、皇后大学等机构研究者,他们主要研究为低资源语音合成相关技术。

标题:Requirements and Motivations of Low-Resource Speech Synthesis for Language Revitalization
作者:Aidan Pine, Dan Wells, Nathan Brinklow, Patrick William Littell 、Korin Richmond
机构:加拿大国家研究委员会、爱丁堡大学、皇后大学
链接:https://aclanthology.org/2022.acl-long.507.pdf
摘要:该研究阐述了语音合成系统的发展动机和目的,以振兴语言。通过为加拿大使用的三种土著语言 (Kanien 'kéha, Gitksan 和 SENĆOŦEN) 构建语音合成系统,该研究重新评估了需要多少数据才能构建具有 SOTA 性能的低资源语音合成系统。例如,该研究在英语数据的初步结果表明,在训练数据上训练 1 小时的 FastSpeech2 模型可以产生与训练 10 小时的 Tacotron2 模型语音自然度相当。最后,该研究们鼓励在语音合成领域进行评估和课堂整合来进行未来研究,以实现语言复兴。
八篇杰出论文
本届会议还评出了八篇杰出论文(Outstanding Papers),佐治亚理工学院交互计算学院助理教授杨笛一(Diyi Yang)、普林斯顿大学计算机科学系助理教授陈丹琦等人的研究在列。
论文 1:Evaluating Factuality in Text Simplification

作者:Ashwin Devaraj、William Berkeley Sheffield、Byron C Wallace、Junyi Jessy Li
机构:德克萨斯大学奥斯汀分校、东北大学
论文地址:https://arxiv.org/pdf/2204.07562.pdf
摘要:自动简化模型旨在使输入文本更具可读性,但此类模型会在自动简化的文本中引入错误。因此,研究者提出了一种错误分类法,用来分析从标准简化数据集和 SOTA 模型输出中提出的参考资料。
论文 2:Online Semantic Parsing for Latency Reduction in Task-Oriented Dialogue
作者:Jiawei Zhou、Jason Eisner、Michael Newman、Emmanouil Antonios Platanios、Sam Thomson
机构:哈佛大学、微软
论文地址:https://aclanthology.org/2022.acl-long.110.pdf
摘要:标准对话语义解析将完整的用户话语映射到可执行程序中,然后执行该程序以响应用户,速度可能很慢。研究者过在用户仍在说话时预测和执行函数调用来减少延迟的机会,并引入了在线语义解析任务,采用受同步机器翻译启发的规范延迟减少指标。此外,他们还提出了一个通用框架。
论文 3:Learning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation
作者:Xiangpeng Wei、Heng Yu、Yue Hu、Rongxiang Weng、Weihua Luo、Rong Jin
机构:阿里达摩院、中科院信息工程研究所、中国科学院大学
论文地址:https://arxiv.org/pdf/2204.06812v1.pdf
摘要:监督神经机器翻译(NMT)的主要任务是学习生成以来自一组并行句子对的源输入为条件的目标句子,从而得到一个能够泛化到未见过实例的模型。然而,通常观察到模型的泛化性能很大程度上受训练中使用的并行数据量的影响。研究者提出了一种新的数据增强范式,称之为连续语义增强(Continuous Semantic Augmentation, CsaNMT),它为每个训练实例增加了一个邻接语义区域。
论文 4:Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
作者:Yao Lu、Max Bartolo、Alastair Moore、Sebastian Riedel、Pontus Stenetorp
机构:伦敦大学学院、Mishcon de Reya LLP
论文地址:https://arxiv.org/pdf/2104.08786v2.pdf
摘要:当仅使用少量训练样本启动时,与完全监督、微调、大型、预训练的语言模型相比,GPT-3 等超大预训练语言模型展现出具有竞争力的结果。研究者证明了提供样本的顺序可以在接近 SOTA 和随机猜测性能之间产生差异:本质上,一些排列很棒,而另一些则不是。他们分析了这一现象,分析它存在于模型大小方面,与特定的样本子集无关,并且一个模型的给定良好排列不能转移到另一个模型。
因此,研究者利用语言模型的生成特性来构建一个人工开发集,并基于该集上候选排列的熵统计确定性能提示。他们的方法在 11 个不同的已建立文本分类任务中为 GPT 系列模型产生了 13% 的相对改进。
论文 5:Inducing Positive Perspectives with Text Reframing
作者:Caleb Ziems、Minzhi Li、Anthony Zhang、Diyi Yang
机构:佐治亚理工学院、新加坡国立大学
论文地址:https://arxiv.org/pdf/2204.02952v1.pdf
摘要:该研究引入了积极重构任务,在该任务中,该研究消除消极观点并为作者生成更积极的观点,而不会与原始含义相矛盾。为了促进快速进展,该研究引入了一个大规模的基准,积极心理学框架(POSITIVE PSYCHOLOGY FRAMES),其具有 8349 个句子对和 12755 个结构化注释,以根据六种理论动机的重构策略来解释积极重构。
在四位作者中,杨笛一(Diyi Yang)是佐治亚理工学院交互计算学院助理教授。
论文 6:Ditch the Gold Standard: Re-evaluating Conversational Question Answering
作者:Huihan Li、高天宇、Manan Goenka、陈丹琦
机构:普林斯顿大学
论文地址:https://arxiv.org/pdf/2112.08812v2.pdf
摘要:在这项工作中,该研究对 SOTA 对话式 QA 系统进行了首次大规模的人类评估,其中人类评估员与模型进行对话,并判断其答案的正确性。该研究发现人机(humanmachine)对话的分布与人 - 人(human-human )对话的分布有很大的不同,在模型排名方面,人类评估和黄金历史(goldhistory)评估存在分歧。该研究进一步研究了如何改进自动评估,并提出了一种基于预测历史的问题重写机制,该机制可以与人类判断更好地关联。最后,该研究分析了各种建模策略的影响,并讨论了构建更好的对话式问答系统的未来方向。
论文作者之一为普林斯顿大学博士二年级学生高天宇,师从该校计算机科学系助理教授陈丹琦。
论文 7:Active Evaluation: Efficient NLG Evaluation with Few Pairwise Comparisons
作者:Akash Kumar Mohankumar、Mitesh M Khapra
机构:微软、印度理工学院马德拉斯分校
论文地址:https://arxiv.org/pdf/2203.06063v2.pdf
摘要:在这项工作中,该研究引入了主动评估,在 13 个 NLG 评估数据集上使用 13 个 dueling bandits 算法进行了广泛的实验,涵盖 5 个任务,实验表明人工注释的数量可以减少 80%。为了进一步减少人工注释的数量,该研究提出了基于模型的 dueling bandit 算法,该算法将自动评估指标与人工评估相结合,这将所需的人工注释数量进一步减少了 89%。
论文 8:Compression of Generative Pre-trained Language Models via Quantization
作者:Chaofan Tao、Lu Hou、Wei Zhang、Lifeng Shang、Xin Jiang、Qun Liu、Ping Luo、Ngai Wong
机构:香港大学、华为诺亚实验室
论文地址:https://arxiv.org/pdf/2203.10705v1.pdf
摘要:本文采用量化方法对生成式 PLM(Pre-trained Language Models)进行压缩。他们提出了一种 token 级的对比蒸馏方法来学习可区分的词嵌入,此外,该研究还提出了一种模块级的动态扩展来使量化器适应不同的模块。在各种任务的经验结果表明,该研究提出的方法在生成 PLM 上明显优于 SOTA 压缩方法。在 GPT-2 和 BART 上分别实现了 14.4 倍和 13.4 倍的压缩率。
其他奖项
大会还公布了最佳资源论文(Best Resource Paper)和最佳语言洞察力论文(Best Linguistic Insight Paper),分别由罗马大学以及马萨诸塞大学阿默斯特分校等机构的研究者获得。
最佳资源论文:DiBiMT: A Novel Benchmark for Measuring Word Sense Disambiguation Biases in Machine Translation
作者:Niccolò Campolungo、Federico Martelli、Francesco Saina、Roberto Navigli
机构:罗马大学、SSML Carlo Bo
论文地址:https://aclanthology.org/2022.acl-long.298.pdf
最佳语言洞察力论文:KinyaBERT: a Morphology-aware Kinyarwanda Language Model
作者:Antoine Nzeyimana、Andre Niyongabo Rubungo
机构:马萨诸塞大学阿默斯特分校、加泰罗尼亚理工大学
论文地址:https://arxiv.org/pdf/2203.08459v2.pdf
参考链接: https://www.2022.aclweb.org/papers https://www.2022.aclweb.org/best-paper-awards
