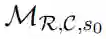摘要
对手建模是使用先验知识和观察来预测对手行为的能力。本综述全面概述了对抗领域的现有对手建模技术,其中许多必须解决随机、连续或并发动作,以及稀疏、部分可观察的收益结构。我们讨论了对手建模系统的所有组件,包括特征提取、学习算法和策略抽象。这些讨论使我们提出了一种新的分析形式,用于描述和预测博弈状态随时间的演变。然后,我们介绍了一个促进方法比较的新框架,使用所提出的框架分析了具有代表性的技术选择,并突出了最近提出的方法之间的共同趋势。最后,我们列出了几个未解决的问题,并讨论了受人工智能研究启发的对手建模和其他学科相关研究的未来研究方向。
引言
这项综述的目标有四个。首先,我们全面回顾了对抗领域中对手建模的工作。其次,我们提出了一个新的数学视角,通过它可以理解和分析两种或多种策略的相互作用。第三,我们引入了一个通用框架来比较和评估对手建模技术。第四,鉴于当前的最新技术,我们讨论了对手建模和潜在研究领域的开放问题。
对手建模的工作已用于许多现实世界的应用中,包括足球、篮球和网球等职业运动,编队预测和巡逻行为等军事任务,甚至视频游戏设计(Ontan´on et al. , 2013; Bakkes 等人, 2012)。这些技术也被应用于各种基础研究计划,其中机器人足球及其变体是其中的佼佼者。理论上,这些领域中的许多都可以使用部分可观察随机博弈 (POSG) 进行建模,并且在某些条件下,POSG 求解器可以找到可证明的最优策略。然而,许多感兴趣的场景要么太复杂以至于生成的 POSG 变得难以处理,要么没有可以写下来的收益函数,要么是因为它们太复杂,要么是因为它们只是未知。这些类型的场景需要不同的方法。对手建模研究不是完全建模问题并先验地计算最优策略,而是使用从过去经验甚至在线收集的数据,来完成或改进仅部分预定义的对手行为模型。此外,一些交互可能支持多个不兼容的均衡,检测哪些动作与当前均衡兼容需要进行对手建模。
学术文献引用了对手建模研究的许多潜在应用,为了简化不同技术和概念的讨论和比较,我们将使用一个运行示例。 RoboCup (Kitano et al., 1997) 是每年举办一次的国际机器人足球比赛,机器人团队在类似人类足球运动的比赛中相互竞争。尽管 RoboCup 及其各个部门与其他对手建模应用程序有所不同,但它保留了许多使其成为具有挑战性和有用的领域基本属性。
原则上,这些属性包括连续动作、随机动作、并发动作、稀疏且部分可观察的收益结构,以及在某些 RoboCup 联赛中,多个智能体的分散协调。例如,发送给机器人的驱动目标分别是连续的位置或速度变量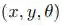
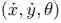
不出所料,这些特性引起了许多研究对手建模的研究人员的关注,特别是 RoboCup 模拟联盟支持了各种对手建模研究(Pourmehr & Dadkhah,2011)。从这里开始,我们将使用基于 RoboCup 的示例来说明概念,并且由于这个基础,我们将与决策制定和预测相关的一组变量(包括完全可观察的和部分可观察的)称为“博弈状态” Y。尽管本次综述中提出的大多数研究并未同时表现出上述所有属性的问题,例如一些方法假设离散动作、确定性动作、回合制博弈等,但在研究问题公式如何演变以利用问题各个方面的额外信息或确定性方面,存在有价值的视角。 Albrecht & Stone (2018) 也讨论了其中的一些研究,尽管我们更关注对抗领域,特别是各种方法如何模拟博弈状态的演变。
个人对手建模方法在实践中运作良好所需的高度专业化,通常掩盖了文献中存在的趋势和模式。此外,由于个别论文专注于其应用的特定领域方面,因此可能难以识别长期限制或更广泛地揭示对手建模研究中的隐含假设。我们认为对手建模研究有巨大的进步潜力,特别是随着无监督学习技术的不断改进,以及许多现实世界的问题,如军事行动、保护工作和视频游戏娱乐,将大大受益于提高对手性能的进展建模系统。此外,许多其他多智能体应用领域可能会受益于对手建模的进步,因为这些领域通常仍然需要对另一个智能体的隐藏状态进行建模。相反,我们也认为来自其他研究领域的见解可以激发对手建模的创新。
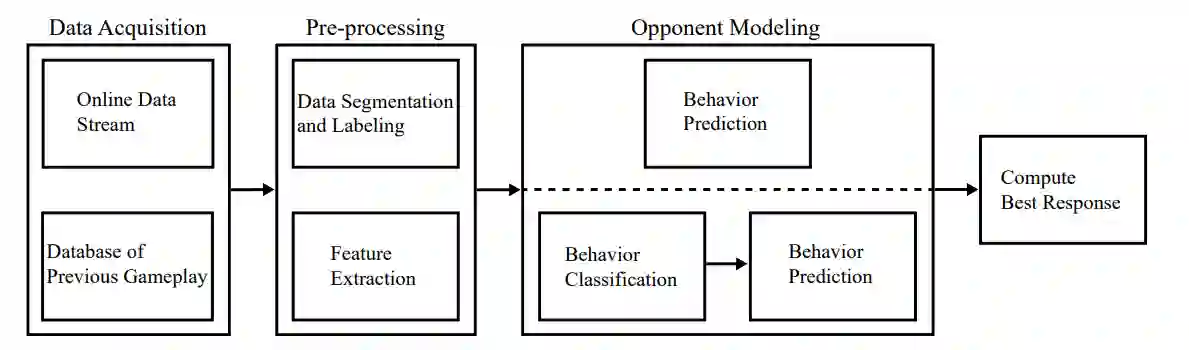
图 1:对手建模管道概述。所有对手建模系统都从以前的博弈过程中收集的数据开始,或在操作期间收集数据,或两者兼而有之。大多数系统都需要一个预处理步骤,其中使用特征提取或分割和标记技术对数据进行扩充或转换,以便正确格式化数据以供后续学习或推理。一些管道同时使用特征和标签。行为预测要么直接完成,要么在分类步骤之前进行,其中对手行为被映射到抽象类,然后使用类标识来预测行为。最后,预测的行为用于计算响应。基于行为预测而不是预测本身的准确性来衡量响应效果的实验在文献中的代表性不足。
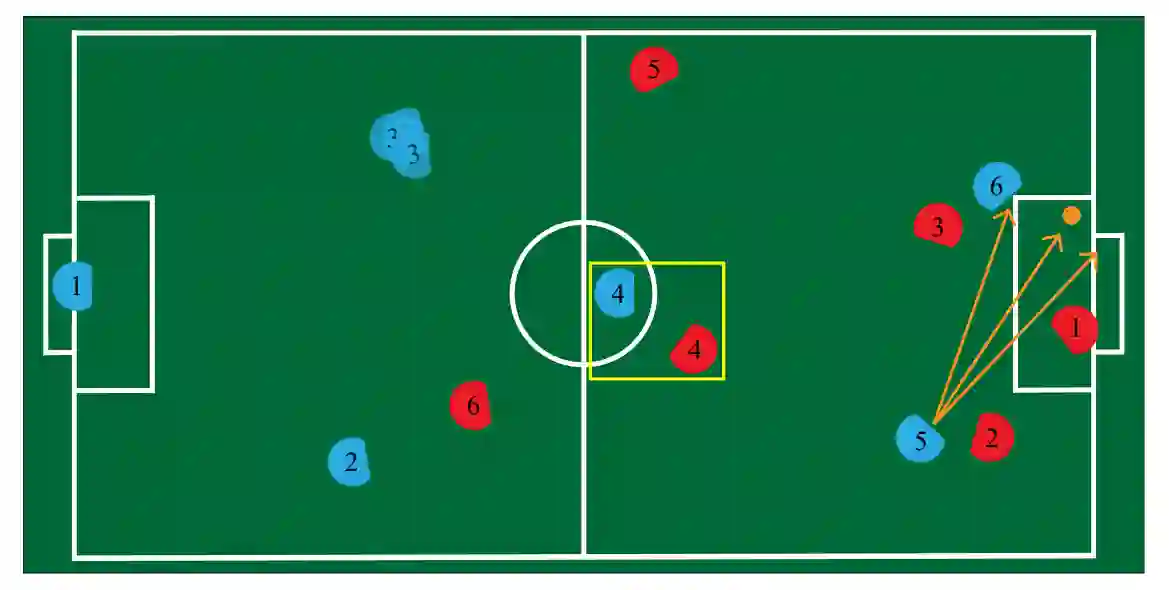
图 2:收集对手建模系统的数据处理挑战。从左到右:蓝色的机器人 3 显示了传感器输入到大多数现实世界对手建模系统的不确定、含噪的性质。黄色方框中的这对机器人与右边紧密关联。确定它们是否提供有用的信息具有挑战性。最右边的橙色箭头代表机器人 5 可能踢过的可能轨迹,中间的轨迹代表测量的内容。显然,传球或射门是有意的,但很难贴上正确的标签。
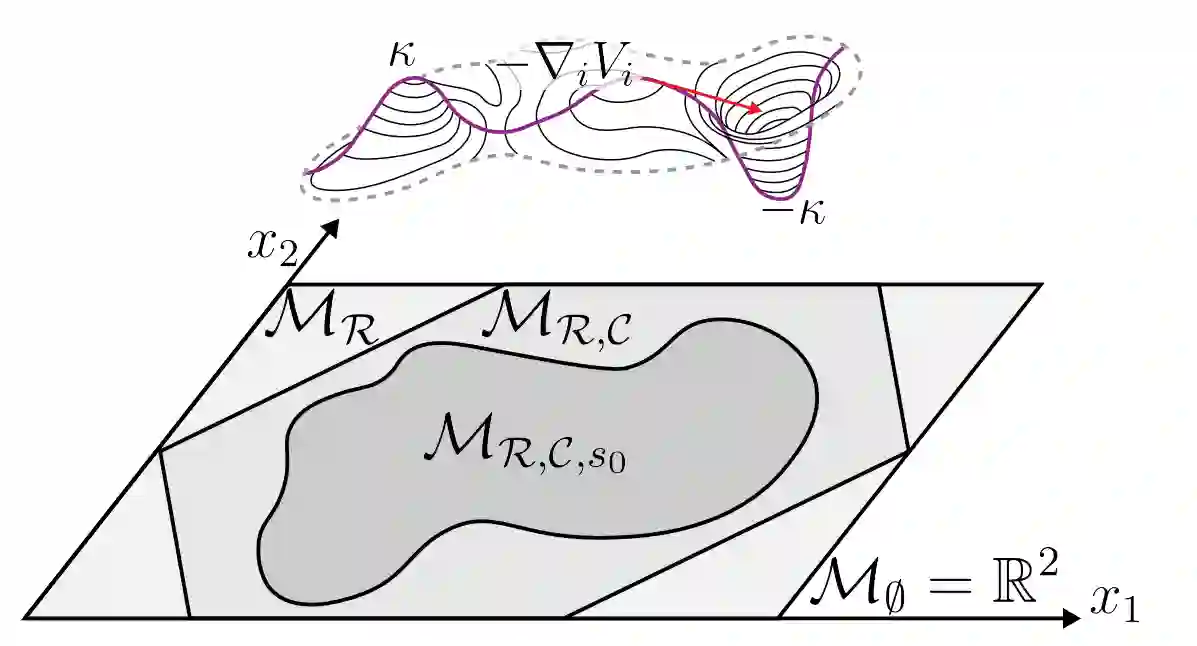
图 3:假设博弈状态和策略流形的几个不断约束的版本图示。在图的顶部,显示了水平曲线,表示策略流形