人工智能(AI)系统可以被定义为像人类一样理性思考和行动的系统(Bellman, 1978; Kurzweil et al., 1990; Schalkoff, 1991; Rich and Knight, 1992; Winston, 1992; Haugeland, 1997; Russell and Norvig, 2005)。虽然这个词在1956年著名的达特茅斯会议上被正式创造出来(McCarthy et al., 2006; Woo, 2014),追溯到亚里士多德和柏拉图的哲学家都在考虑制定法则来管理大脑的理性部分。创造智能系统的想法激发了神话的灵感,比如塔洛斯的故事,神创造了一个巨大的青铜机器人,它携带着神秘的生命来源,守护着克里特岛(Shashkevich, 2019)。从那时起,心理学家、行为学家、认知科学家、语言学家和计算机科学家一直支持各种理解智能和开发人工智能系统的方法。
对当前机器学习系统的一个关键批评是,它们往往是数据饥渴的(Marcus, 2018;福特,2018)。以GPT-3模型(Brown et al., 2020)为例,这是一个大规模的语言模型,使用来自文本数据源的300B令牌进行训练,这些文本数据源包括Common Crawl corpus (Raffel et al., 2019)(过滤和清洗后的570 GB数据)、WebText (Radford et al., 2019)、两个基于互联网的图书语料库和Wikipedia页面。这些数据集必须经过管理和处理,才能为训练模型提供有意义的学习信号。虽然最近在自监督学习方面的进展已经减少了对大规模、干净和标记良好的数据集的依赖,但我们仍然需要考虑训练前的大规模模型的时间和成本。例如,GPT-3模型使用的计算相当于3.14e 23 flops2,在单个NVIDIA Tesla V100 GPU上训练GPT-3需要355年。ML系统的样本效率明显落后于人工,使得它们的开发和部署成本很高。
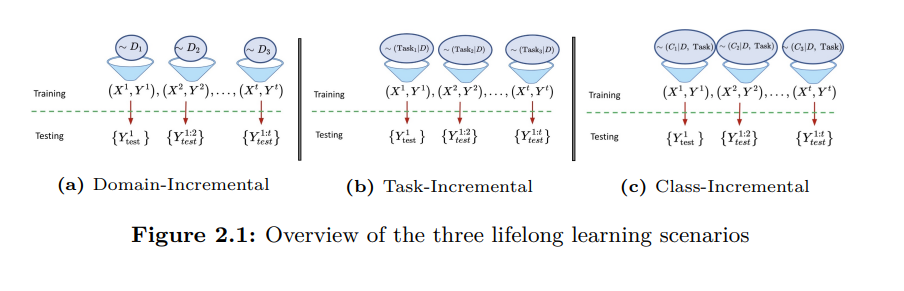
终身学习范式是人工智能的一个分支,它专注于开发终身学习系统——这种系统在一生中不断积累新知识,而不忘记先前的知识,并使用这些积累的知识来提高他们在不同任务中的表现。我们要强调的是,终身学习模式不仅适用于多任务设置,也适用于单任务设置。终身学习是一种普遍的设置,因为它对任务(或任务)的假设较少。考虑一个标准的单任务监督学习设置,学习者可以在开始训练之前访问整个数据集。在这种情况下,学习者可以对数据集执行多个epoch,对每个epoch的数据进行变换,以保持数据分布i.i.d(独立和同分布)。然而,在这个设置中有许多隐含的假设—因为我们事先可以访问数据集,所以我们知道数据集中存在多少唯一的类。我们也可以访问类的分布,并可以以不同的方式衡量类。我们还可以对数据进行多采样/少采样。虽然这些假设使训练的设置变得可行,但它们也使更一般的开放式学习设置偏离了设置。如果我们不假设访问数据集(甚至是独特类的数量),人工智能系统将不得不应对挑战,如在看到新类时修改网络架构,在训练新数据点时不忘记旧数据点,以及在新数据不断输入时潜在地增加系统的容量。所有这些挑战都是在终身学习的范式下研究的。
本入门书试图对终身学习的不同方面提供一个详细的总结。我们从第2章开始,它提供了终身学习系统的高级概述。在本章中,我们讨论了终身学习的主要场景(2.4节),介绍了不同终身学习方法的高层次组织(2.5节),列举了理想的终身学习系统(2.6节),讨论了终身学习与其他学习模式的关系(2.7节),描述了用于评估终身学习系统的常用指标(2.8节)。这一章对终身学习的新读者更有用,并希望在不关注具体方法或基准的情况下了解该领域。
其余章节集中在特定方面(学习算法或基准),对于寻找特定方法或基准的读者更有用。第3章主要讨论基于正则化的方法,这种方法不需要从以前的任务中访问任何数据。第四章讨论了基于记忆的方法,通常使用重放缓冲区或情景内存来保存不同任务的数据子集。第5章集中讨论了不同的体系结构家族(及其实例),这些体系结构家族被提议用于训练终身学习系统。在这些不同类别的学习算法之后,我们讨论了终身学习常用的评估基准和指标(第6章),并在第7章结束了对未来挑战和重要研究方向的讨论。
其余章节集中在特定方面(学习算法或基准),对于寻找特定方法或基准的读者更有用。第3章主要讨论基于正则化的方法,这种方法不需要从以前的任务中访问任何数据。第四章讨论了基于记忆的方法,通常使用重放缓冲区或情景内存来保存不同任务的数据子集。第五章集中讨论了不同的体系结构家族(及其实例),这些体系结构家族被提议用于训练终身学习系统。在这些不同类别的学习算法之后,我们讨论了终身学习常用的评估基准和指标(第6章),并在第7章结束了对未来挑战和重要研究方向的讨论。