

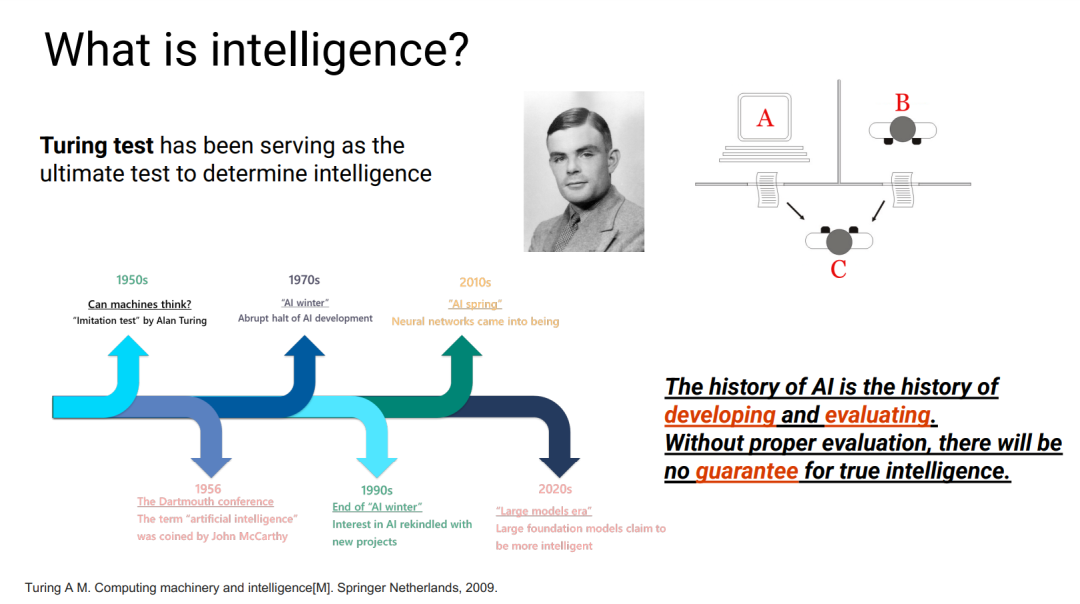
随着大型语言模型(LLMs)的快速发展,关于其安全性和风险的担忧日益增加,这主要源于对其能力和局限性的理解不足。在本教程中,我们的目标是通过呈现全面的LLM评估概述来填补这一空白。首先,我们从“什么”、“哪里”和“如何评估”这三个角度,讨论了LLM评估的最新进展。接着,我们介绍了LLM评估中的几个关键挑战,如数据污染和固定复杂度。基于这些挑战,我们介绍了如何克服这些问题。之后,我们展示了如何在不同的下游任务中评估LLMs,包括自然科学和社会科学,接着是一些流行的代码库和基准测试。我们希望学术界和工业界的研究人员继续努力,使LLMs更加安全、负责任和准确。 https://llm-understand.github.io/

成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日