编译 | 姜晶
审稿 | 许俊林 本文介绍由美国俄亥俄州立大学医学院Qin Ma副教授团队和美国密苏里大学哥伦比亚分校许东教授团队联合发表在Nature Communications的研究成果。本文作者提出了scDEAL,这是一个通过整合大规模bulk细胞系数据在单细胞水平上预测癌症药物反应的深度迁移学习框架。scDEAL的亮点在于协调药物相关的bulk RNA-seq数据与scRNA-seq数据,并通过迁移学习把在bulk RNA-seq数据上训练的模型用以预测scRNA-seq中的药物反应。scDEAL的另一个特点是整合梯度特征解释来推断耐药机制的特征基因。作者在六个scRNA-seq数据集上对scDEAL进行了基准测试,并通过三个专注于药物反应标签预测、基因特征识别和伪时间分析的案例证明了模型的可解释性。作者相信scDEAL可以帮助研究细胞重编程、药物选择和再利用以提高治疗效果。

1 简介 癌症的药物治疗因不同状态或细胞命运之间的癌症异质性而导致治疗效率低和复发率高。这种异质性是导致单个细胞对药物产生不同反应的原因,从而导致体内仍存在极少数量的癌性残留物,最终导致癌症复发。单细胞RNA测序(scRNA-seq)技术为发现癌症亚群对特定药物的异质基因表达提供了前所未有的机会。现有的针对bulk数据开发的药物反应预测方法不能直接用于单细胞数据,因此,迫切需要在单细胞水平上开发推断癌症药物反应的计算方法。然而,开发用于预测单细胞药物反应的基于深度学习的工具面临的主要障碍是由于公共领域的基准数据数量有限,训练能力不足。幸运的是,深度迁移学习(DTL)可以将知识和关系模式从bulk数据迁移到单细胞数据中。DTL模型已作为一种有效的策略应用于多个bulk数据进行癌症药物反应预测;然而,到目前为止,其将bulk水平上的知识迁移到单细胞水平上的能力尚未得到充分研究。
作者通过调整域自适应神经网络(DaNN)来开发scDEAL(单细胞药物反应分析),根据bulk和scRNA-seq数据预测药物反应。scDEAL在预测单细胞水平的药物敏感性方面非常强大,因为它在药物敏感性、单细胞的基因特征和bulk样本的基因特征之间建立了桥梁。scDEAL突出了以下几个方面:(i)它可以使用来自癌症药物敏感性基因组学(GDSC)数据库和癌细胞系百科全书(CCLE)的大量bulk RNA-seq药物反应信息来训练和优化模型;(ii)为了考虑bulk数据和scRNA-seq数据之间的数据结构差异,scDEAL协调单细胞和bulk数据的嵌入,以确保药物反应标签可从bulk数据转移到单细胞数据;(iii)为了避免在scRNA-seq数据中丢失异质性,scDEAL在每个训练epoch代入细胞簇标签;(iv)scDEAL整合梯度解释推断药物反应预测的特征基因,从而提高了模型的可解释性。作者对六个基准药物治疗的scRNA-seq数据进行综合分析和评估,scDEAL在预测细胞类型药物反应方面上有高准确率。作者通过追踪和累积DTL模型中每个神经元的积分梯度,进一步识别被认为直接导致细胞中药物敏感性或耐药性的基因特征。最后,证明预测的药物反应与治疗程序的表达轨迹很好地吻合。总体而言,作者相信scDEAL能够在单细胞药物反应预测中部署DTL模型,这可能有利于药物开发、再利用和癌症治疗选择研究。
2 结果 scDEAL框架概述 首先,scDEAL在bulk水平上对基因表达特征和药物反应之间的关系进行建模;然后,识别单细胞和bulk数据之间共享的低维特征空间,以协调两种数据类型之间的关系。通过共享的低维特征空间捕获bulk水平的基因表达-药物反应关系。训练DTL模型来学习上述两种关系的优化方案。最后,单细胞-药物反应关系可以通过DTL模型中的单细胞水平的基因表达、bulk水平的基因表达和药物反应的元关系来建立。总体而言,scDEAL可以推断单个细胞的药物反应,而无需在单细胞水平上进行监督训练(图1a)。
scDEAL框架包括五个主要步骤:(1)提取bulk基因特征,(2)使用在步骤1中提取的特征预测每个bulk细胞系中的药物反应,(3)提取单细胞基因特征,(4)联合训练和更新前面步骤中的所有模型,(5)将训练好的模型迁移并应用到scRNA-seq数据以预测药物反应(图1b)。scDEAL的训练由一个仅使用bulk数据确定bulk特征降维和药物反应预测的初始参数的源模型,以及一个包含scRNA-seq数据并部署迁移学习策略来训练和更新单细胞药物反应预测的整个框架的目标模型组成。训练了两个去噪自动编码器(DAE),以分别从bulk数据和scRNA-seq数据中提取低维基因特征;DTL模型以多任务学习的方式同时更新两个DAE模型和预测器模型。该框架协调bulk表达数据和scRNA-seq数据,并将可信的基因-药物关系从bulk水平迁移到单细胞水平。scDEAL的输出是预测的单个细胞的潜在药物反应。
模型训练的关键挑战之一是在协调scRNA-seq数据与bulk数据时保持单细胞异质性。为了解决这种挑战,作者应用了两种策略。首先,由于bulk RNA-seq和scRNA-seq数据中的噪声特征非常不同,使用DAE模型,而不是常见的自编码器或变分自编码器,在特征降维之前在bulk和scRNA-seq中诱导噪声。通过这种方式,可以避免不平衡训练的风险,这种风险只会迫使scRNA-seq数据中的基因表达接近于bulk RNA-seq数据。其次,整合了细胞聚类结果以正则化scDEAL的整体损失函数,以便在训练过程中保留细胞异质性。
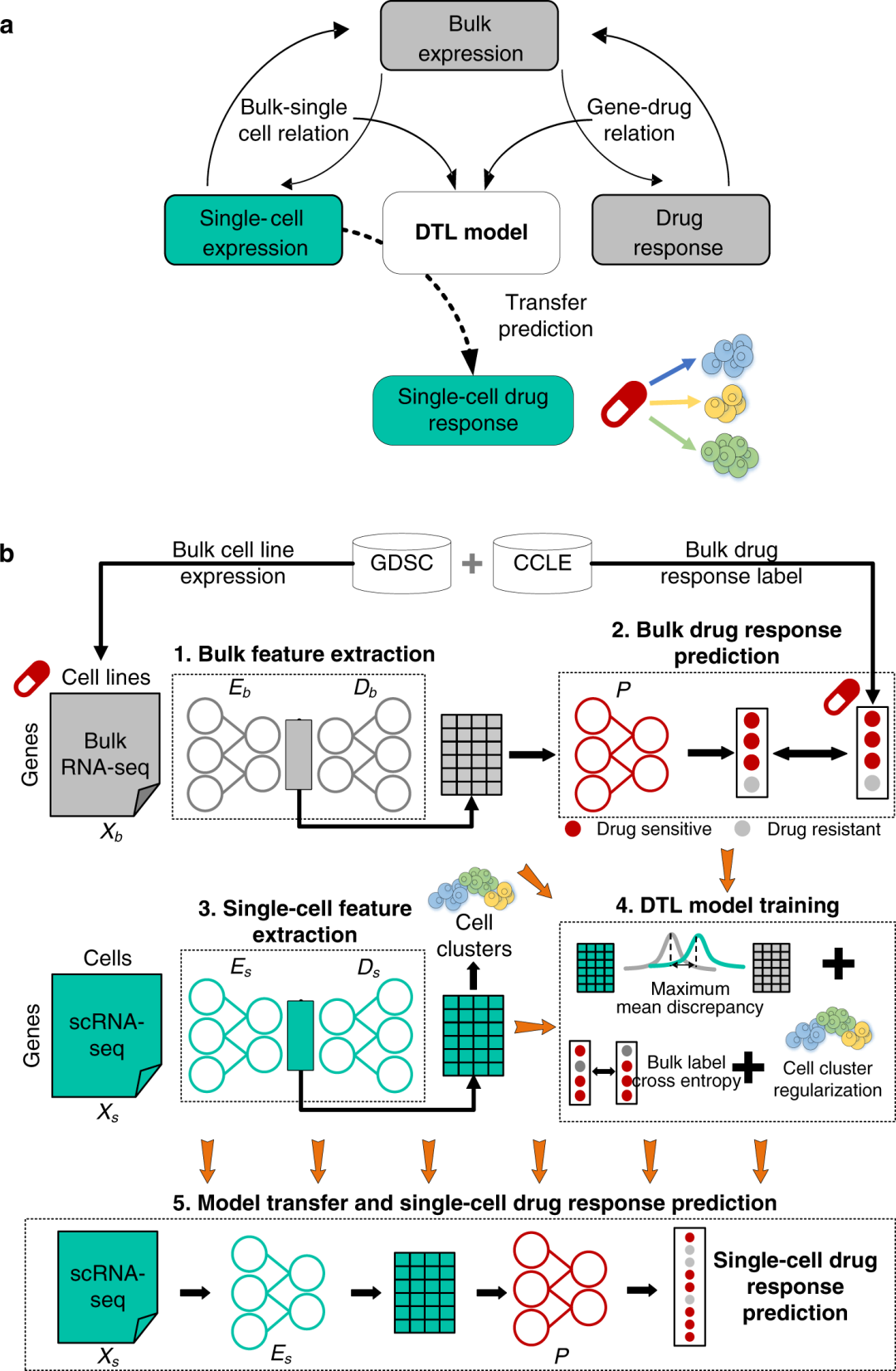
图1 scDEAL框架
在scDEAL中对单细胞药物反应预测进行基准测试 作者评估了由五种药物(即顺铂、吉非替尼、I-BET-762、多西他赛和埃罗替尼)治疗的六个公共scRNA-seq数据集的药物反应预测性能。所有数据集都提供了单个细胞的真实药物反应注释(即药物敏感或耐药)。ground truth标签是从原始手稿中提取的二进制指示符(0表示抗性,1表示敏感)。大多数研究根据治疗条件确定对整个细胞群的药物反应,例如,二甲基亚砜(DMSO)治疗的细胞都是敏感的,治疗后存活的细胞都是耐药的。与真实标签相比,scDEAL预测使用七个指标进行评估:F1得分、AUROC、AP得分、准确率、召回率、AMI和ARI。作者展示了基于scDEAL优化超参数在六个数据集上的F1得分、AUROC和AP得分的结果(图2a)。
如上所述,scDEAL在所有六个数据集中的单细胞药物反应预测方面取得了相当高的性能。此外,为了阐明scDEAL框架设计的基本原理,作者替换或删除了scDEAL中的特定组件,并将结果与最终框架的结果进行了比较。如果最终的scDEAL框架能够胜过所有替代模型,它将得到全面验证。
首先,通过仅在bulk数据上训练模型,直接将其用于scRNA-seq数据预测,无需步骤3(迁移学习) ,进行比较测试。对于每个数据,实验重复50次。所有六个数据集的结果显示,与不使用迁移策略相比,使用转移策略时F1得分显着增加(图2b)。比较表明,迁移学习有助于提高单细胞药物反应预测的性能。
其次,为了评估迁移模型的训练能力是否依赖于bulk资源,仅使用来自GDSC数据库、仅CCLE数据库以及GDSC和CCLE数据库的组合的bulk数据对scDEAL进行基准测试。结果表明,结合来自GDSC和CCLE数据库的bulk数据可以显著提高预测能力(图2c)。
第三,验证使用DAE和细胞类型正则化是否有助于减少单细胞异质性的损失并提高预测性能。比较使用常见的自编码器在bulk和scRNA-seq数据中提取特征的框架、使用DAE但未按细胞类型正则化的框架和最终的scDEAL框架(包括DAE和细胞类型正则化)的结果。对于所有六个数据集,在框架中使用DAE和细胞类型正则化获得了比其他两个选项更好的性能(图2d)。为了进一步阐明添加细胞类型正则化如何更好地保持scRNA-seq数据的异质性,作者使用来自具有和不具有细胞类型正则项的scDEAL的潜在表示展示了具有细胞簇和药物反应注释的细胞(图2e)。UMAP结果表明,在应用细胞类型正则项后,细胞在簇内变得更加有序和紧凑。
最后,作者展示了一个网格参数调整结果,包括6个超参数的480种组合。总体而言,结果显示单个参数选择对scDEAL性能没有显著影响。对于任何新数据集,作者建议调整bulk采样方法和瓶颈维度,因为在实现最佳预测性能时,这两个参数在六个数据集之间存在很大差异。为了评估scDEAL的鲁棒性,作者对六个数据集进行了随机分层抽样测试(n = 20) (图2f)。根据F1得分、AUROC、AP得分、精准率、召回率、AMI和ARI的变化,表明scDEAL在多次随机抽样中是鲁棒的。

图2 scDEAL的基准测试结果
scDEAL在多种I-BET治疗条件下对白血病细胞的的药物反应预测结果良好 作者展示了scDEAL对数据6的分析能力,包括用BET抑制剂(I-BET)处理的1419个混合谱系白血病-AF9(MA9)白血病细胞(图3a)。接下来,引入一个基因评分来反映敏感(或抗性)细胞簇中鉴定的差异表达基因的整体基因表达水平。分数背后的假设是准确的预测会给细胞分配正确的反应标签。因此,用于准确预测的抗性和敏感状态之间的DEGs基因评分应与源自ground truth的DEGs相关。此外,作者的DEG显示的基因评分模式可以比使用真实标签识别的DEG更好地区分抗性和敏感细胞(图3b)。对于敏感的DEG列表,预测的DEG分数与地面真实DEG分数之间的相关性高达R2 = 0.90,对于抗性DEG列表,R2 = 0.77(图3c)。作者进行了经验零模型检验来评估相关性的显著性。随机选择与作者预测的DEG相同数量的基因,并如上所述计算相关性1000次。经验检验(n = 1000)结果显示,对敏感和抗性DEG评分相关性的p值低于0.001,表明作者的相关性显着且具有统计学意义(图3d)。
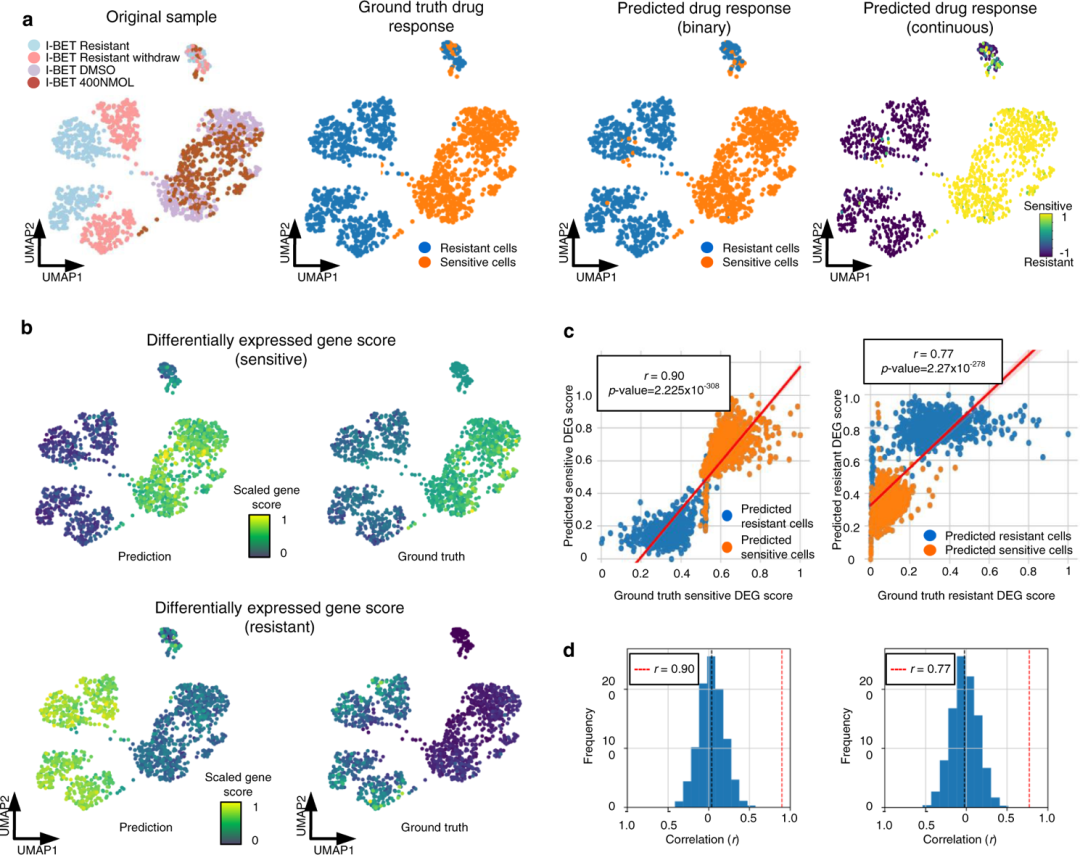
图3 I-BET治疗的数据6的案例研究
scDEAL可以识别负责药物反应的关键基因 尽管scDEAL对单细胞药物反应提供了准确的预测,但对模型中活跃的遗传特征的理解是必不可少的。作者在数据1中对顺铂治疗的口腔鳞状细胞癌(OSCC)进行了scDEAL分析。顺铂通过与DNA上的嘌呤碱基相互作用产生DNA交联来发挥其抗癌活性,干扰DNA复制并导致额外的有害DNA双链断裂,如果不修复,会导致癌细胞凋亡。因此,任何可以增强DNA修复或/和抑制细胞凋亡的因素都能够使癌细胞对顺铂治疗产生抗性。使用scDEAL,85%的细胞被正确预测为对顺铂敏感或耐药 (图4a)。调整后的p值<0.05、log-fold变化<0.1且在任何一个比较组中细胞百分比高于0.2的基因被定义为影响药物反应的关键基因(CG)。在HN120P(敏感细胞组)中识别出936个药物敏感CGs,在HN120PCR(顺铂治疗四个月后的耐药细胞组)中识别出868个耐药CGs,IG评分差异显著(图4b)。作者观察到几种预测最高的抗性CG,例如BCL2A1和DKK1,具有抗凋亡活性(图4c)。已证明这些基因的过表达介导对顺铂的抗性。
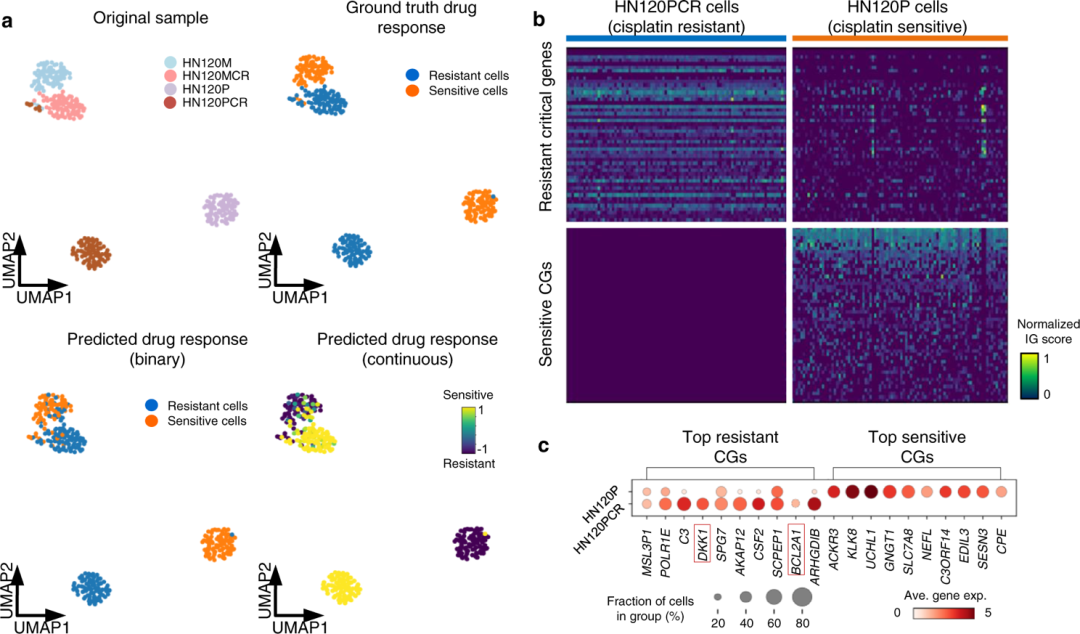
图4 具有顺铂药物反应的数据1的scDEAL案例研究
scDEAL药物反应预测与伪时间分析高度相关 应用Monocle3对数据6(用I-BET治疗)进行轨迹推断,以验证作者预测的药物反应是否与药物治疗的进展相关。基于基因表达的伪时间分析显示了从DMSO样品开始向1000ml I-BET治疗样品的轨迹趋势(图5a)。当将伪时间结果与相同扩散UMAP上的药物反应进行比较时,观察到DMSO对照对治疗样品的抗性增加(图5b)。这些结果表明,在高剂量药物后测序的剩余活细胞表现出显着的药物耐受性,这也与实验药物反应标签(ground-truth标签)非常吻合。除了预测和轨迹拓扑之间的一致性外,作者还进一步解释了scDEAL中识别的CG的抗性发展趋势。作者展示了两个代表性的I-BET抗性CG的表达值,即Eid2和Galnt17(图5c),以及两个代表性的I-BET敏感基因,即Emilin1和Ramp1(图5d)。观察到这些基因的表达水平与伪时间分析的轨迹和预测的药物反应概率评分相匹配。
关于预测的CG和DEG的比较以及轨迹的进一步研究表明,预测的CG列表在区分敏感和耐药细胞状态方面具有更明显的表达(图5e)。Pearson评分与pseudotime值之间的相关性高达0.81(正相关)和-0.93(负相关),这表明scDEAL的预测可能暗示药物反应发展。敏感和耐药细胞组中的前十名CG显示出不同的表达模式,并且与伪时间分数高度相关(图5f)。总之,作者证实了scDEAL中预测的药物反应结果和CG与I-BET处理的细胞伪时间轨迹有很强的相关性。

图5 用伪时间轨迹验证预测的药物反应
3 总结与讨论 scDEAL使用bulk基因表达数据增强了scRNA-seq数据分析和解释,可用于预测癌症scRNA-seq数据和其他疾病中细胞群的药物反应。适应scRNA-seq数据的神经网络可以在bulk细胞系数据上进行初步训练。因此,可以从scRNA-seq数据预测药物敏感性。需要注意的是,scDEAL仅根据训练好的模型和scRNA-seq基因表达矩阵预测单细胞药物反应,不需要标签。
未来工作展望: * 通过整合额外的bulk数据库来更新scDEAL训练数据,提高scDEAL中预测结果的准确性。 * 增加实验验证的药物反应scRNA-seq数据,有助于确定更好的模型超参数,甚至有助于开发直接的单细胞到单细胞深度迁移学习模型。 * 跨不同物种的单细胞药物反应预测,如人类到小鼠。
scDEAL在单细胞水平上改进药物开发方面具有相当大的潜力。首先,它可用于预测药物反应并将基因特征与治疗效果联系起来。其次,CG可用于CRISPR筛选或细胞重编程的潜在目标签名。第三,它可以应用于现有的未经药物治疗的scRNA-seq数据,以预测多个细胞簇中的潜在药物反应,可以选择用于动物药物测试。从长远来看,作者相信该工作可以为细胞重编程、药物选择和再利用以及联合用药以提高治疗效果做出贡献并提供见解。
参考资料 Chen, J., Wang, X., Ma, A. et al. Deep transfer learning of cancer drug responses by integrating bulk and single-cell RNA-seq data. Nat Commun 13, 6494 (2022). https://doi.org/10.1038/s41467-022-34277-7
数据 https://www.cancerrxgene.org https://www.cancerrxgene.org/downloads/bulk_download https://www.cancerrxgene.org/gdsc1000/GDSC1000_WebResources/Home.html https://depmap.org/portal/ https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE117872 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE112274 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE140440 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE149383 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE110894