
编译 | 王海云
审稿 | 王娜 本文介绍由美国耶鲁大学统计与数据科学系的Mark Gerstein通讯发表在 Nature Communications 的研究成果:作者介绍了林火聚类,这是一种从单细胞数据中发现细胞类型的有效手段,具有良好的可解释性。林火聚类采用最小的先验假设,与当前方法不同,它计算每个细胞分配一个细胞类型标签的非参数后验概率。这些后验分布允许评估每个细胞的标签置信度,并允许计算“标签熵”,突出沿着分化轨迹的过渡。此外,作者表明,林火聚类可以在在线学习环境中进行稳健的归纳推理,并且可以很容易地扩展到数百万个细胞。最后,作者证明了该方法在模拟和实验数据的不同基准上优于最先进的聚类方法。总的来说,林火聚类是大规模单细胞分析中发现稀有细胞类型的有用工具。

1 简介 聚类分析是一种重要的统计方法,有许多应用场景。在单细胞测序中,聚类分析将单个细胞分为不同的亚型,例如将癌症细胞的亚型分类以进行靶向治疗。当前大多数聚类方法可以大致分为五大类:基于质心的方法、基于分布的方法、基于连接的方法、基于密度的方法和基于图的方法。
适用于单细胞数据的聚类算法应具有以下三个重要特征:(1)对于罕见细胞类型的发现,单细胞聚类算法应该对数据(例如数据的形状)做出相对较弱的假设;(2)单细胞聚类方法应该能够在内部验证其聚类结果;(3)单细胞聚类算法应具有较高的计算效率。
为了满足这些规范,作者根据森林火灾动力学中的自组织临界性开发了森林火灾聚类。通过模拟类似于森林火灾蔓延的标签传播,可以在仅给定一个“火灾温度”超参数的情况下(类似于Louvain中的分辨率超参数)对数据进行聚类。通过模拟来自不同起点的标签传播,可以计算与P值类似的逐点后验排除概率(PEP),以量化数据点在其他聚类标签上的概率。还可以计算逐点标签信息熵来测量每个数据点标签的一般不确定性。由于该算法的归纳性质,森林火灾聚类可以对少量新到达的数据点进行在线推断,而无需重新聚类。
2 结果 方法概述 森林火灾聚类算法有三个主要步骤:(1)预处理:使用行作为细胞、列作为基因组特征的数据矩阵W计算细胞间成对距离矩阵M。然后,使用核方法将M转换为亲和矩阵A(图1a,步骤1-2)。(2)标签传播:在数据图上,选择一个随机的未标记顶点r作为种子,以获取新标签(图1a,步骤3)。未标记顶点离种子越远,它们受到的标签影响越小。如果未标记顶点i上所有标记顶点的平均标签影响超过接受阈值,则顶点i采用种子的标签(图1a,步骤4-5)。即使不足以超过阈值,也有可能超过阈值,因为稍后会标记更多顶点(图1a,步骤6-7)。因此,每次标记新顶点时,森林火灾聚类都会检查剩余的未标记顶点,直到平均标签影响不能超过任何未标记顶点的阈值(图1a,步骤8)。(3)迭代标签传播:迭代执行新的标签传播,直到所有顶点都已标记,每轮标签传播定义一个簇(图1a,步骤9-10)。此外,可以使用蒙特卡洛模拟评估森林火灾聚类标签的置信度(图1c)。
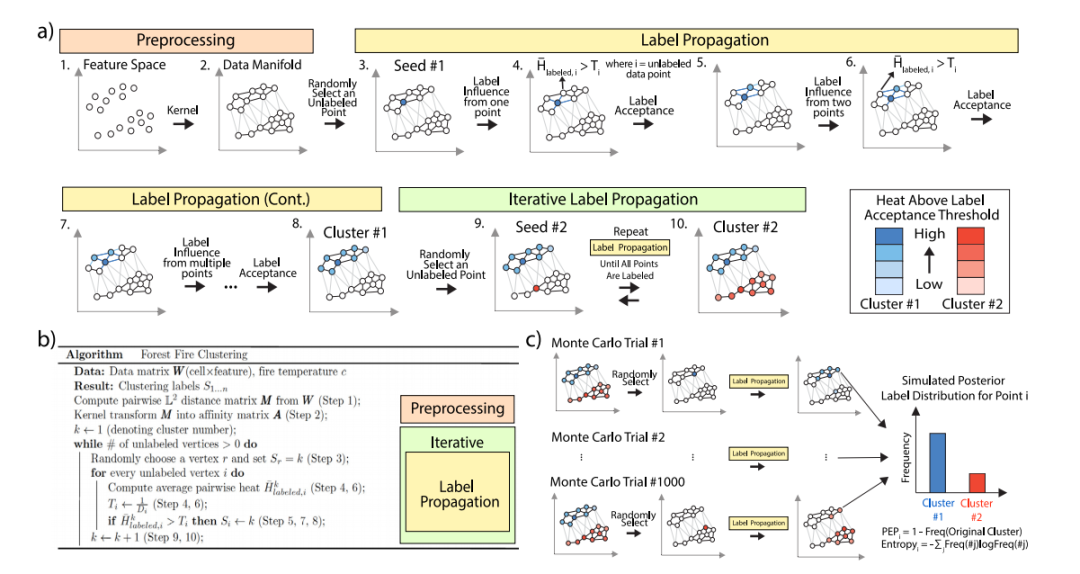
图1 森林火灾聚类和蒙特卡洛验证说明
根据合成数据评估森林火灾聚类 我们首先研究了模拟高斯混合上森林火灾聚类的性能(图2a,e)。有趣的是,还可以从平均标签影响图(图2b)中的峰值数推断出簇的数量。在高斯方差较低的情况下,每个尖峰对应于发现的一个有意义的簇。在高斯方差较高的情况下,发现了八个簇,尽管两个簇的分离与地面真实值不同(以绿色和橙色显示)。因此,随时间变化的平均标签影响图显示了这些簇的不同峰值(图2f)。为了在内部验证之前的聚类结果,作者使用蒙特卡洛模拟构建了后验标签分布,并计算了高斯混合中每个数据点的后验排除概率和标签熵(图2c,d)。验证表明,特定簇上和少数簇之间的标签熵较高。作者验证了之前的假设,即随着火灾温度c的升高,平均簇大小也会增加(图2g)。因此,火灾温度c是用于生成不同大小簇的直观参数。此外,作者在使用相同聚类数K的前提下,对森林火灾聚类和K-均值进行了比较(图2h)。随着火灾温度c的升高,林火聚类的轮廓分数收敛到K均值聚类的轮廓系数。由于K-means的轮廓分数在给定聚类数K的情况下是局部最优的,这表明森林火灾聚类可以生成具有适当火灾温度c的近似最优聚类。
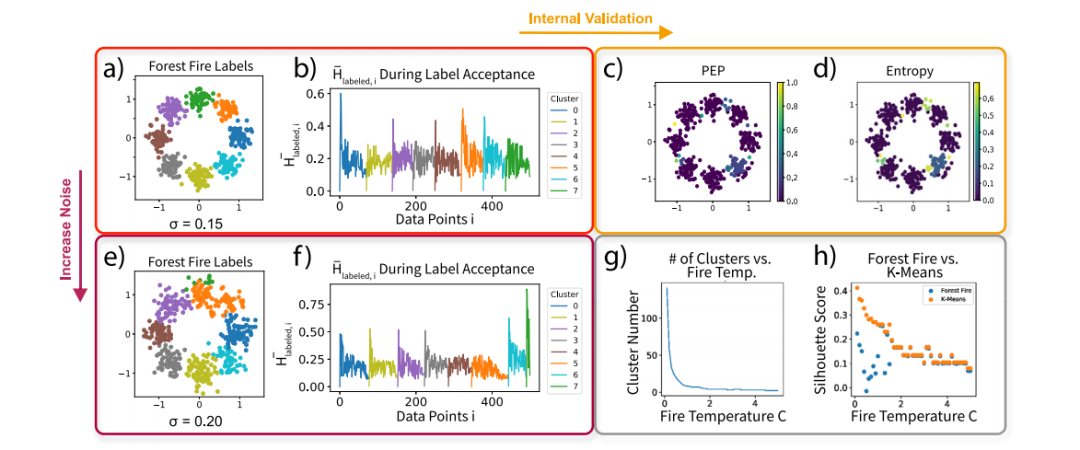
图2 用高斯混合模型可视化林火聚类过程
森林火灾聚类与其他聚类方法的比较 如前所述,林火聚类旨在克服单细胞测序数据集上许多聚类方法的缺点(图3a)。与其他聚类方法相比,林火聚类可以生成具有最小先验假设的聚类,并可以计算非参数逐点后验概率进行内部验证。除了这些独特的优势外,作者还在大量合成数据集上使用许多现有聚类方法对森林火灾聚类进行了基准测试(图3b)。对于环形或半月形数据(图3b),基于分布的方法(如高斯混合建模)无法准确分类这些数据集,纯度分数分别为0.5和0.85。基于分布和质心的方法在识别非凸聚类方面都有局限性。相比之下,林火聚类中的聚类边界更灵活,因为数据流形中的标签传播对数据的形状做出了最小的假设。此外,结果表明,与基于连通性的方法相比,林火聚类可以更好地揭示聚类的数量和大小,尤其是当聚类内距离大于聚类间距离时。当簇重叠时,我们的方法也保持了稳健的性能,而基于密度的方法,如DBSCAN和OPTICS在这种情况下表现不佳。
基于模拟scRNA-seq数据的森林火灾聚类评估 对于模拟的离散细胞类型(图4a),林火聚类在ARI和纯度分数方面优于SC3(Wilcoxon signed-rank P=)。森林火灾聚类在ARI中也优于Seurat(Wilcoxon signed-rank P=) 但纯度得分无统计学显著差异。作者观察到连续细胞类型的ARI和纯度分数表现类似(图4b)。这表明,林火聚类和Seurat都可以生成同质聚类,但林火聚类更能正确发现细胞类型和子单元的内在数量。此外,此外,森林火灾聚类在运行时的平均时间为80毫秒,分别优于SC3和Seurat,而前者为分别为12分钟和1秒(图4c)。此外,内部验证表明,细胞的标签熵与沿分化路径的伪时间步长呈负相关(图4d,e)。随着过渡细胞的分化和沿着发育轨迹变得更加特殊化,细胞的身份也变得更加明确(图4f)。因此,与许多现有聚类方法相比,林火聚类可以突出发育伪时间内的过渡种群,并为单细胞分析提供更深入的见解。
基于PBMC单细胞数据的林火聚类分析 为了证明林火聚类在实验数据上的优势,作者分析了两个数据集中约10000个外周血单个核细胞(PBMC)的单细胞测序。结果表明,林火聚类可以正确分类主要的PBMC细胞类型(图5)。聚类质量基准表明,与其他最先进的单细胞聚类方法相比,林火聚类可以始终生成具有相似ARI和纯度分数的聚类(图5d,f)。此外,林火聚类可以在不同的聚类分辨率和细胞种群大小下发现高质量的聚类(图5h)。然后,作者评估了内部验证对森林火灾集群的影响。通过关注具有高置信度标签(PEP<0.1)的细胞,森林火灾聚类可以将聚类ARI比现有方法提高20%以上(图5d、f)。此外,林火聚类可以分析连续的细胞类型。模拟研究的结果表明,随着每种细胞类型内扩散伪时间的增加,标记熵降低,扩散伪时间分析中的祖细胞与森林火灾标记熵突出显示的细胞相匹配(图5i)。
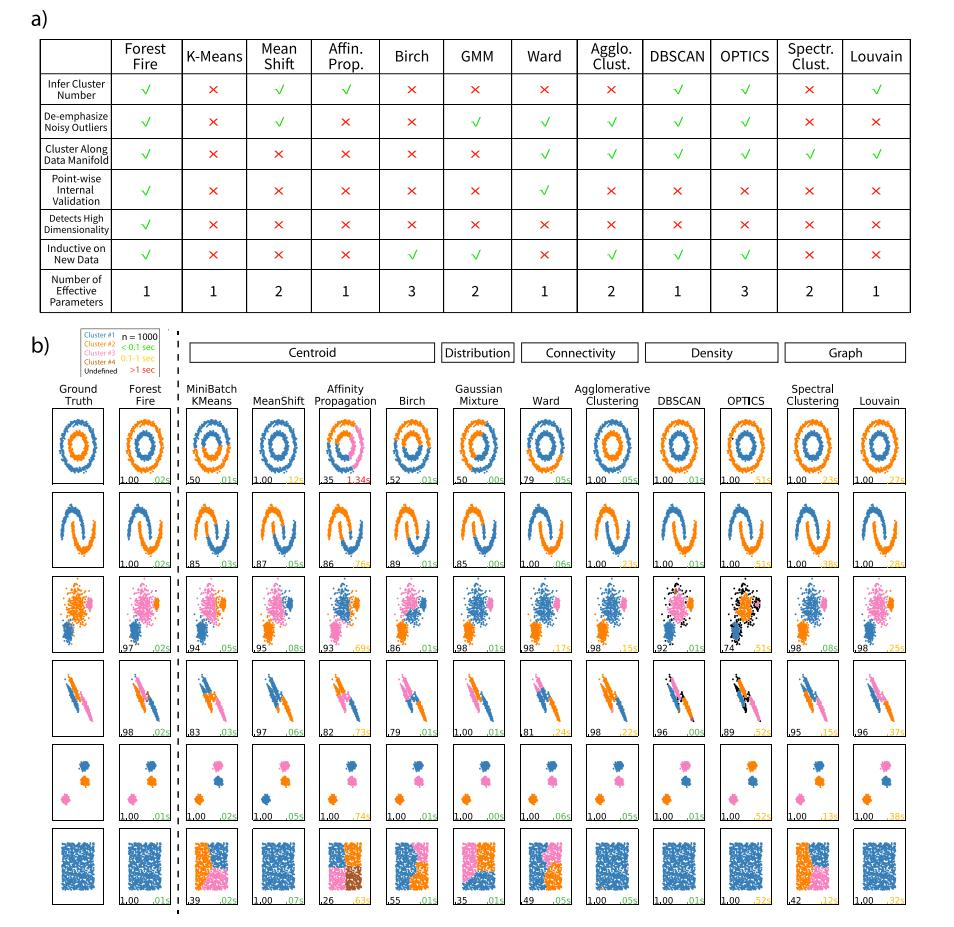
图3 林火聚类与其他聚类方法的比较
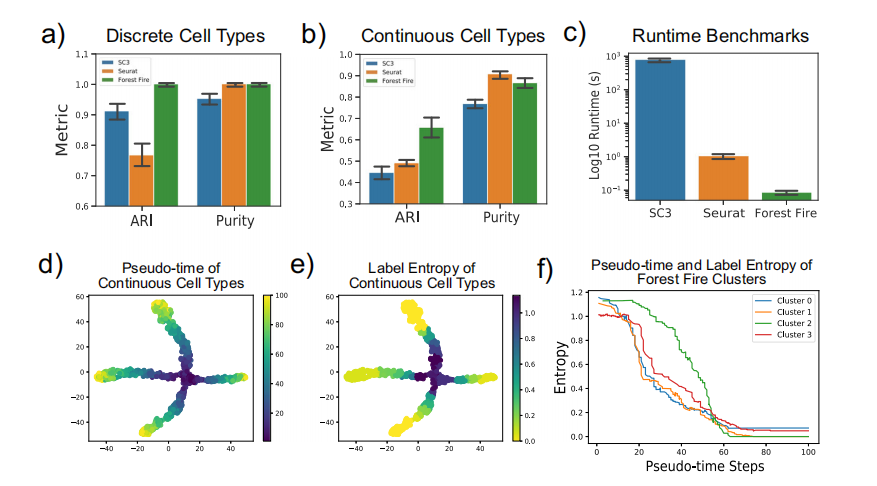
图4 模拟scRNA-seq数据分析
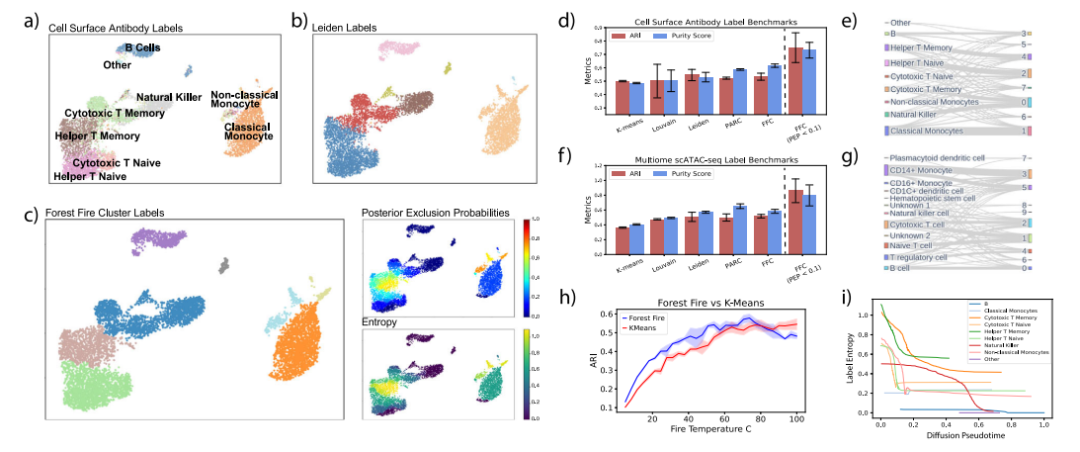
图5 基于PBMC数据的林火聚类基准测试
基于大规模小鼠单细胞数据的森林火灾聚类评估 随着单细胞测序过程中细胞数量的增加,聚类算法的可扩展性变得越来越重要。在这里,作者展示了在大型异构数据集上与其他最先进的聚类算法相比,森林火灾聚类的效率最高。结果表明,在同时生成质量相似的聚类结果的条件下,森林火灾聚类比最先进的单细胞聚类算法更快(图6d,e)。此外,与现有方法相比,森林火灾聚类使用的内存更少。运行时和内存使用基准表明,森林火灾聚类可以有效地扩展到更大的数据集。接下来,作者研究了内部验证对森林火灾集群的影响(图6e)。对于像MCA这样的异构数据集,关注具有高标记置信度(PEP<0.1)的细胞将ARI从0.38提高到0.72。此外,新生和胎儿小鼠组织表现出较高的标记熵,这支持先前的结论,即标记熵模拟发育时间(图6f)。然而,需要计算密集的蒙特卡洛模拟来获得这些新的见解。在实践中,作者发现几千次蒙特卡洛试验足以获得合理的近似值。此外,蒙特卡洛模拟具有令人尴尬的并行性,可以使用多进程以最小的同步开销有效加速。
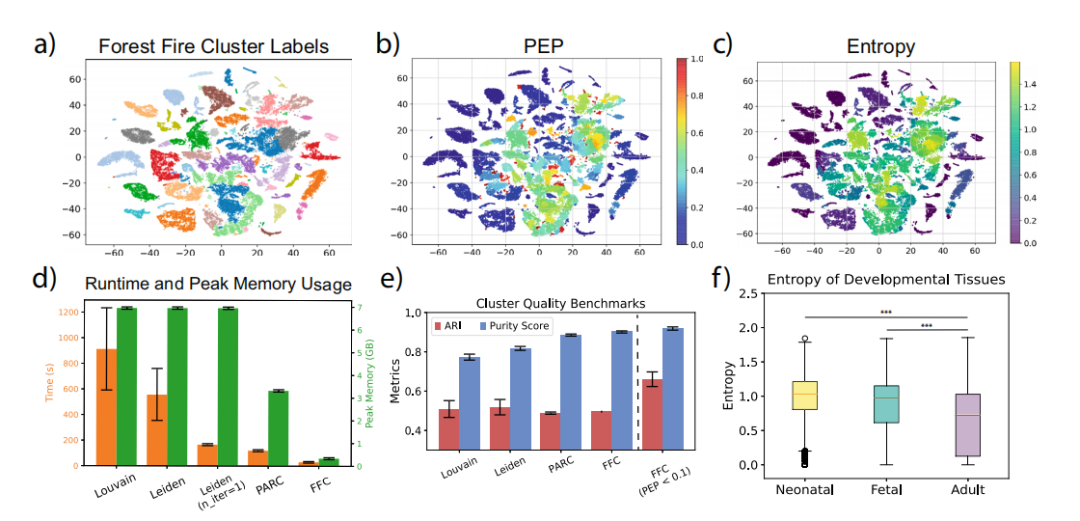
图6 基于MCA数据的森林火灾聚类基准测试
3 总结与讨论 目前,对于scRNA-seq数据无监督聚类相关的研究,存在许多公认的挑战。首先,许多聚类方法对数据进行了强大的显式或隐式先验假设。其次,现有的聚类方法无法在内部验证其聚类结果。对于单细胞分析中的罕见细胞类型发现,关键是使用最小的先验假设进行聚类,并报告每个数据点的标签置信度以进行验证。第三,虽然已知单细胞数据中存在离散细胞类型,但一些细胞可以放置在两个或多个末端状态的连续梯度中,没有明确的边界。为了解决与高维单细胞数据聚类相关的现有挑战,应专门设计聚类算法以满足单细胞分析需求。
在这里,受森林火灾动力学的启发,作者开发了森林火灾聚类。森林火灾聚类在常见基准上优于以前的聚类方法,在scRNA-seq数据集上表现出稳健的性能。此外,森林火灾聚类可以使用蒙特卡洛模拟进行内部验证。聚类标签随机传播以产生逐点后验排除概率,该概率可以量化每个数据点的标签置信度,并用作质量控制的度量。此外,逐点标记熵可以突出发育伪时间的分支点和关键过渡细胞。 参考资料 Chen, Z., Goldwasser, J., Tuckman, P., Liu, J., Zhang, J., & Gerstein, M. (2022). Forest Fire Clustering for single-cell sequencing combines iterative label propagation with parallelized Monte Carlo simulations. Nature communications, 13(1), 1-13. Doi: https://doi.org/10.1038/s41467-022-31107-8
数据 https://www.10xgenomics.com/resources/datasets http://bis.zju.edu.cn/MCA/
代码 https://github.com/gersteinlab/forest-fire-clustering https://zenodo.org/badge/latestdoi/432892882
