

物理启发的生成模型(如扩散模型)构成了一类强大的生成模型家族。该模型家族的优势在于相对稳定的训练过程和强大的容量。然而,仍有许多可能的改进空间。在本论文中,我们首先将深入探讨扩散模型在训练和采样方面的改进技术。扩散模型的训练目标在数据分布为多模态时呈现出较高的方差。为了解决这一问题,我们提出了一种训练目标,它推广了传统的去噪得分匹配方法,显著减少了训练目标的方差。除此之外,我们还引入了一种将可学习的离散潜变量整合到连续扩散模型中的训练框架。这些潜变量简化了扩散模型复杂的噪声到数据映射的学习过程。
另一方面,扩散模型的采样过程通常涉及求解微分方程。为加速采样过程,我们提出了一种新颖的采样算法,结合了之前常见的ODE和SDE采样器的优点,大幅提升了预训练扩散模型的性能。此外,我们的研究探索了在有限样本中引入互斥力以促进生成过程中的多样性。 在物理启发的生成模型领域,许多物理过程都可以用于开发生成模型。我们将介绍一类基于静电理论的新生成模型家族,称为泊松流生成模型(PFGM)。PFGM在采样稳健性上表现出色,并与领先的扩散模型相媲美。其扩展版本PFGM++将扩散模型和PFGM置于同一框架下,并引入了新的、更优的模型。我们还将提出一种系统化的方法,将物理过程转化为生成模型。
生成模型在近年来显著改变了人们工作的、创作的和学习的方式。其突出应用包括ChatGPT [1]、文本到图像模型 [2]-[4]、文本到3D模型 [5]、[6] 和文本到视频模型 [7]、[8]。这些能力可以极大地激发创造力,并提高众多领域的工作效率,包括教育、游戏产业、社交媒体和专业编辑软件。生成模型的训练基于这样一个假设,即训练数据是从未知的数据分布中采样的 [9]。现代生成模型通常使用深度神经网络来基于有限的训练数据逼近复杂的数据分布,并通过从这些建模的分布中采样来生成新的数据点。
在生成建模中使用的各种数据类型中,高维数据由于维度诅咒而面临着显著的挑战。随着维度的增加,数据空间的体积呈指数级扩展。这一现象使得在高维空间中用有限的训练数据有效捕获和建模数据分布变得困难。此外,感兴趣的数据分布通常高度复杂且呈多模态,进一步增加了生成建模的难度。近年来,扩散模型 [10]–[12] 以及更广泛的物理启发生成模型 [13],在处理高维数据的生成任务中,展现了强大的框架并取得了令人印象深刻的结果。在扩散模型之前,主要的方法包括:(i)利用对抗训练目标的生成对抗网络(GANs [14]);(ii)使用最大似然目标训练的模型,如PixelCNN [15] 和正规化流模型 [16]、[17];(iii)变分自编码器(VAEs)[18]、[19] 以及(iv)基于能量的模型 [20]、[21]。然而,每种方法都有其自身的缺点:(i)可能导致训练不稳定和生成样本的多样性低;(ii)需要特定的架构设计,可能限制模型的容量;(iii)需要多个神经网络的仔细协调;(iv)训练和采样速度较慢。利用自然的物理过程作为编码器将数据转化为噪声,扩散模型通过逆转这些物理过程来执行生成任务。这种方法使它们绕过了早期生成模型的许多限制。
1.1 通过逆转物理过程进行生成建模
基于热力学的原理 [10],扩散模型涉及两个对立的过程:一个前向过程将数据分布逐渐转化为一个更简单的先验分布,另一个反向过程通过逐步去噪从该噪声先验分布中生成样本。扩散模型中的前向过程是一个简单的布朗运动,通过逐步增加高斯噪声来降解数据。为了逆转这一过程,只需学习一个时间依赖的向量场,即得分函数,并迭代求解一个微分方程 [22]。与GANs和VAEs不同,扩散模型的训练不需要多个神经网络之间的同步,从而使训练过程更加稳定。此外,它们在架构设计上不受限,采用类似于神经网络串联的迭代过程,从而增强了整体容量。这种稳定性和增强的容量使扩散模型能够有效扩展到大规模数据集。
尽管扩散模型具有诸多优势,但它们仍面临一些挑战,包括在处理多模态数据时高方差的训练过程,以及缓慢的迭代采样过程。此外,独立同分布(i.i.d.)的采样过程往往会导致重复的样本。这些问题强调了在复杂数据集上稳定和改进扩散模型训练方法的必要性,并且需要新技术来加速采样过程并提高小批量样本的多样性。此外,扩散模型只是众多物理启发生成模型之一。除布朗运动外,仍有许多物理过程尚未开发,可以用来构建生成模型。这引出了一个重要问题:我们能否发现其他物理启发的生成模型,它们展示出更好的性能?在接下来的部分中,我们将简要总结扩散模型的改进训练和采样技术,并讨论我们开发其他物理启发生成模型的研究,这些将在后续章节中详细阐述。
1.1.1 扩散模型的改进训练技术
扩散模型的训练利用了一种扰动-去噪方法来估计向量场。其过程是先通过高斯噪声扰动干净的数据,然后网络从这些扰动样本中重构原始数据 [12]。然而,对于复杂的多模态数据,许多干净的数据点可能被扰动为相似的噪声样本,导致训练目标不明确并引发不稳定性。
在文献 [23] 中,我们通过多个干净数据点的加权求和来估计真实目标,精确地指示从扰动样本到真实向量场的方向。该新颖的训练目标推广了传统的单点估计方法,显著减少了训练目标中的方差。因此,在各种扩散模型变体中,样本质量得到了提高,训练过程更加稳定,训练速度也得到了加快。
扩散模型面临的另一个挑战是,需要学习一个从单峰高斯分布到多峰数据分布的非线性且高度复杂的映射。这种复杂性增加了训练的难度,并导致生成常微分方程(ODE)[24] 轨迹呈现强烈的曲率。为解决这一问题,我们在扩散模型中引入了离散潜变量。这些离散潜变量有助于捕获数据分布中的不同模式,而扩散模型的任务则转变为基于给定的离散潜变量捕获每个模式内的连续变化。离散与连续变化的分离建模显著简化了模型复杂的噪声到数据映射的学习过程。这一方法有效降低了扩散模型生成ODE的曲率,尤其是在较大的扩散时间下,整体训练损失得到了减少。
1.1.2 扩散模型的改进采样技术
在扩散模型的采样过程中,求解微分方程通常涉及速度和质量之间的权衡。确定性采样器(基于ODE的)[25]–[27] 速度快,但性能达到平台期,而随机采样器(基于SDE的)[27]、[28] 样本质量更好,但速度较慢。我们的分析将这种差异归因于采样误差:ODE采样器的离散化误差较小,而SDE中的随机性会收缩采样过程中的累积误差 [29]。
基于这些见解,在文献 [29] 中,我们提出了一种名为Restart的新采样算法,该算法结合了ODE和SDE的优点。该方法在附加的前向步骤中加入大量噪声,并严格遵循逆ODE过程。前向噪声的引入增强了随机性的收缩效应,而逆ODE过程的遵循则加快了采样速度。这种将随机性和确定性采样过程分离的方法极为有效,Restart在标准基准(CIFAR-10和ImageNet-64)上超过了SDE和ODE采样器的速度和质量,并在大规模文本到图像的Stable Diffusion模型中展示了文本-图像对齐、视觉质量和多样性的卓越平衡。
传统上,扩散模型从模型分布中生成独立同分布的样本。然而,在实际操作中,模型通常需要多次采样以获得一组多样化的小批量样本,这会带来与采样时间无关的成本。我们提出超越独立样本假设,以提高样本的多样性和效率。我们的方法引入了一种扩展的基于扩散的生成采样方法,称为粒子引导。在这种方法中,联合粒子的时间演化势通过在样本(粒子)之间加入互斥力来强制多样性。根据实验结果,我们的框架在文本到图像生成和分子构象生成等应用中提高了样本的多样性并减轻了记忆效应。
1.1.3 基于其他物理过程的生成模型
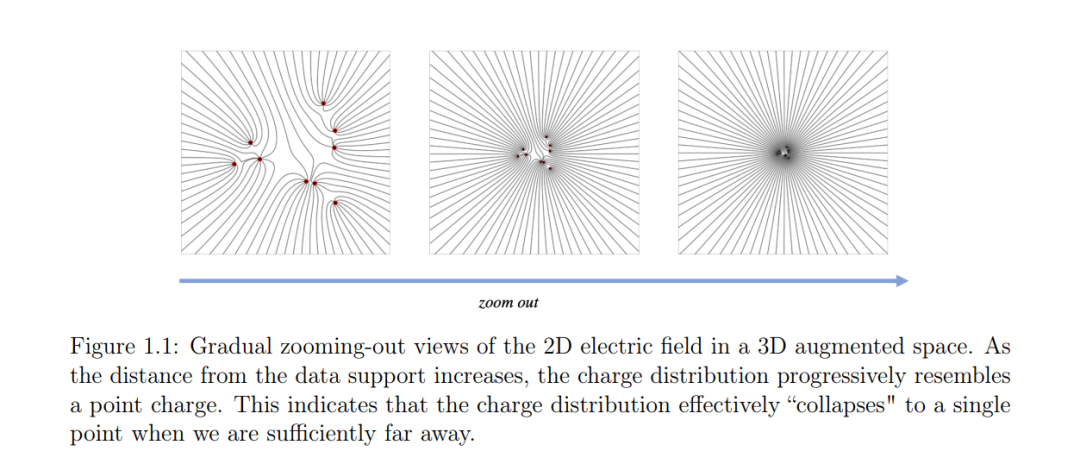
以扩散模型为显著例子,物理启发的生成模型包含一个前向过程,该过程将复杂的数据分布简化为逐步的先验分布,随后通过一个反向过程(即采样过程)逐步将这些先验分布还原为原始数据分布。因此,为了定义新的物理启发生成模型,必须确定一个合适的前向过程。该过程应自然地随着时间简化数据分布,并且是可逆的,同时其相关的向量场应该易于被神经网络学习。 借助静电学原理,我们为物理启发的生成模型开辟了一条新路径,并介绍了泊松流生成模型(Poisson Flow Generative Models, PFGM)[30] 及其扩展版本PFGM++ [31]。PFGM将数据解释为增广空间中的电荷。如图1.1所示,当我们从数据支撑远离足够远时,电荷分布坍缩为一个点电荷,电场在各个方向上呈现辐射状。因此,可以证明这些电荷发出的电场线定义了数据分布和大半球上均匀分布之间的双射。实验结果表明,这一新模型家族在样本质量、采样速度和稳健性方面超越了扩散模型。此外,我们还探索了物理过程和生成模型之间的对偶性,旨在概念化和设计更多新的物理启发生成模型 [13]。
1.2 论文摘要
本论文分为三个主题部分。下面简要概述每个部分的内容。 第一部分 重点开发新技术,旨在稳定扩散模型的训练,并在处理复杂的多模态数据集时,优化生成轨迹。
第三章 我们通过引入参考批次来解决扩散模型目标中的高方差问题,并使用参考批次计算加权条件得分,作为更稳定的训练目标。我们展示了这一过程在具有挑战性的中间阶段中,通过减少训练目标协方差(的迹)确实起到了帮助作用。本章基于文献 [23]。
第四章 我们通过一个编码器推断可学习的离散潜变量,并对扩散模型和编码器进行端到端训练。离散潜变量通过降低扩散模型生成ODE的曲率,显著简化了其复杂的噪声到数据映射的学习过程,并通过ODE采样器提高了在各种数据集上的样本质量。本章基于文献 [32]。
第二部分 讨论了加速扩散模型采样过程的技术,以及通过施加样本之间的互斥力来促进多样性。所有讨论的技术都不需要重新训练,且可以直接应用于任何预训练的扩散模型。
第五章 我们提出了一种名为Restart的新采样算法,结合了先前ODE和SDE采样器的优势。Restart算法在附加的前向步骤中加入大量噪声,并严格遵循逆ODE过程。实验结果表明,Restart采样器在速度和精度上均超过了先前的SDE和ODE采样器。本章基于文献 [29]。
第六章 我们提出了粒子引导,一种扩展的基于扩散的生成采样方法,其中通过一个联合粒子的时间演化势来强制样本多样性。在条件图像生成中,我们测试了该框架,并证明其在不影响质量的情况下增加了多样性;在分子构象生成中,我们改进了相较于先前方法的中位误差。本章基于文献 [33]。
第三部分 探讨了一类新型的生成模型,这些模型基于静电理论,并与扩散模型在扩展视角下进行了统一。本部分还展望了通过物理过程构建生成模型的方法论。
第七章 我们介绍了一种新型生成模型——泊松流生成模型(PFGM),基于静电理论。我们将数据点解释为增广空间中 z=0 超平面上的电荷,生成一个高维电场(泊松方程解的梯度)。我们证明了,如果这些电荷沿电场线向上流动,它们在 z=0 平面的初始分布会转化为半径为 r 的半球上的分布,并且在 r → ∞ 时变得均匀。我们展示了PFGM在图像生成速度上提供了比先前最先进扩散模型更好的性能。本章基于文献 [30]。
第八章 我们扩展了PFGM中使用的静电理论,将扩散模型与PFGM统一起来。更有趣的是,在两者之间的插值揭示了一个性能最优的新平衡点,达到了图像生成的新标杆性能。我们为为什么PFGM和扩散模型都是次优解提供了理论解释。本章基于文献 [31]。
第九章 我们提出了一个统一的框架和算法,将物理过程转化为平滑的密度流生成模型。此外,我们基于底层物理偏微分方程(PDE)的色散关系,提出了一种分类标准。这种理论方法可应用于各种物理PDE,从而发现新的生成模型家族。本章基于文献 [13]。
第十章 我们总结了论文内容并讨论了当前的局限性。






