

现代机器学习模型的脆弱性引起了学术界和公众的广泛关注。在本论文中,我们将系统研究几种机器学习模型的理解与改进,包括平滑模型和通用表征网络。我们特别关注表征鲁棒性的研究,将其定义为给定网络在隐含空间中的“鲁棒性”(或广义上的可信属性)。对于通用表征网络,这对应于表征空间本身,而对于平滑模型,我们将网络的logits视为目标空间。表征鲁棒性是许多可信赖AI领域的基础,例如公平性和鲁棒性。
在本论文中,我们发现随机平滑的可证鲁棒性是以类别不公平性为代价的。我们进一步分析了改进基础模型训练过程的方法及其局限性。对于通用的非平滑表征模型,我们发现自监督对比学习与监督的邻域成分分析之间存在联系,这自然地使我们提出了一个可以实现更高准确性和鲁棒性的通用框架。此外,我们意识到当前基础表征模型的评估实践涉及在各种现实任务上进行大量实验,这既耗费计算资源又容易导致测试集泄漏。为此,我们提出了一种更轻量级、保护隐私且健全的评估框架,通过利用合成数据来评估视觉和语言模型。
**1.1 研究动机
深度神经网络对人眼难以察觉的对抗性扰动的脆弱性,自从开创性工作[170, 7]发表以来,已经引起了机器学习领域广泛的关注。这一问题在多个机器学习领域中都是一个重要的关注点,从计算机视觉[170]到语音识别[17],无不如此。特别是在安全关键的应用中,如自动驾驶汽车和监控系统,几乎无法容忍任何错误决策。因此,深度神经网络中对抗样本的存在,促使了对鲁棒性量化的研究,以及旨在增强这种鲁棒性的训练算法的设计[42, 47, 95]。在本论文中,我们旨在理解和改进现代机器学习模型的表征鲁棒性。
**1.1.1 机器学习模型的表征鲁棒性
表征鲁棒性指的是神经网络模型中隐含空间的可靠性。这一概念在机器学习中尤为重要,因为网络的隐藏层应该从输入数据中捕捉到复杂的模式。在本论文中,我们将表征鲁棒性定义为这些隐藏表示在面对不同输入或扰动时,能够维持理想的可信属性的能力。理想的可信属性可能包括准确性、公平性、对抗性鲁棒性等。对于一个通用的表征网络 Φ(⋅)\Phi(\cdot)Φ(⋅),隐含空间的自然选择是表征网络的输出空间。这些构建的空间通过表征学习被专门训练用于编码关于输入数据的关键信息,使网络能够通过一个简单的任务特定下游网络执行分类、回归或生成等各种任务。另一方面,在平滑模型的背景下,平滑滤波器应用于整个基础网络
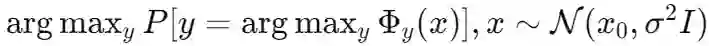
。因此,我们将直接将网络的
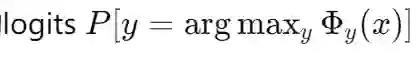
视为评估表征鲁棒性的目标空间。在这种情况下,我们特别感兴趣的是基础网络和平滑网络之间的不同表现。 研究表征鲁棒性对于推动机器学习领域的发展至关重要,原因有以下几点。首先,正如将在论文的后续章节中讨论的那样,对每个组件(如表征网络、平滑操作符等)的深入理解有助于我们更加谨慎和意识到这些操作可能产生的副作用。这种理解也将为改进这些网络设计奠定基础。其次,随着机器学习社区逐渐将重点转向任务无关的预训练和任务特定的微调,鲁棒的表征变得越来越重要。在安全关键的应用中,由于脆弱表征导致的错误预测可能会产生严重后果。从这个角度来看,表征鲁棒性是许多可信赖AI领域的基础,因为预训练的表征网络将对任何基于它的机器学习系统的整体可信赖性产生贡献。通过研究和增强表征鲁棒性,可以构建更具弹性的AI系统,并防止错误的传播。





