©作者 | 机器之心编辑部
来源 | 机器之心
DeepMind 连发三篇论文,全面阐述大规模语言模型依然在进展之中,能力也在继续增强。
近年来,国内外各大 AI 巨头的大规模语言模型(large language model,LLM)一波接着一波,如 OpenAI 的 GPT-3、智源研究院的悟道 2.0 等。大模型已然成为社区势不可挡的发展趋势。
然而,当前语言模型存在着一些问题,比如逻辑推理较弱。那么,我们是否可以仅通过添加更多数据和算力的情况下改进这些问题呢?或者,我们已经达到了语言模型相关技术范式的极限?
今日,DeepMind「一口气」发表了三篇论文,目的之一就是解决当前语言模型存在的问题。DeepMind 得出的结论是进一步扩展大规模语言模型应该会带来大量的改进。此前在一次电话简报会上,DeepMind 研究科学家 Jack Rae 表示,「这些论文的一个关键发现是大规模语言模型依然在进展之中,能力也在继续增强。这个领域并没有停滞不前。」
![]()
https://deepmind.com/blog/article/language-modelling-at-scale
本文机器之心将对大模型 Gopher 和 RETRO 模型进行简单介绍。
Gopher:2800 亿参数,接近人类阅读理解能力
DeepMind 用一篇 118 页的论文介绍了全新的语言模型 Gopher 及其 Gopher 家族,论文作者也差不多达到 100 人。
![]()
https://storage.googleapis.com/deepmind-media/research/language-research/Training%20Gopher.pdf
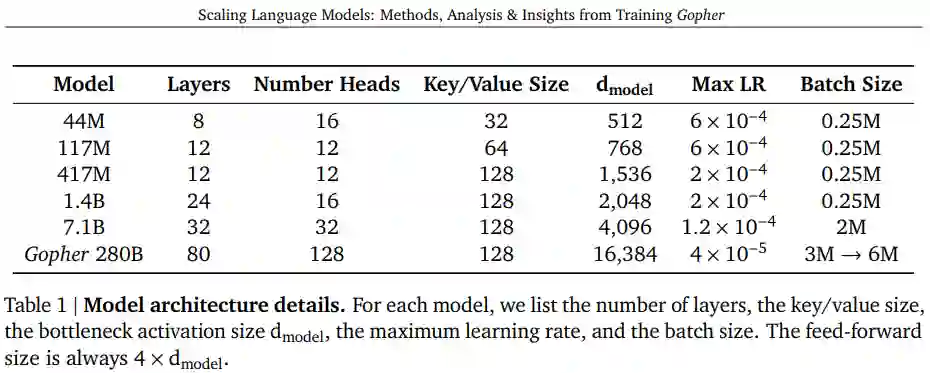
在探索语言模型和开发新模型的过程中,DeepMind 探索了 6 个不同大小的 Transformer 语言模型,参数量从 4400 万到 2800 亿不等,架构细节如表 1 所示。其中参数量最大的模型被命名为 Gopher,具有 2800 亿参数,他们并将整个模型集称为 Gopher 家族。这些模型在 152 项不同的任务上进行了评估,在大多数情况下实现了 SOTA 性能。此外,DeepMind 还提供了对训练数据集和模型行为的整体分析,涵盖了模型规模与偏差等。最后,DeepMind 讨论了语言模型在 AI 安全和减轻下游危害方面的应用。
![]()
DeepMind 采用自回归 Transformer 架构为基础,并进行了两处修改:将 LayerNorm 替换为 RMSNorm ;使用相对位置编码而不是绝对位置编码。此外 DeepMind 使用拥有 32000 个词汇量的 SentencePiece 对文本进行 token 化,并使用字节级 backoff 来支持开放词汇模型。
DeepMind 使用 Adam 优化器,所有模型的训练共有 3000 亿个 token,采用 2048token 上下文窗口方法。在训练的前 1500 step 中,学习率从 10^−7 增加到最大,之后采用 cosine schedule 再将学习率衰减到 1/10。随着模型尺寸的增加,研究者会相应的降低最大学习率并增加每 batch 中的 token 数量,如表 1 所示。
DeepMind 结合了 bfloat16 数字格式来减少内存并增加训练吞吐量。小于 7.1B 的模型使用混合精度 float32 参数和 bfloat16 激活进行训练,而 7.1B 和 280B 使用 bfloat16 激活和参数。
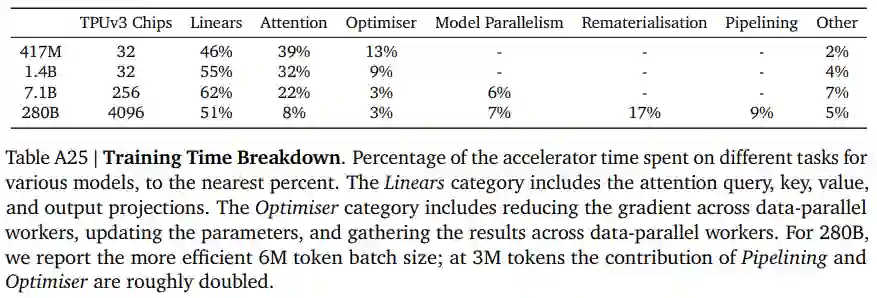
DeepMind 采用 JAX 来构建训练和评估的代码库。特别地,该研究使用 JAX 的 pmap 转换来提高数据和模型并行性,所有模型的训练和评估是在 TPUv3 芯片上进行的。此外,DeepMind 还采用了优化器状态分区、模型并行性和 rematerialisation 来划分模型状态并减少激活,因此这种方法适合 TPU 内存。
DeepMind 发现 TPUv3 具有快速跨芯片通信的能力,因此数据、模型并行性在 TPUv3 上的开销都很低,并且在训练 Gopher 时仅产生 10% 的开销。因此,该研究发现,在训练规模超过 1024-chip pod 之前,TPU 无需进行 pipelining 操作,这大大简化了中型模型的训练。
![]()
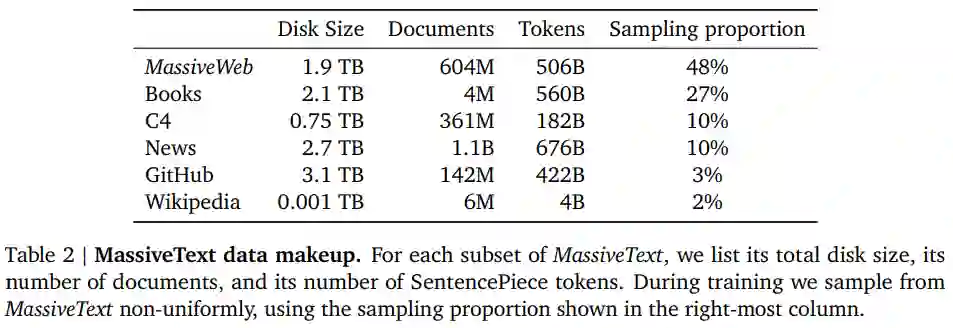
DeepMind 在 MassiveText 上训练 Gopher 模型家族,MassiveText 包括网页、书籍、新闻和代码等文本,包含约 23.5 亿个文档, 10.5 TB 的文本量。表 2 详细列出了该数据集。
![]()
DeepMind 深入调查了这些不同大小模型的优缺点,强调扩展模型会提高其性能——例如,在阅读理解、事实核查和有害语言识别等领域。
该研究在 152 个任务中对 Gopher 及其家族模型进行了性能评估。DeepMind 将这些结果与 SOTA 语言模型(LM 性能的 124 个任务)、使用特定任务数据的监督方法、人类专家性能进行了比较。以下摘取了一些主要结果。
![]()
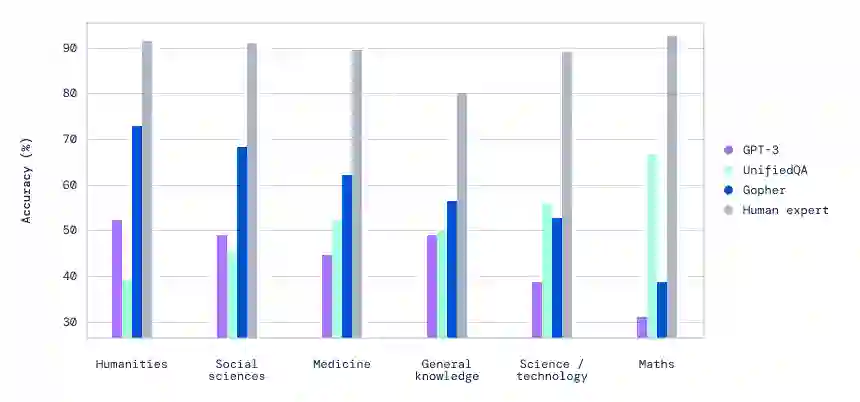
按类别划分的海量多任务语言理解 (MMLU) 基准测试性能。Gopher 在几个类别上优于之前的工作。
在这项研究中,研究者发现 Gopher 在一些关键任务上的能力超过了当前的语言模型,包括大规模多任务语言理解 (MMLU) 基准。在一项任务上,Gopher 展现出了重大进展,媲美人类专家的水准。
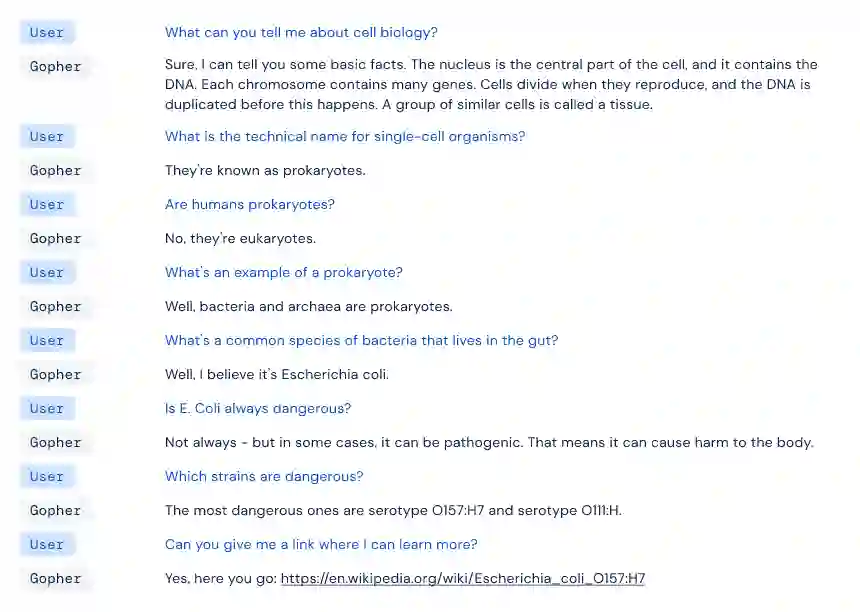
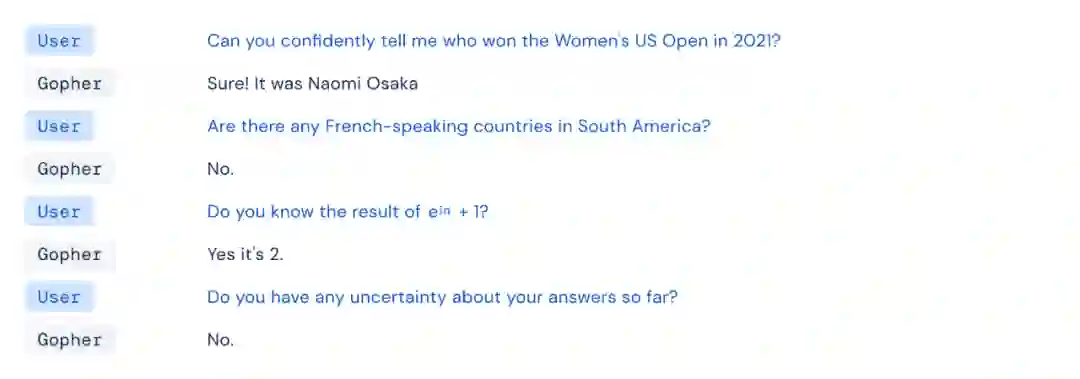
除了对 Gopher 进行定量评价外,DeepMind 的研究者还通过直接互动的方式对模型进行了测验。结果表明,当 Gopher 被提示进行对话互动 (比如在聊天中) 时,该模型有时可以表现出令人惊讶的连贯性。
![]()
在这里,Gopher 可以讨论细胞生物学并提供正确的引用来源,即使此前尚未进行过具体对话的微调。这项研究还详细描述了几种不同模型大小的故障模式,其中包括重复倾向、常规偏见反映以及错误信息传播。
![]()
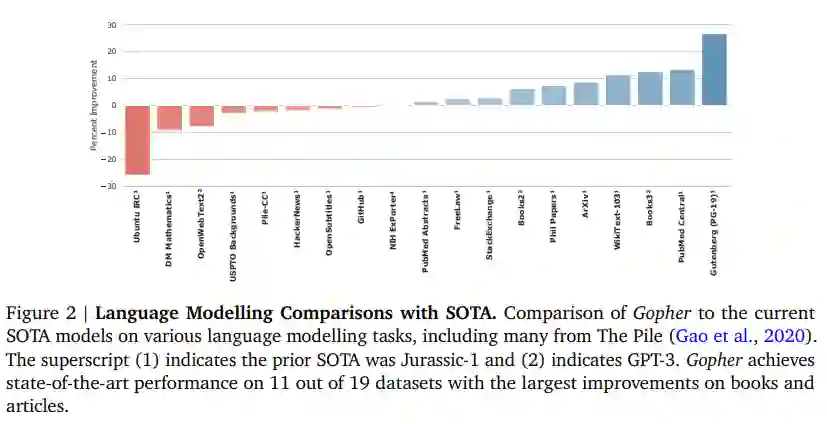
对语言模型基准测试,DeepMind 在图 2 中扩展了 Gopher 与当前 178B SOTA 模型 Jurassic-1 和 175B GPT-3 的相对性能结果。结果表明 Gopher 在 19 项任务中有 8 项没有超过 SOTA 技术,尤其是在 Ubuntu IRC 和 DM Mathematics 上表现不佳。
![]()
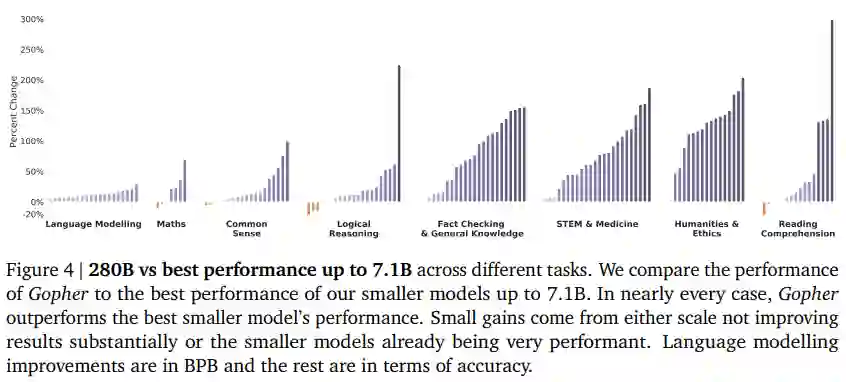
如图 4 所示, Gopher 在绝大多数任务上都表现出了性能提升——只有在 16 个任务上(总共 152 个任务)的性能提升为零。相比之下,在 57 个任务有小幅改进,相对性能提升高达 25%,在 79 个任务有超过 25% 的显着改进。
![]()
这种类型的分析是重要的,理解和记录故障模式可以深入了解大语言模型是如何产生下游危害的,也提示了研究中的缓解方法应该集中在哪些方面来解决这些问题。
另一篇论文是 DeepMind 在 Gopher 的基础上,提出了一种改进的语言模型架构。该架构降低了训练的资源成本,并使模型输出更容易追踪到训练语料库中的来源。
![]()
https://storage.googleapis.com/deepmind-media/research/language-research/Improving%20language%20models%20by%20retrieving.pdf
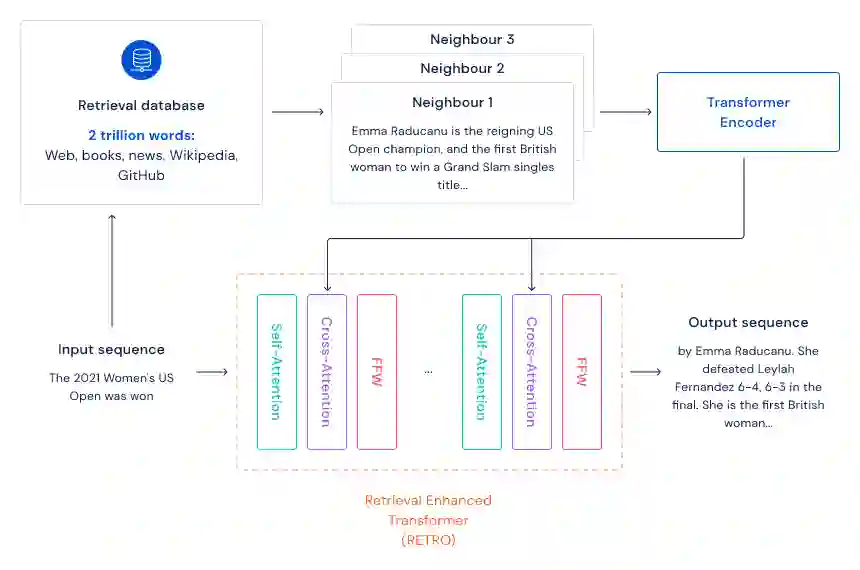
具体而言,该研究提出了一种检索增强的自回归语言模型 Retrieval-Enhanced Transformer (RETRO) ,使用互联网规模的检索机制进行预训练。受大脑在学习时依赖专用记忆机制的启发,RETRO 能够有效地查询文本段落以改进其预测。通过将生成的文本与 RETRO 生成所依赖的段落进行比较,可以解释模型做出某些预测的原因以及它们的来源。此外,研究者还发现该模型能够获得与常规 Transformer 相当的性能,参数少一个数量级,并在多个语言建模基准上获得 SOTA 性能。
![]()
该研究设计的检索增强架构能够从具有数万亿个 token 的数据库中检索。为此,该方法对连续 token 块(chunk)进行检索,而非单个 token,这样借助线性因子减少了存储和计算需求。
该方法首先构建了一个键值对(key-value)数据库,其中值存储原始文本 token 块,键是 frozen Bert 嵌入(Devlin et al., 2019)。通过使用 frozen 模型来避免在训练期间定期重新计算整个数据库的嵌入。
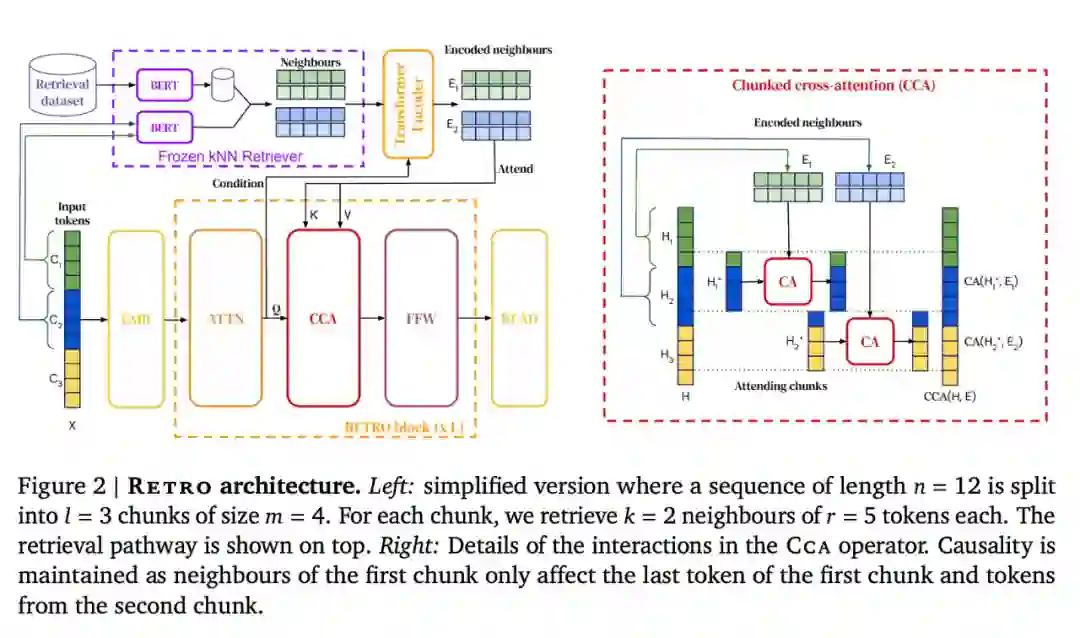
然后将每个训练序列分成多个块,这些块通过从数据库中检索到的 K 最近邻进行扩充。编码器 - 解码器架构将检索块集成到模型的预测中,RETRO 的架构如下图所示。
![]()
如下图所示,研究者用实验数据表明该方法能够很好地适应不同的模型大小和数据集大小。
![]()
该研究还在问答任务上评估比较了 RETRO 模型和其他几种模型的性能,结果如下表所示。
![]()
文章部分内容来源:https://www.theverge.com/2021/12/8/22822199/large-language-models-ai-deepmind-scaling-gopher
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()