【领域报告】主动学习年度进展|VALSE2018
编者按:白居易在《忆江南》中曾写道,
“山寺月中寻桂子,郡亭枕上看潮头。”
诗人结合“月中桂树”的传说,从江南众多景色中,选择了灵隐寺的皎月和钱塘江的潮头,这两处具有代表性的场景来追忆江南。而这两处样本的选择,也体现了诗人对江南风光的充分理解。
其实,在机器学习任务中,由于数据标注代价高昂,我们也面临着如何以最少量的样本,来获得最有效学习模型的问题。 如果能够从任务出发,通过对任务的理解来制定标准,挑选最重要的样本,使其最有助于模型的学习过程,将大大减少监督学习的成本。
因此,学术界衍生出了主动学习这一研究方向。本文中,来自南京航空航天大学的黄圣君副教授,将为大家介绍主动学习领域的年度进展。
文末,大讲堂提供文中所提到参考文献的下载链接。

本次报告的题目是《recent progress on active learning 》,我们知道对于监督学习任务,要训练好模型,一般有标记的训练数据越多越好,但很多任务里面有标记的数据非常稀少,而且标注过程往往需要专业的知识,耗时耗力,导致代价昂贵。所以我们希望用更少的标注数据,训练出更好的模型。
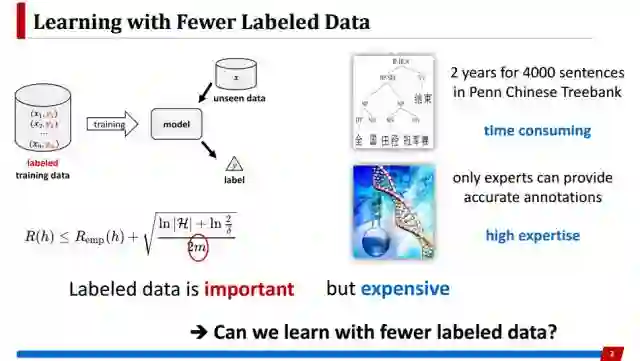
主动学习就是解决这个问题的重要手段。虽然有标记数据很少,但可以廉价获得非常多未标注的数据。在主动学习里有一个标注专家,我们可以迭代地从未标注数据里面挑选出一部分重要数据去标注,从而获得更多有标记数据。所以主动学习的目标是希望用最小标注代价获得最好的学习模型。
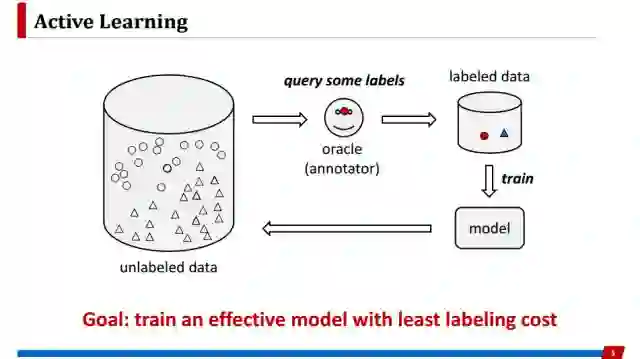
主动学习里面最核心的问题就是需要制定标准,使得挑选出来的样本确实是对模型最有帮助的。
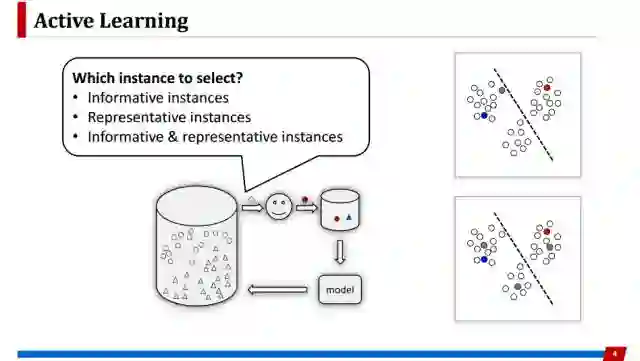
这个问题在过去几十年间,一直是主动学习这个方向研究最关注的一点。以往的方法大概可分为这两类:一类方法,倾向于选择最有信息的样本,例如,我去教你最不会的东西应该是对你最有帮助。另外一类方法,是倾向选择最有代表性的样本,希望选择的样本涵盖数据整体分布的信息。
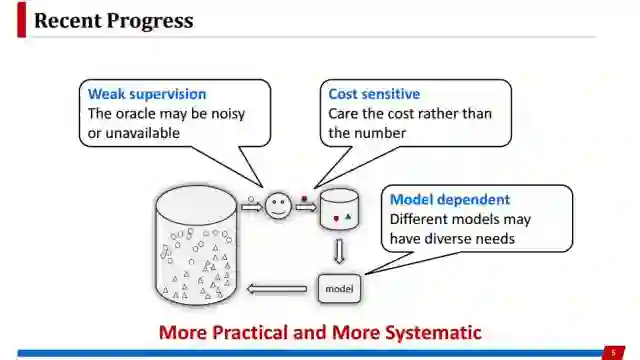
最近还有很多工作依然在关注选择标准的制定上,但是我个人感觉这一年来在主动学习方面的进展,开始倾向于考虑更实际的应用场景,而且更系统的考虑整个学习过程中各个环节。这主要体现在三个方面:
第一个是更多的关注oracle不可靠的情况,比如Oracle提供的是含噪声、弱监督的信息。
第二个是更多的关注代价敏感性,考虑每次查询中标注代价的差异,而不仅仅追求减少查询次数。
第三个方面是更多的关注模型依赖的主动学习方法。比如深度学习等一些更复杂的模型可能会对主动学习产生新的要求。
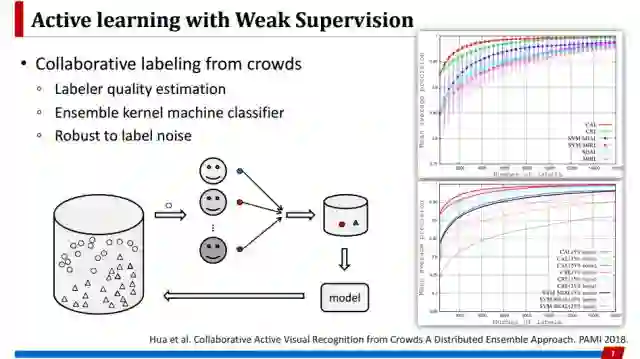
我分别会从三个方面介绍代表性工作。首先是弱监督方面,这是今年的一个工作,作者考虑的不是一个oracle而是一批oracle,但是每个oracle提供的信息可能都是含噪声的。这个方法希望准确评估每个oracle提供的标注质量,并且希望能够得到对噪声鲁棒的分类器。实验证明这个效果还是不错的,对不同程度的噪声都是鲁棒的。
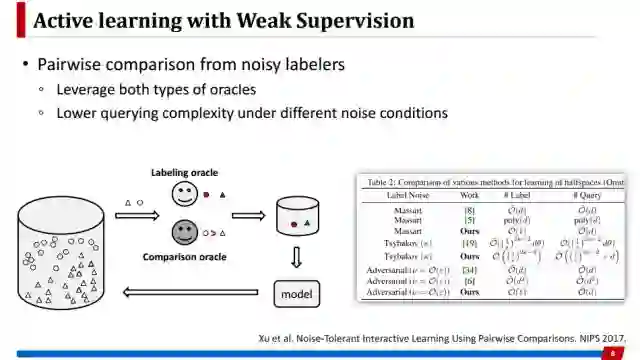
这个工作是考虑到另外一种情况,他有两个oracle,一个oracle是去提供样本标记,另一个oracle是针对两个样本,告诉你这两个样本里哪个更可能是正样本。他提供这样一种比较的信息,所以也是一种弱监督的信息。这个工作的主要贡献是在不同噪声条件下提供关于查询复杂度的理论保证。

这个工作是从另外一个角度考虑的,用一个模型去预测一个样本,如果置信度很低,那就向oracle去查询这个样本的标记信息,如果置信度很高,就直接把当前模型的预测作为标记来用。所以他是结合模型自身的预测信息和oracle的信息来帮助提高学习效果。结果表明,这个方法效果明显,只要查询40%的样本就可以达到传统方法用所有数据达到的效果。
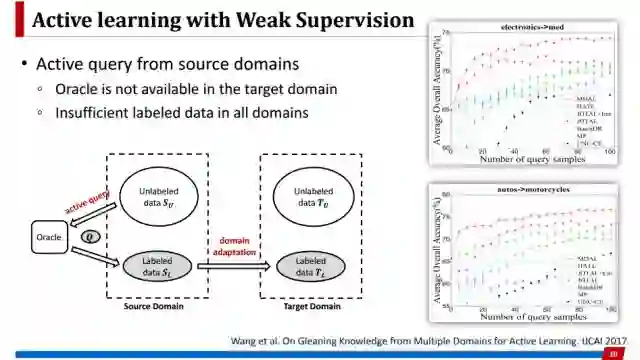
这个工作考虑的是极端情况,某些任务里面连oracle都没有,比如涉及到敏感信息或者安全信息,或者任务要求领域知识非常强,这时候没有Oracle能够提供更多标注。所以我们希望从相关任务里去查询新的样本,把这个样本迁移过来学习,从而帮助目标任务的学习。这个工作的挑战在于,如果把主动学习和迁移学习两个任务独立考虑,有可能挑出来的样本对source domain有帮助,但迁移过来之后对target domain并没有帮助,这就是挑战所在,这工作是基于2016年IJCAI的一个类似工作扩展来的,只是把source domain由一个扩展到多个的情况。
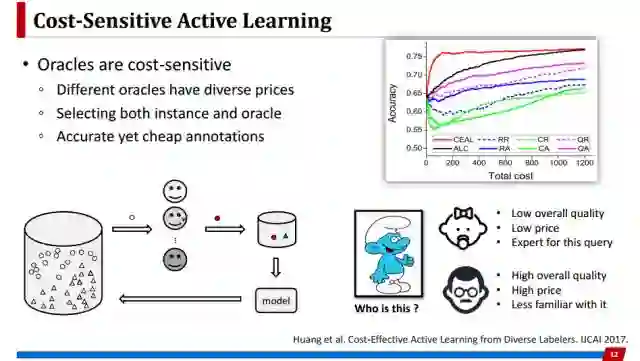
第二方面,考虑代价敏感性的主动学习也有不少工作。首先考虑的是标注者(Oracle)本身是代价敏感的,例如有很多标注者,但是每个标注者要价是不一样的。像有一个成年专家和小孩,一般来说成年专家要价更高一些。但如果考虑标注这样一个图片,如果要看图片里面动画人物是谁,小孩可能标注更准一些。所以在这样场景下可以获得性价比更高的标注,可以用更低的价格获得更准确的标注。这个工作就是在挑选样本的同时去挑选最适合标注该样本的标注者。
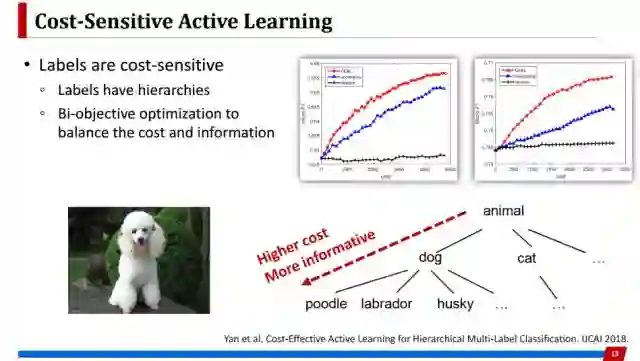
另外一个是标记本身也是有代价敏感的。比如在多标记任务里,多个标记可能形成这样层次化的结构,越底层的标记描述信息越具体。但是oracle在标注的时候需要花费更多的时间,所以需要有一种方法平衡信息量和标注代价之间的矛盾。这个工作采取的是多目标优化方法来平衡,而且取得很好效果。
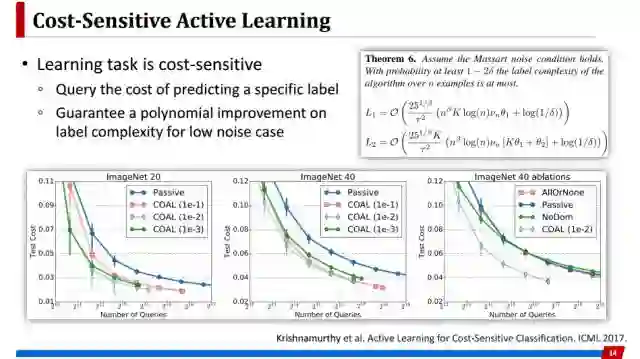
此外,学习任务本身也是代价敏感的,这个敏感体现在把某一类样本错分到另外一类上,所付出的代价可能是不一样的。所以这个工作考虑的是这种情况,它每次查询不再是某一个样本的标记,而是去查询这个样本如果被分成某一个类别所付出的代价会是多少。这个工作除了在实验上取得好的效果之外,在理论上也证明如果噪声条件不是很强的情况下,可以显著降低标记复杂度。
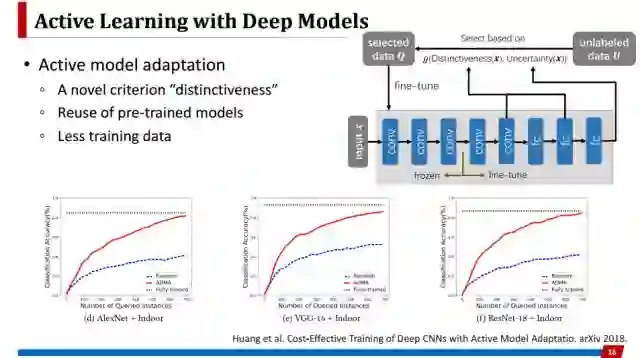
最后一方面,随着学习模型变得越来越复杂,会不会对主动学习提出新的要求?这个工作是我们最近提出来的工作,它所考虑的是,虽然深度神经网络在很多方面都取得了成功,但是当去解决新的任务的时候,需要丰富的经验去设计网络结构,调参数,需要很多的训练数据去训练它。我们希望用一些已经预训练好的模型,在这个模型上用很少的训练数据,把它从预训练的任务上迁移过来,在新的任务上也取得很好的效果。以往的主动学习往往关注的是挑出来的样本是对于提升分类效果最有帮助的,但是深度学习大家都知道它的非常强大能力在于学习出好的特征表示。所以我们定义了一个新的指标distinctiveness,这个指标衡量的是一个样本,在提升深度神经网络特征学习能力方面的作用大小,这是跟以往主动学习所不一样的。从实验结果中可以看到,通过基于distinctiveness的主动选择,在很多模型上用很少数据就可以将预训练好的深度神经网络模型迁移到一个新的任务上并得到很好的效果。
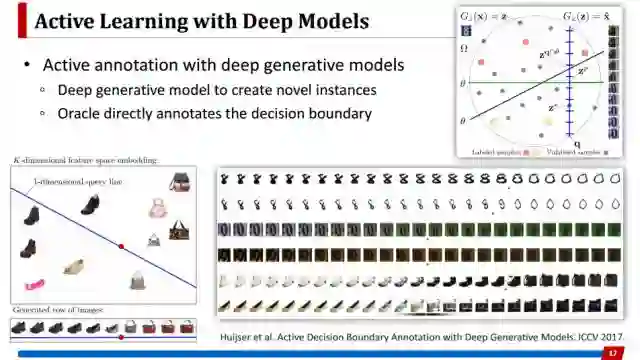
最后一个工作是基于生成模型。原来的主动学习方法都是从未标记数据中挑出来部分样本去标注,这里不再是从一堆数据里去挑选,而是生成一批这样的样本。首先,在decision boundary上面产生很多等分点,每个点对应一个样本,这就是生成的一系列样本。然后让oracle去标注的不是每个样本属于哪个类别,而是这些样本里面,例如,这是鞋子这是包,oracle会标注这些样本里区分这两个类别的临界点在哪里。所以这种方法跟以往所有的主动学习方法思路完全不一样,他让oracle标注的是直接提供一个分类器应该所处的位置,所以具有更强的信息,因此也取得不错的效果。

除此以外还有很多用主动学习解决不同应用问题的研究,这里不再一一介绍。以上就是对过去一年主动学习方面新出现的三个趋势的简单介绍和总结,谢谢大家。

参考文献链接:
链接: https://pan.baidu.com/s/1pY4rDMSPzbJjliz1iYqW0A
密码: aa5g
主编:袁基睿,编辑:程一
整理:周文、杨茹茵、高科、高黎明
--end--
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 Emily_0167。
作者简介:

黄圣君,博士,南京航空航天大学副教授。分别于2008年和2014年从南京大学计算机科学与技术系获学士和博士学位。主要研究领域为机器学习,在相关领域重要国际期刊如IEEE TPAMI、TNNLS等和国际会议如NIPS、KDD、IJCAI、AAAI等发表论二十余篇。曾入选中国科协“青年人才托举工程”,获中国计算机学会优秀博士学位论文奖、KDD’12 Best Poster奖及微软学者奖等荣誉。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站




