
© 作者|杨锦霞 机构|中国人民大学研究方向|多模态学习
医学视觉语言预训练方法主要利用配对的医学图像和放射学报告之间的对应关系。尽管在现有的多模态医疗数据集中可以使用多视图空间图像和图像文本对的时间序列,但大多数现有方法尚未利用如此广泛的监督信号。在本文中,我们提出了用于细粒度空间和时间建模的Med-ST框架,以利用来自多视角图像和时间历史记录的信息。文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

论文题目:Unlocking the Power of Spatial and Temporal Information in Medical Multimodal Pre-training
论文链接:https://arxiv.org/abs/2405.19654
1. 引言
医学视觉语言预训练旨在从成对的放射报告和图像中学习视觉和文本表示,得到的表征可以适应各种下游任务,在临床诊断等方面具有较大的潜在价值。现有的医学视觉语言预训练方法通常侧重于利用配对图像和文本之间的对应关系,虽然学习到的表征可以对医学语义信息进行编码,但它们不能完全捕捉不同视角的空间信息,也无法区分同一患者在不同时间的图文对之间的差异。
医学视觉语言预训练模型的适用性在很大程度上取决于它们在解释放射报告和图像时模仿人类认知的能力。如下图所示,在实际场景中,医生的诊断不仅依赖于此次的检查结果(包括拍摄的正面视图和侧面视图),还会查看病人的历史病例来了解过去的症状。幸运的是,这种时空信息可以在现成的医学多模态数据集中获得。在现有多模态数据集中,除了图像-文本对之外,还自然地体现了两种类型的监督信号:空间信息(正面和侧面视图)和时间信息(诊断的时间顺序)。
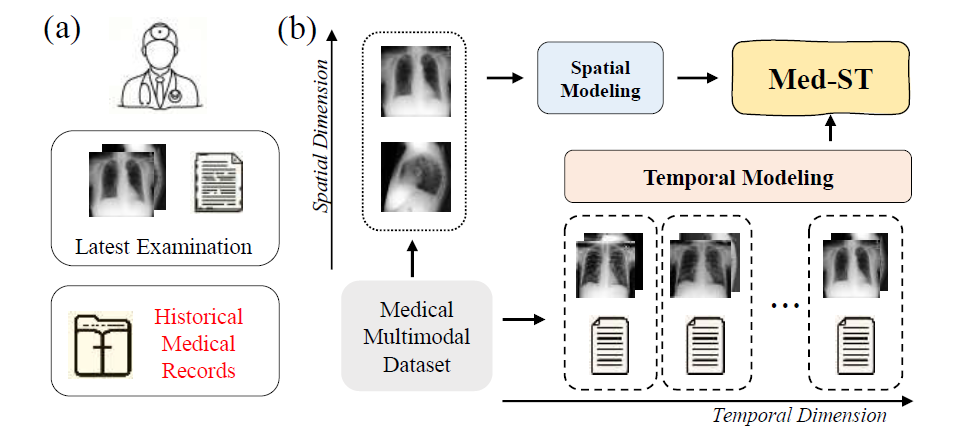
然而,现有的医学预训练方法尚未充分探索这些监督信号。对于空间信息,侧视图的图像要么被忽略,要么与正视图一样处理;对于时间信息,现有工作仅使用一张之前的图像,并且没有专门为此监督信号设计目标。在这项工作中,我们提出Med-ST,通过利用现有医学多模态数据集中的空间和时间信息来监督视觉和文本表示的预训练。
2. 方法
2.1 Overview
现有的医学数据集是按每一个病人每次诊断的图文对来组织的,并且每个病人的诊断有时间先后顺序,所以我们可以直接获取监督信号,而无需手动注释。我们将医学数据集
中的数据重新组织成多个序列,其中每个序列包含一系列图像文本对,对应患者的历史诊断记录。一些图像文本对不属于任何序列,例如,患者只有一个诊断记录,我们将这些单独的图像文本对视为长度为1的序列。因此, ,其中是数据集中的序列数量。对于第 个序列, ,其中 分别是第 t 个时间步的正视图、对应的侧视图以及文本报告, 是此序列中的图像-文本对的数量。对于某些 i 和 t,侧视图 不存在,在这种情况下,我们将其设置为全为零的张量。
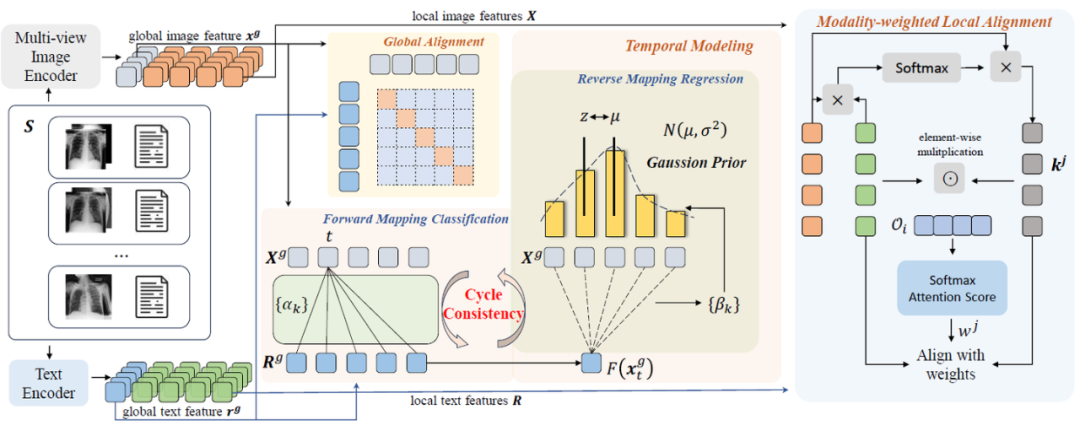
Med-ST 由多视角图像编码器 和文本编码器 组成。图像编码器使用提出的mixture of view experts架构从正面和侧面图像中提取表示,即,其中 是全局图像特征, 是局部特征,M 是图像patch的数量。文本编码器提取文本表示,即 ,其中 是全局文本特征, 是局部文本表示,W 是token的数量。如下图所示,在训练阶段,对于每个输入序列 ,Med-ST首先提取所有时间步的图像和文本表示: 。首先,Med-ST在配对的全局图像和文本特征 之间执行全局对齐,并在局部特征 间引入模态加权局部对齐。对于时间建模,全局图像和全局文本特征形成两个特征序列, 和 ,Med-ST 使用跨模态循环一致性来对齐 和 。
2.2 空间建模
2.2.1 图像特征提取
基于ViT,我们利用提出的Mixture of View Experts (MoVE) 架构作为 来编码多视角图像。如下图所示,对于序列样本 中的一对正侧图 (, ) ,我们首先将它们分别划分为多个patch,然后通过projector和flatten以获得, ,维度是 。我们添加了一个可学习的嵌入 。为了保留每个patch的位置信息,我们引入了位置编码 。然后将它们concat来形成图像编码器的输入序列: 其中 是concat运算,。
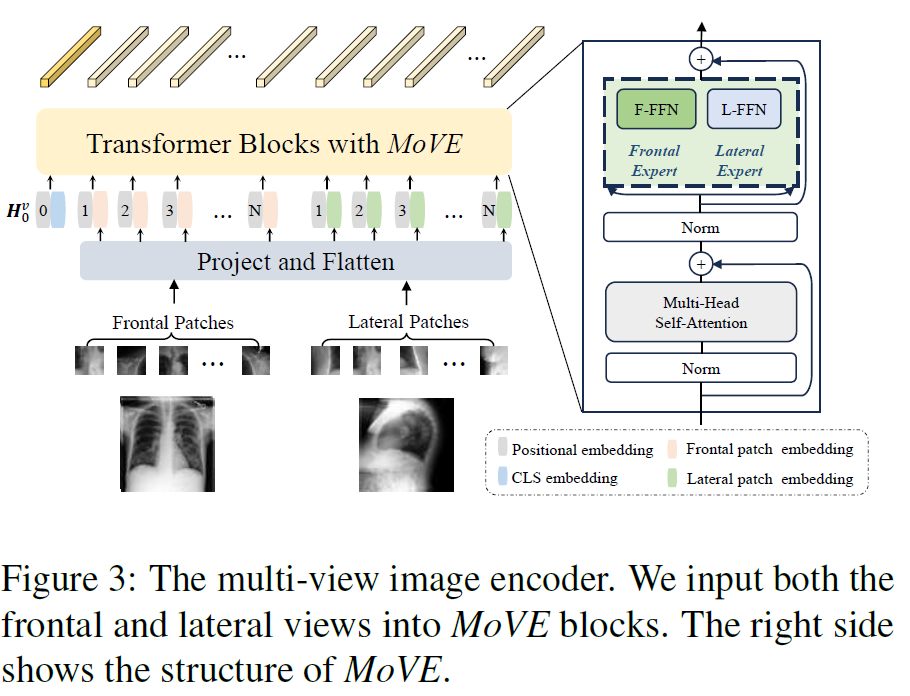
为了使模型能够感知两个视图之间的差异,我们使用我们的Move架构来替换 ViT 的blocks。具体来说,得到前一层的输出 后执行multi-head self-attention来捕获它们之间的空间依赖关系。然后,前 向量通过F-FFN,后 个向量则通过L-FFN。这两个 FFN 充当不同视角的expert,从不同角度获取互补信息。两个FFN的的输出concat后作为该层的输出 。对于最后一层的输出 ,: 是全局多视角图像特征,: 是局部特征。
2.2.2 跨模态对齐
全局对齐 对于batch中第i个序列的第t个样本(, ),我们可以得到图像特征 和文本特征 以及其对应局部特征 。我们利用对比损失来拉近配对的全局图像和文本而拉远不配对的特征。 因此,全局对齐的目标是两个损失的平均值:
模态加权的局部对齐 考虑到病理区域可能只占据图像和文本的一部分,我们在 以及其对应局部特征 之间引入了一种新的模态加权局部对齐,即在patch和token特征的成对序列之间来执行细粒度的空间建模。对于 中的第j个文本token ,我们计算 与 中所有图像patch特征之间的余弦相似度,得到 。然后将score 乘以相应的图像patch特征,因此,我们生成了textual-attended visual representation 。我们局部对齐的目标是对齐 及其对应的。
我们认为表示更多病理语义的信息应该被赋予更重要的意义。对于 ,其权重是通过将该对与 中所有局部对的平均值进行比较来确定的。首先,我们对 和 进行逐元素相乘,即 。这些向量在不同维度捕获了不同角度的重要性,。然后计算平均值: ,我们通过下面式子得到权重:
其中 是可学习矩阵。 我们将 作为 的权重,并得出视觉模态加权局部对齐损失: 相应地,我们可以得到文本模态加权局部对齐损失 。故局部对齐的目标是:
2.3 时序建模
时序建模的目标是利用时间变化信息来更好地对齐表达相同时序变化语义的图像和文本序列,通过感知序列中的前后信息,模型可以捕获语义变化并获得更好的表示。这和现实生活中的医疗诊断类似,医生可以通过检查患者的医疗记录来做出更好的决定。对于序列 ,全局图像和文本特征形成两个序列, 和 ,Med-ST 利用跨模态双向循环一致性约束来对齐 和 。 循环一致性 针对图像序列 中的某一点 ,我们首先通过函数 F 将其映射到文本序列,然后该映射的结果通过函数 G 再映射到图像序列,因此我们可以得到 。如果 ,则 是循环一致的。循环一致性的双向匹配可以感知细粒度的序列上下文差异。由于我们的模型从未明确感知过时间序列,故我们采用了一种从简单到复杂的双向学习方法。 前向映射分类 (FMC) 我们首先计算 和 中的所有点之间的距离,然后我们得到 的soft nearest neighbor : 由于我们的图文序列是成对的,我们可以在前向过程中引入约束。我们将序列 中的所有特征视为不同的类,然后对 进行分类。故预测的输出 。真实值 是一个 one-hot 向量。故 对于序列 ,FMC的目标如下: 反向映射回归 (RMR) 由于 FMC 从相对简单的分类角度促进循环一致性,因此我们希望在反向映射过程中加入更复杂的目标。我们根据 和 之间的距离,对距离真实值较远的预测先施加了更大的惩罚。我们得到 和 中的所有点之间的相似性 的分布: 由于在时间上更接近的表示往往语义更相似,故距离 t 越远,相似性应越小,所以 满足高斯分布的形式。因此,我们给 施加高斯先验。我们的目标是最大化 ,并且使得分布在 t 处呈现尖峰。故我们优化 ,并添加正则化项 来避免此优化导致的方差变大。同时,由于序列中包含的时间信息可能具有较大的时间跨度,故对于误差较大的情况,我们优化 。因此 RMR 目标如下: 其中 和 ,表示正则化权重, 是超参数。 对于 中的所有序列,我们将这两个目标相加,得到 。 同样,从文本序列中的一个点开始,我们可以得到 。因此,时序建模的目标是:。 总目标 。
3. 实验
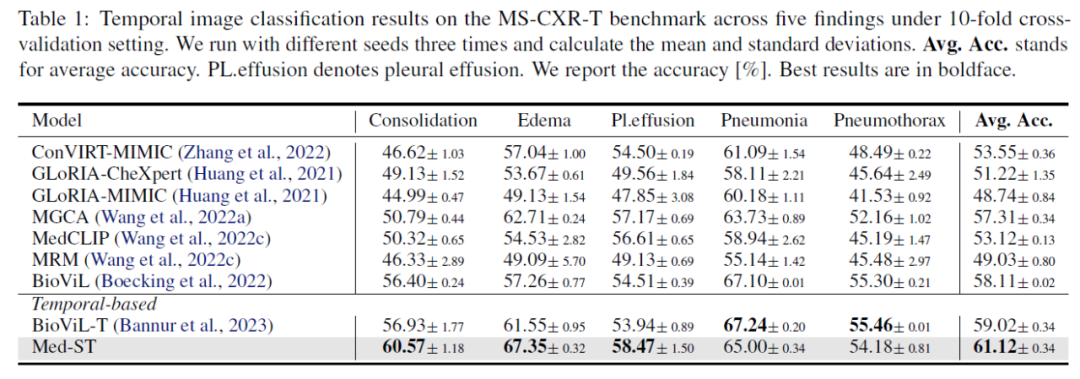
我们在四种下游任务上进行实验,包括时序图像分类、时序文本相似性分类、零样本图像分类和医学图像分类。 时序图像分类 包括 1,326 张标记的胸部 X 光片,涵盖五种疾病类型(实变、水肿、胸腔积液、肺炎和气胸),需要将前后两张图像分为疾病进展的三个阶段:改善、稳定、恶化。可以看到,Med-ST优于之前所有的基线,均值比基于时序的BioViL-T提高2.10%。
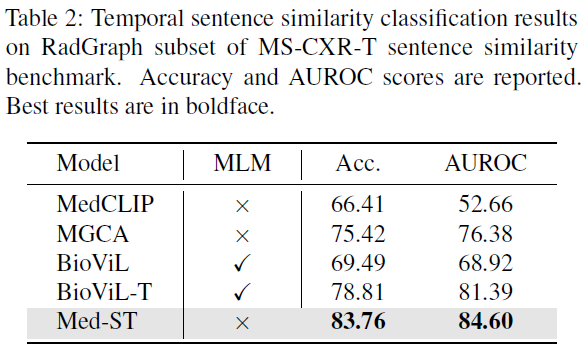
时序文本相似性分类 该任务是对成对文本句子进行分类,判断他们关于疾病进展的描述是一致或矛盾。我们的方法在准确性和 AUROC 指标上都取得了最佳结果,在准确性上比 BioViL-T 高出 4.95%,在 AUROC 指标上高出 3.2%。
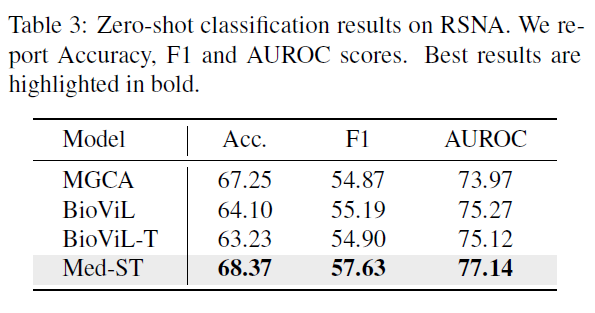
零样本图像分类 我们在 RSNA 数据据上测试我们的零样本分类结果。实验结果表明我们的性能改进不仅限于时序任务,而且还有利于静态分类任务。我们的模型在准确率、F1 分数和 AUROC 指标上都比之前的方法高。在这些指标的提升表明空间和时间建模可以增强模型的表示能力。
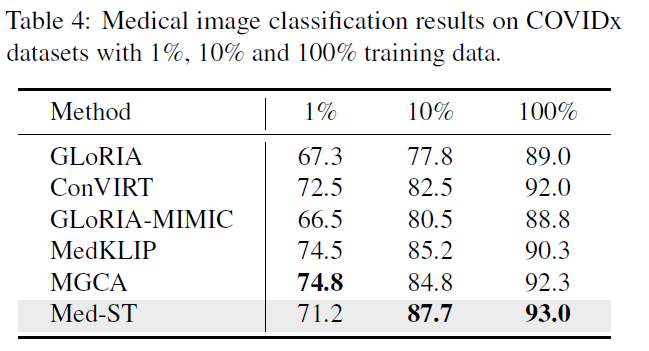
医学图像分类 我们在 COVIDx 数据集上进行了测试,以评估其在医学图像分类中的效果。我们的方法使用10%和100%的训练数据都取得了比较好的结果。
**消融实验 **下表显示我们的各个模块在时序图像分类任务上的消融结果。可以看出,当所有目标和侧视图相结合时,可以获得最佳结果。前两行表示我们的时序建模和局部对齐的有效性,第三行表明了使用侧视图的有效性。

4. 结论
在这项研究中,我们提出了Med-ST框架,该框架采用明确的空间和时间建模、全局和局部对齐以及跨模态双向循环一致性的综合策略。我们的方法不仅在时序相关的任务中取得了优异的性能,而且增强了医学图像相关任务的性能。Med-ST 利用多模态数据集来获得空间和时间的洞察力,为医疗多模态预训练提供了新的见解。
