© 作者|陈杰 机构|中国人民大学研究方向|自然语言处理、大语言模型 继续预训练是使语言模型适应特定领域或任务的一种重要方法。为了使继续预训练更具可追溯性,本研究展示了一份技术报告,通过继续预训练显著增强了 Llama-3(8B)的中文语言能力和科学推理能力。为了在增强新能力的同时保持原有能力,我们利用现有数据集并合成高质量数据集,设计了特定的数据混合和数据课程策略。我们将继续预训练后的模型命名为 Llama-3-SynE(Synthetic data Enhanced Llama-3)。
文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

论文题目:Towards Effective and Efficient Continual Pre-training of Large Language Models 论文链接:https://arxiv.org/abs/2407.18743 GitHub链接:https://github.com/RUC-GSAI/Llama-3-SynE
引言
大语言模型(large language model,LLM)相关研究在推动人工智能发展方面取得了重大进展,但在特定场景中仍然存在知识缺口问题。例如,主要在英文语料上预训练的 Llama-3 在中文任务上的表现较差,作为通用模型,它在多学科科学知识上的表现也不足。为了解决这些问题,继续预训练(continual pre-training,CPT)是一种广泛使用的方法,通过在特定领域数据上进行 CPT,增强模型在新领域的能力。然而,CPT 过程中的一个技术难题是“灾难性遗忘”,即新能力得到增强但原有能力大幅下降。尽管现有工作广泛开展了 CPT,但在如何通过有限的训练预算提高模型的综合能力方面,关键的训练细节(如数据选择、混合和课程设计)尚未得到充分讨论。 为了使 CPT 更具可追溯性,本研究展示了一份技术报告,通过 CPT 显著增强了 Llama-3(8B)的中文语言能力和科学推理能力。为了在增强新能力的同时保持原有能力,我们利用现有数据集并合成高质量数据集,设计了特定的数据混合和数据课程策略。我们将 CPT 后的模型命名为 Llama-3-SynE(Synthetic data Enhanced Llama-3)。此外,我们还进行了相对较小模型——TinyLlama 的调优实验,并将得出的结论用于对 Llama-3 的 CPT。我们在十几余项评估基准上多维度测试了Llama-3-SynE的性能,结果表明我们的方法在不损害原有能力的情况下,大大提高了Llama-3的性能,包括通用能力(C-Eval 提升了 8.81,CMMLU 提升了 6.31)和科学推理能力(MATH 提升了 12.00,SciEval 提升了 4.13)。我们的研究贡献如下:
- 我们提出了对 Llama-3(8B)进行 CPT 的完整训练过程,包括数据选择、混合和课程设计。大量实验表明,我们的 CPT 方法是有效(在中文和科学基准测试上取得了巨大提升,同时不影响英文基准测试的性能)且高效(仅消耗约 100B token)的。
- 我们广泛探索了数据合成技术,生成了高质量的科学和代码数据。我们证明了这些合成数据可以大幅提升 LLM 的相应能力。据我们所知,这是首个公开报告如何合成和利用大规模多学科科学数据进行 CPT 的工作。
- 我们发布了用于 CPT 得到 Llama-3-SynE 的完整数据集,包括 98.5B token 的通用语料和 1.5B token 的专注于科学推理和代码任务的合成数据,我们还公开了模型和代码用于后续研究。我们的数据集十分有助于训练 LLM,这在我们针对代理模型 TinyLlama 的实验中得到了证明。
方法
本研究提出的基于 Llama-3 的 CPT 过程分为两个主要阶段:双语适应阶段和合成增强阶段。 1. 双语适应阶段:
-
目标:提高 Llama-3 的中文能力,维持或提升原有能力。
-
数据比例:将中文和英文语料的比例设置为 2:8。
-
数据策略:
-
基于主题的数据混合:通过手动设定的主题分类标签,训练分类器对网页数据进行主题识别,动态调整各主题语料的比例,以保持模型在各主题上的综合能力。
-
基于困惑度(Perplexity,PPL)的数据课程:根据模型在训练数据上的 PPL 分数,逐步增加训练数据的复杂性。
合成增强阶段:
-
目标:通过合成数据提高 Llama-3 的多学科科学推理能力,维持或提升代码能力。
-
数据比例:将中文、英文和合成数据的数据比例调整为 1:7:2。
-
数据合成:
-
科学问答数据:基于科学领域的网页内容,使用 LLM 生成相关的科学问答对。
-
代码问答数据:利用现有的编程题库,生成新的编程问题及其答案。
对 CPT 过程的介绍详见论文。
实验与结果
我们首先在相对较小的模型 TinyLlama 上进行了广泛的探索性实验,验证了数据合成的有效性,并对合成数据的质量、数据比例及数据课程策略进行探索,同时对比了我们的合成数据与现有开源数据,对探索性实验的详细介绍请见论文。我们将实验得出的结论应用于对 Llama-3 的 CPT。实验结果表明,我们的方法在不损害原有能力的情况下,大大提高了基础模型的中文语言和科学推理能力。我们在十几余项常使用的主要基准测试和科学基准测试上对 Llama-3-SynE 进行了评估,结果如下图所示。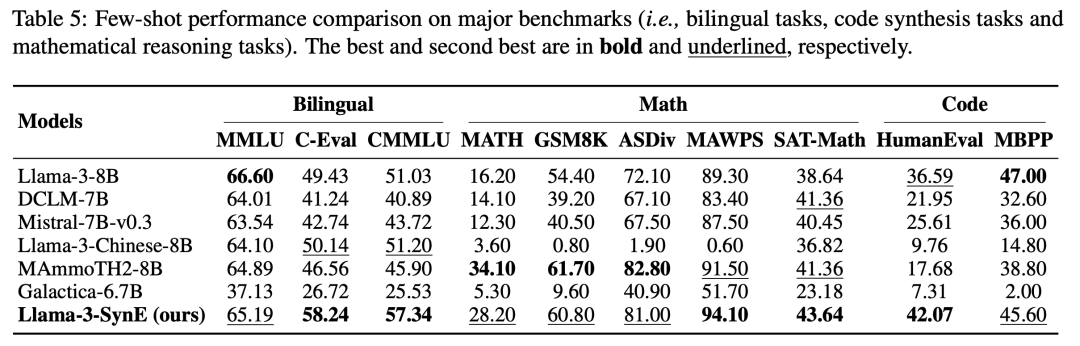

值得注意的是,在前期实验中,我们发现中文自适应的 CPT 模型很难在英语和代码等基准测试(例如 MMLU 和 MBPP)中保持原有的性能,这可能是预训练数据和 CPT 数据之间存在数据分布差异的原因,这也在我们对比的那些基线模型上得到体现。实验结果表明,我们的方法可以有效地平衡原有能力和新能力,这主要体现在以下两个方面。 1. 主要基准测试:
- 在中文评估基准(如 C-Eval 和 CMMLU)上,Llama-3-SynE 显著优于基础模型 Llama-3(8B),表明我们的方法在提高中文语言能力方面非常有效。
- 在英语评估基准(如 MMLU、MATH 和代码评估基准)上,Llama-3-SynE 表现出与基础模型相当或更好的性能,表明我们的方法有效解决了 CPT 过程中灾难性遗忘的问题。
科学基准测试:
- 在科学评估基准(如 SciEval、GaoKao 和 ARC)上,Llama-3-SynE 的表现明显优于基础模型,尤其在中文科学基准上表现出显著提升(如 GaoKao 生物子榜提升了 25.71)。
总结
本研究提出了一种高效的 CPT 方法,通过精心设计的数据选择、混合和课程策略,显著提升了 Llama-3(8B)的中文语言能力和科学推理能力,同时保持其原有能力。实验结果验证了我们方法的有效性和高效性,为在有限训练预算下进行 CPT 提供了重要参考。