
© 作者|刘子康 机构|中国人民大学研究方向|多模态
本文从相关论文出发,梳理当前用于指令微调的多模态指令集,从收集方法、复杂度与指令侧重点三方面展开介绍。引言:近几个月来,大型语言模型(LLM)在人工智能的各个领域带来了革命性的进展。通过极大的参数量与预训练数据量,LLM克服了以往语言模型存在的问题,真正成为了通用的,具备极强推理能力的语言模型,不仅在许多现有的benchmark上取得了极佳的成绩,还展现出了以往模型从未出现过了涌现能力。 尽管LLM作为语言模型的能力无可挑剔,但它缺少感知其他模态信息的能力,而这对于实现AIGC至关重要。当前的多模态大模型往往通过给大模型添加一个视觉模块,再通过多模态指令微调来进行两个模型的对齐。这之中,多模态指令微调至关重要。本文将从相关论文出发,梳理当前用于指令微调的多模态指令集,从收集方法,复杂度与指令侧重点来介绍它们。
一、多模态指令微调
多模态指令微调,即将纯文本的指令微调拓展到多模态形式,并期望通过这些指令以及新增的视觉模块赋予LLM视觉感知以及结合视觉信息进行正常推理的能力。在多模态指令出现之前,应用LLM解决一些复杂的视觉推理问题往往只能将图像转化为对应的caption,并将问题与caption一同作为纯文本的输入送入大型语言模型进行推理。这一类方法的代表为PiCa[1],它通过caption来让gpt3感知图像信息,再通过in-context-learning来引导gpt3完成对应任务。
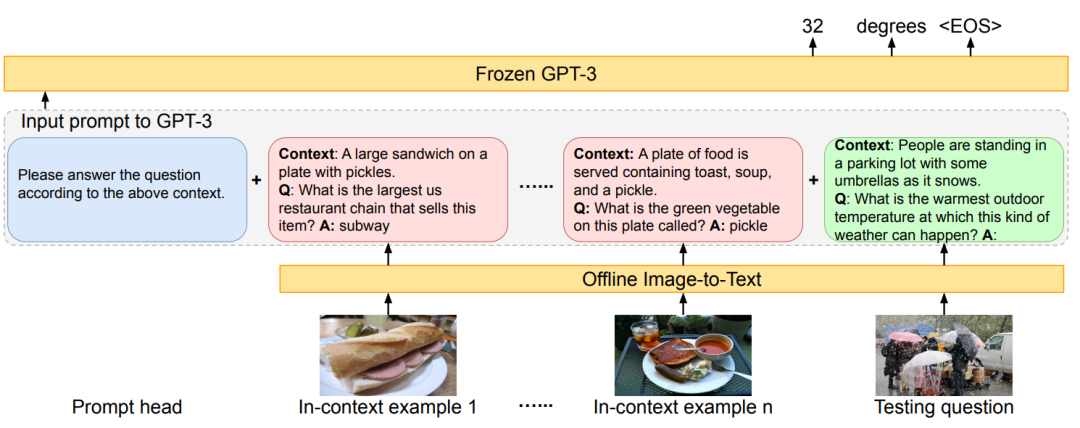
除此之外,Visual-ChatGPT[2]也采用了类似的方式来完成相关任务。通过调用一系列的子模型,Visual-ChatGPT将其他模态的信息转换成图像信息,再利用ChatGPT作为大脑进行推理,最终生成最终结果。
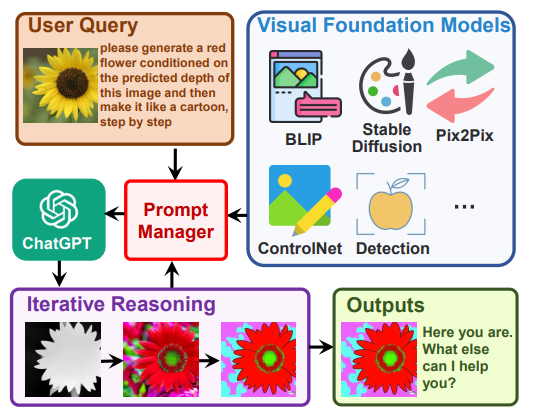
尽管这些模型在一系列任务上有非凡的表现,它的缺点也同样明显。一方面,由于其他模态信息到文本的转换需要利用到一系列的小模型,最终模型的表现在很大程度上会受到小模型性能的限制。同时,文本作为连接不同模态的桥梁是不足的,一段描述的文本很难完全的覆盖到一张图片的所有信息,因此会导致信息的失真,最终影响到模型的推理结果。因此,我们需要训练一个端到端的模型。已有的很多工作已经可以将图像输入映射到文本空间中(如CLIP[3]),我们需要一个多模态指令集,既包含了原本的两种模态的对齐数据,也包含了基于多模态信息的复杂推理与对话数据。本文将在后面介绍这一类指令。
二、多模态指令 * MULTIINSTRUCT: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning
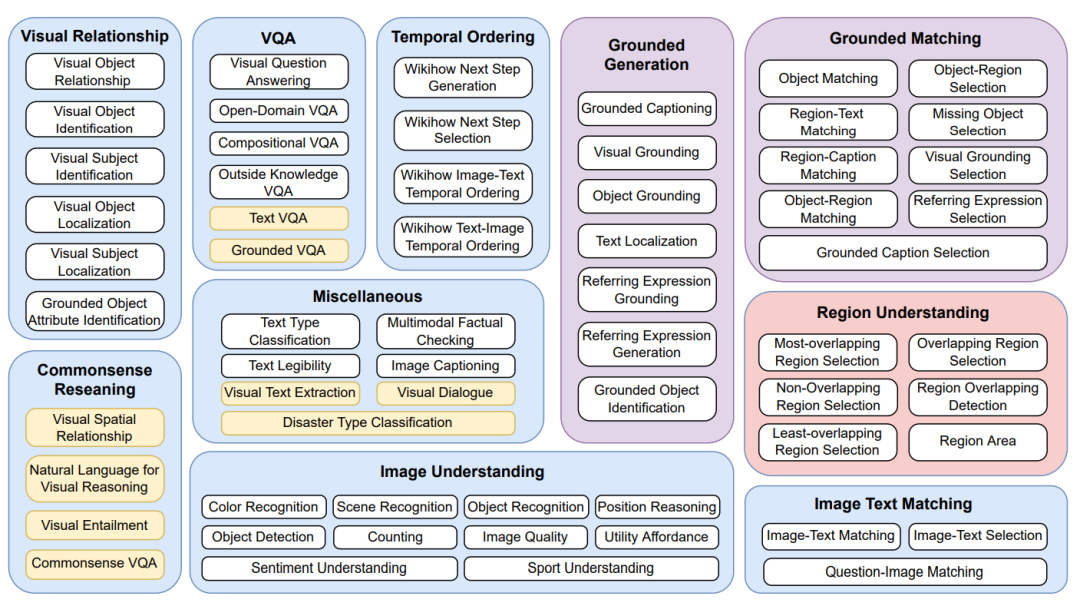
本文是在LLaMA出现前的一篇工作,非常具有前瞻性。作者提出了一个指令数据集-MultiInstruct,包含了当下的34个多模态任务,并将其划分成了若干个任务组。整体指令沿用了Flan[4]指令集的风格,由人工标注者们先根据任务本身的类型描述来标注每个任务的instruction,再经过多个步骤确认每个任务指令的准确性以及保证任务之间的指令不发生冲突。基于当前构造的指令数据集,作者还加入了纯文本的NATURAL INSTRUCTIONS[5]指令集,并通过一系列实验证明了纯文本指令集的加入能够有效提高模型的敏感度-即模型对于不同或轻微改变的指令下生成相同答案的一致性。
- Visual Instruction Tuning
本文提出了一个多模态大模型-LLaVA,是LLaMA出现后的多模态微调工作。本文采用对话微调后的Vicuna模型作为基座,期望能够增强模型基于多种模态的对话能力。LLaVA采用的多模态指令主要follow了Vicuna[6]指令集的形式,没有包含比较复杂的任务描述。为了增强模型在通用场景下的多模态对话与推理能力,LLaVA使用了ChatGPT/GPT-4来辅助多模态的指令生成。具体而言,LLaVA首先将图像转换为由文本表示的Context,为了尽可能的降低图像到文本转换的失真程度,作者采用了两种Context,一种是captions,包含了全局的描述信息。另一种是boxes,包含了细粒度的实体-位置信息。

基于这一类信息,作者向GPT-4输入了一系列指令,这一系列指令包含了对话类型指令,包含了对图像细粒度推理的指令与基于图像的复杂推理指令。由于GPT-4自身非常强大的推理能力,它能够提供有意义的回复数据作为后续训练的多模态指令。最终自动化构造的指令集包含158K个多模态指令,基于这些指令训练得到的LLaVA模型在通用的多模态问答对话上表现出了强大的能力。 * GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest
GPT4RoI是构建细粒度多模态指令的一个尝试。此前的绝大多数多模态指令都着重关注全局的视觉理解与视觉推理,而忽略了局部的细粒度视觉特征。GPT4RoI希望能够构建一个数据集,辅助多模态模型不仅能够从全局层面来理解图像,同样能够理解图像的细粒度特征,从而可以完成一些更加复杂的图像推理任务。本文构造了两类用于不同阶段训练的多模态指令,第一阶段指令用于训练区域特征与实体的对齐,第二阶段指令用于训练包含区域特征的推理。大部分指令由原本的RefCOCO与Visual Genome等数据集中抽取而来,同时也利用了外部工具对原本的LLAVA-150K数据集构建了额外的细粒度标注。
与GPT4RoI类似,Shikra同样对多模态指令在细粒度层面进行了扩展。相较于GPT4RoI更加注重于在指令输入端细粒度的增加,Shikra同时希望模型在输出端能够显式的进行细粒度的推理,输出更多样化的结果。Shikra的主要灵感来源于人类对话中实体指代的存在,即在对话中会提及到一系列的实体,而这些实体应当对应到图像的某一个具体区域。
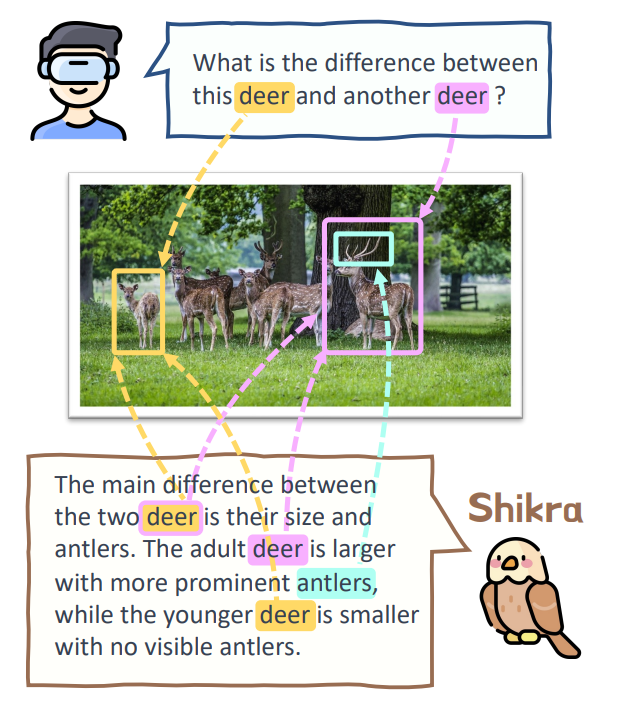
为了构造这些指令,Shikra同样借助到了GPT4的帮助。作者从高质量的细粒度标注数据集Flickr30K出发,Flickr30K中的每一个图像包含了5个细粒度的实体标注以及对应的caption描述。这些实体描述和对应的具体坐标将会被送入GPT4中帮助它们理解实体在图像中的问题。最后,基于这些实体,GPT4将会设计一系列的问答对,这些问题被保证是可以完全通过已有信息来回答的。

作为一个通用指令集,基于Shikra训练的通用模型在一系列指代任务上取得了非常好的效果,同时由于生成文本指定了图像的实体,也有效的降低了多模态幻象的产生。 * M3IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning
M3IT同样是一个大型的多任务多模态指令集。它包含了8个大类的任务集合,并采取了类似MultiInstruct的方式进行指令的人工标注。M3IT的创新点在于,它考虑到了原有的多模态数据集(如VQA)中会存在大量的信息量较少的“短答案”,即对于一个问题仅提供一个极短的精确答案,但没有提供中间过程,而多模态大模型则希望能够提供更加详细,有效的回复。为了解决这个问题,M3IT对于这一类问题进行了答案的复写,通过一些额外的图像信息(例如OCR)来使得答案变得复杂化与多样化。同时,为了支持多语言的多模态指令,M3IT对于一些重要的数据集的指令进行了翻译,使其同时支持中英两种语言。最终,经过人工和ChatGPT的双重质量检测过程,得到了一个包含了2,429,264个实例的多模态多语言指令集。基于M3IT指令集训练的多模态模型在生成答案的ROUGE-L分数和多语场景下表现出了良好的性能。
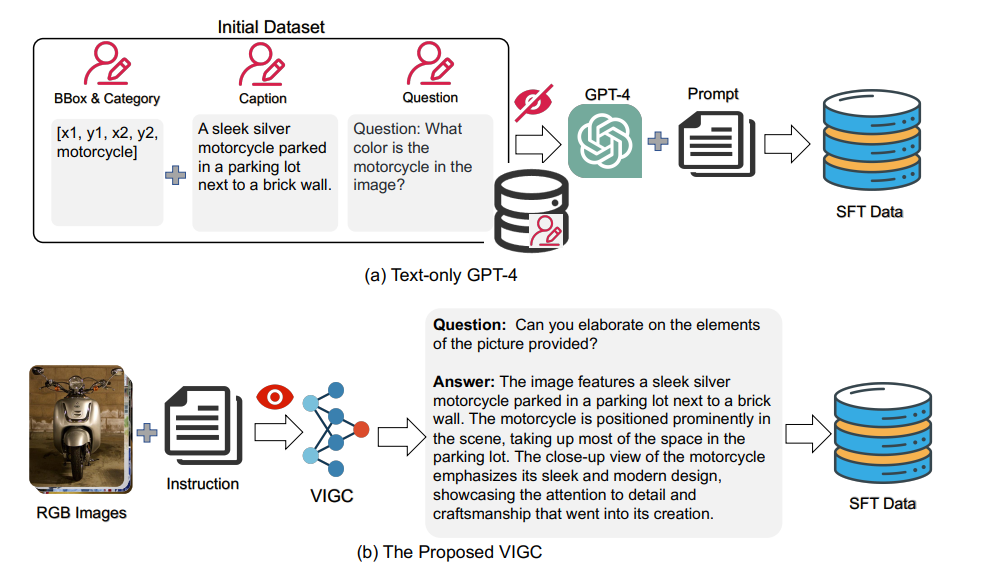
VIGC: Visual Instruction Generation and Correction
VIGC是一种新式的多模态指令生成技术。此前的方法往往采用ChatGPT或GPT4进行对话生成,而图像信息通过Caption或box等其他信息以文字的形式输入到模型之中。这种方式会导致图像信息的失真,从而导致生成对话的失真,即生成对话不一定是与图像紧密相关的,或者有一些细节错误以及幻象的出现。VIGC借助了LLM中self-instruct的思想,通过多模态模型自身来生成指令。具体做法是基于已有或自动生成的指令,通过多模态模型生成回复。对于这些回复,通过ChatGPT来进行检查修正,从而得到高质量的多模态指令集。VIGC既可以用于多模态指令集的生成,也可以用于已有任务指令集的增广。通过这一类方式,基于VIGC的若干个模型在数个通用benchmark以及一些任务特定的benchmark都取得了提升,证明了该方法的有效性。
StableLLaVA: Enhanced Visual Instruction Tuning with Synthesized Image-Dialogue Data
StableLLaVA是一种基于Stable Diffusion来完全的自动化生成多模态指令集的方案。当前的多模态指令集往往采用现有的图像,通过ChatGPT来生成后续的对话。这样的方法尽管有效,但现有的图像数据集会存在一定的领域偏差,同时,生成的多模态对话严重依赖于真实图像,会影响到生成多模态对话的多样性与质量。一种很自然的想法是,借助当前AIGC领域所取得的巨大成功,可以通过扩散模型自由的生成任意类型的图像,再通过ChatGPT生成任意类型的对话,如下图所示:

在这种设定下,图像和对话可以有关几乎任何主题,甚至是超现实的,极大的提高了多模态模型的想象力与创造性。在具体做法上,作者通过ChatGPT来生成扩散模型的prompt,基于若干个基础关键词与场景,再加上一些额外的指令引导(如“生成一段笑话”),可以得到非常多样化的生成图像。基于生成图像以及图像的prompt,再通过ChatGPT生成一系列图像相关的对话。基于StableLLaVA训练的多模态模型在非真实场景与真实场景的benchmark中都取得了不错的表现。
参考文献:
[1]An empirical study of gpt-3 for few-shot knowledge-based vqa [2]Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models [3]Learning Transferable Visual Models From Natural Language Supervision [4]Finetuned Language Models are Zero-Shot Learners [5]Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks [6]Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality [7]MULTIINSTRUCT: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning [8]Visual Instruction Tuning [9]GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest [10]Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic [11]M3IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning [12]VIGC: Visual Instruction Generation and Correction [13]StableLLaVA: Enhanced Visual Instruction Tuning with Synthesized Image-Dialogue Data
