

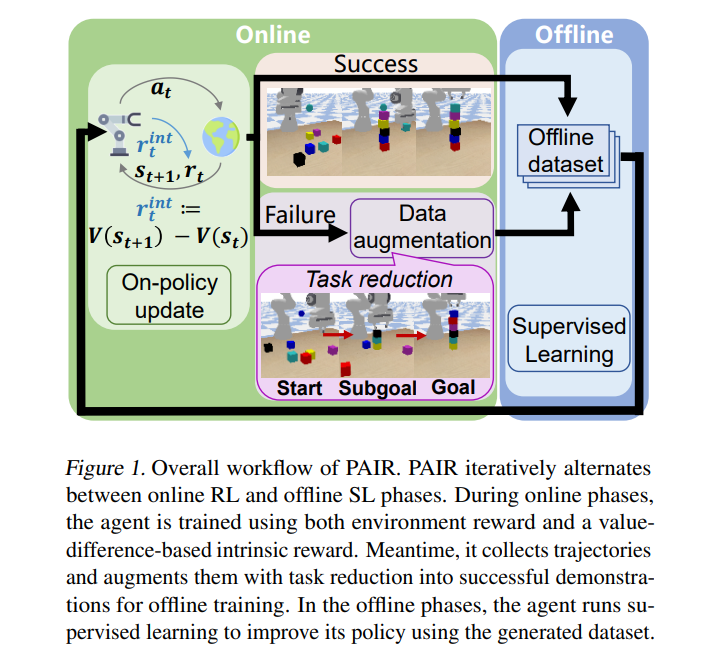
利用监督学习(SL)的力量开发更有效的强化学习(RL)方法已经成为最近的一种趋势。为了解决稀疏奖励目标条件问题**,我们提出了一种新的分阶段方法,即在线反馈学习和离线反馈学习交替进行**。在在线阶段,我们执行RL训练并收集上线数据,而在离线阶段,我们对数据集中成功的轨迹执行SL。为了进一步提高样本效率,我们在在线阶段采用了额外的技术,包括减少任务生成更可行的轨迹和基于价值差异的内在奖励来缓解稀疏奖励问题。我们称这种整体算法为PhAsic自拟约简(PAIR)。在稀疏奖励目标条件机器人控制问题(包括具有挑战性的堆叠任务)上,PAIR大大优于非相位RL和相位SL基线。PAIR是第一个RL方法,它学习了从零开始堆叠6个立方体,只有0/1的成功奖励。
https://www.zhuanzhi.ai/paper/007d9cb1ce12650d123764621e0b319d
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年8月17日


相关VIP内容
相关资讯