

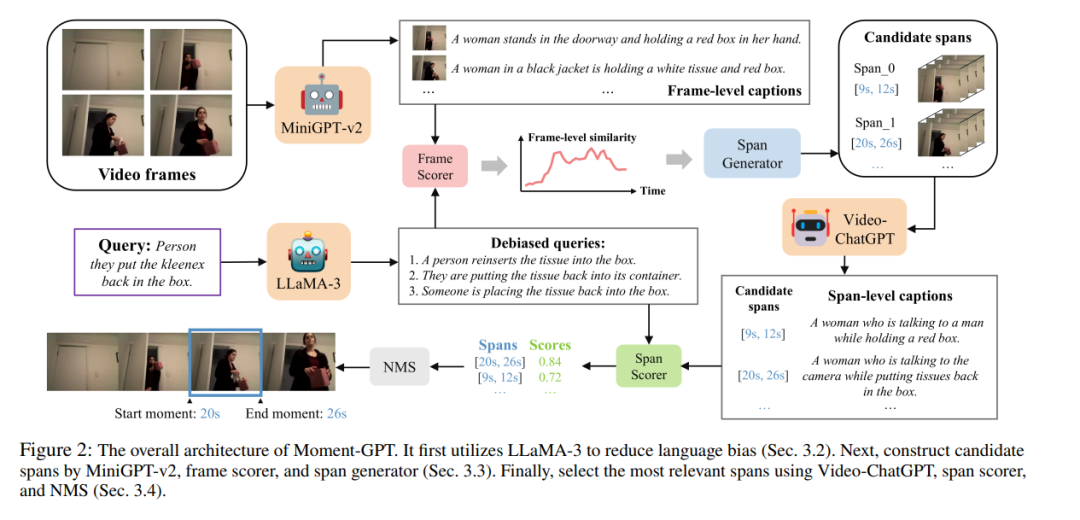
视频时刻检索(VMR)的目标是预测视频中的时间跨度,这些时间跨度在语义上与给定的语言查询匹配。现有的基于多模态大型语言模型(MLLM)的VMR方法过度依赖昂贵的高质量数据集和耗时的微调。尽管一些近期的研究引入了零-shot设定以避免微调,但它们忽视了查询中固有的语言偏差,从而导致错误的定位。为了应对上述挑战,本文提出了Moment-GPT,一个基于冷冻MLLM的零-shot视频时刻检索无调优管道。具体而言,我们首先使用LLaMA-3来修正和重述查询,以减轻语言偏差。随后,我们设计了一个与MiniGPT-v2结合的跨度生成器,能够自适应地生成候选跨度。最后,为了利用MLLM的视觉理解能力,我们应用了VideoChatGPT和跨度评分器来选择最合适的时间跨度。我们提出的方法在多个公开数据集上,显著优于现有的基于MLLM的最先进方法和零样本模型,包括QVHighlights、ActivityNet-Captions和Charades-STA。
成为VIP会员查看完整内容
相关内容
Arxiv
190+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
190+阅读 · 2023年4月7日