

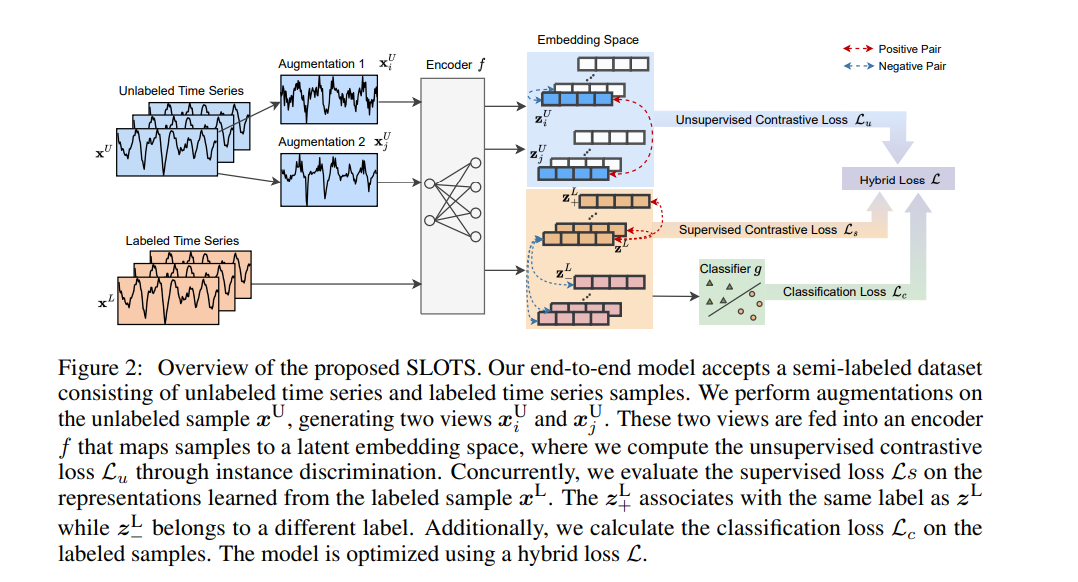
时间序列分类在金融、医疗和传感器数据分析等多个领域都是一个关键任务。无监督的对比学习在从标签有限的时间序列数据中学习有效表示方面引起了广泛关注。现有的对比学习方法中普遍的方法包括两个独立的阶段:在无标签数据集上预训练编码器,然后在小规模有标签数据集上对经过良好训练的模型进行微调。然而,这种两阶段方法存在几个缺点,例如:无监督预训练对比损失不能直接影响下游的微调分类器,以及缺乏利用由有价值的真实标签指导的分类损失。在本文中,我们提出了一个名为SLOTS(半监督时间分类学习)的端到端模型。SLOTS接收半标签数据集,其中包含大量的无标签样本和少量的有标签样本,并通过编码器将它们映射到一个嵌入空间。我们不仅计算无监督的对比损失,而且在具有真实标签的样本上测量有监督的对比损失。学到的嵌入被送入一个分类器,并使用可用的真实标签计算分类损失。无监督、有监督对比损失和分类损失被联合用来优化编码器和分类器。我们通过与五个数据集上的十种最先进方法进行比较来评估SLOTS。结果表明,与两阶段框架相比,我们的端到端SLOTS使用相同的输入数据,消耗类似的计算成本,但提供了明显优化的性能。我们在 https://anonymous.4open.science/r/SLOTS-242E 发布了代码和数据集。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年11月30日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年11月30日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日