

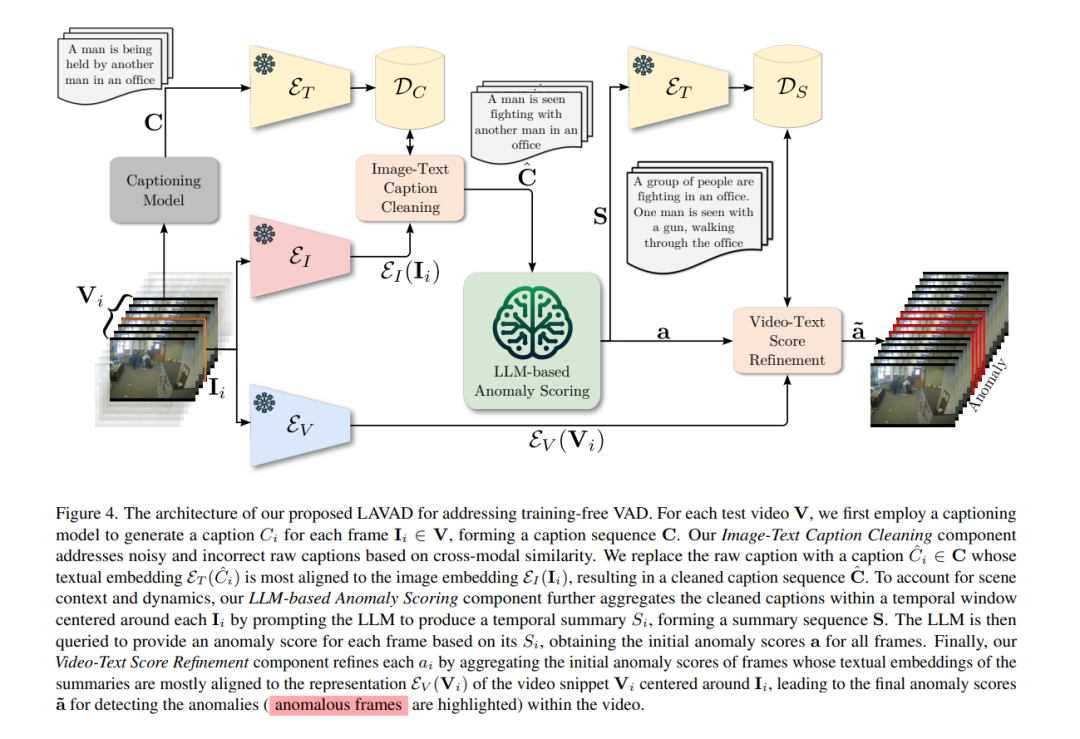
视频异常检测(VAD)旨在视频中临时定位异常事件。现有工作大多依赖于训练深度模型学习正常性的分布,无论是通过视频级监督、单类监督,还是在无监督设置中。基于训练的方法倾向于是领域特定的,因此对于实际部署而言成本高昂,因为任何领域的变化都将涉及数据收集和模型训练。在本文中,我们从根本上脱离之前的努力,提出了一种基于语言的VAD(LAVAD)方法,这是一种新颖的、无需训练的范式,利用了预训练的大型语言模型(LLMs)和现有的视觉-语言模型(VLMs)。我们利用基于VLM的字幕模型为任何测试视频的每一帧生成文本描述。有了文本场景描述,我们然后设计了一个提示机制,以解锁LLMs在时间聚合和异常评分估计方面的能力,将LLMs转变为一个有效的视频异常检测器。我们进一步利用模态对齐的VLMs,并提出了基于跨模态相似性的有效技术,用于清理噪声字幕和优化LLM-based的异常分数。我们在两个大型数据集上评估了LAVAD,这些数据集展示了现实世界中的监控场景(UCF-Crime和XD-Violence),显示它在不需要任何训练或数据收集的情况下,就超过了无监督和单类方法。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日