

语言作为查询的参考视频目标分割框架
Language as Queries for Referring Video Object
这篇工作由字节跳动商业化技术团队与香港大学合作完成。 文章提出了在参考视频目标分割(Referring Video Object Segmentation, RVOS)领域进行端到端分割的解决方案。 参考视频目标分割(RVOS)任务需要在视频中将文本所指代的参考对象进行实例分割,与目前得到广泛研究的参考图像分割(RIS)相比,其文本描述不仅可以基于目标的外观特征或者空间关系,还可以对目标所进行的动作进行描述,这要求模型有着更强的时空建模能力,且保证分割目标在所有视频帧上的一致性;与传统的视频目标分割(VOS)任务相比,RVOS 任务在预测阶段没有给定分割目标的真值,从而增加了对目标进行正确精细分割的难度。
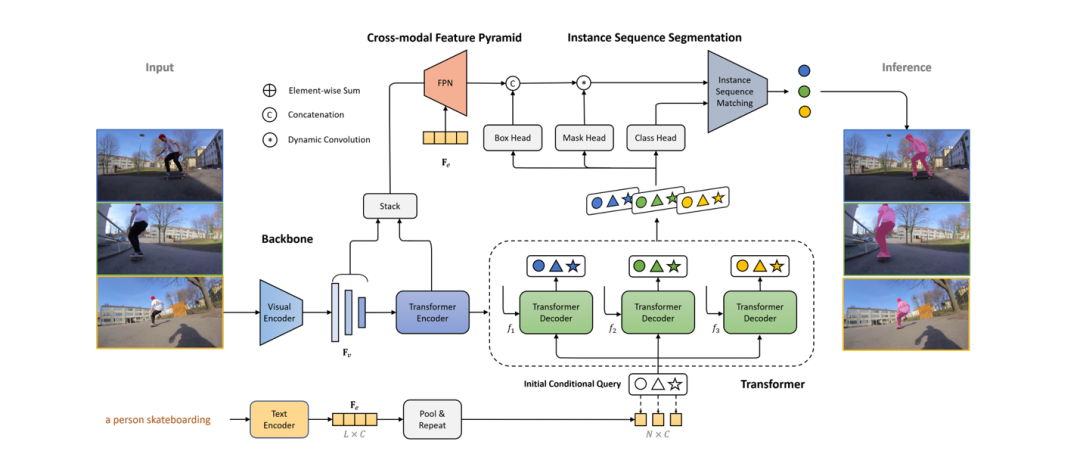
现有的 RVOS 方法往往都依赖于复杂的多阶段框架,以保证分割目标的一致性。为了解决以上问题,本文提出了一种基于 Transformer 的端到端 RVOS 框架 —— ReferFormer,其将语言描述作为查询条件,在视频中仅仅关注于参考目标,并采用动态卷积对目标进行分割;除此之外,通过连接不同帧上相对应的查询进行实例的整体输出,可自然地完成目标的追踪,无需任何后处理。该方法在四个 RVOS 数据集上(Ref-Youtube-VOS, Ref-DAVIS17, A2D-Sentences, JHMDB-Sentences)均取得了当前最优的性能。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年6月14日
Arxiv
13+阅读 · 2020年8月11日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年6月14日
Arxiv
13+阅读 · 2020年8月11日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日