一文带你入门视频目标分割(附数据集)

来源:机器之心
本文长度为2413字,建议阅读5分钟
本文从视频目标分割简介、数据集和DAVIS挑战赛入手,并介绍两种主要的视频目标分割方法。
近日 Visualead 研究主管 Eddie Smolyansky 在 Midum 网站撰文介绍视频目标分割的基础知识,从视频目标分割问题简介、数据集和 DAVIS 挑战赛入手,同时介绍了 Visualead 最新发布的视频数据集 GyGO 和 2016 年以来两种主要的视频目标分割方法:MaskTrack 和 OSVOS。

DAVIS-2016 视频物体分割数据集中经过正确标注的几个帧
本文介绍了视频目标分割问题和对应的经典解决方案,简要概括为:
问题、数据集和挑战赛;
我们今天要宣布的新数据集;
自 2016 年以来使用的两种主要方法:MaskTrack 和 OSVOS。
文章假设读者已经熟悉计算机视觉和深度学习领域的一些概念。我希望能对 DAVIS 挑战赛进行一个清晰易懂的介绍,让新手也能快速进入状态。
介绍
计算机视觉领域中和目标有关的经典任务有三种:分类、检测和分割。其中分类是为了告诉你“是什么”,后面两个任务的目标是为了告诉你“在哪里”,而分割任务将在像素级别上回答这个问题。
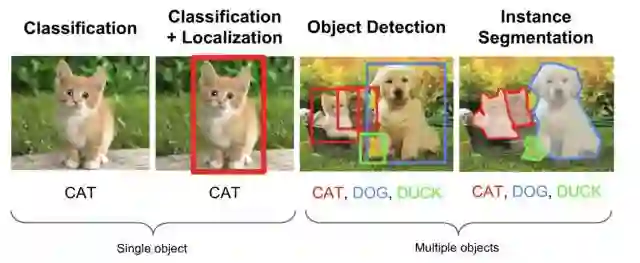
经典计算机视觉任务(图像来自 Stanford cs231n 课程幻灯片)
2016 年语义分割领域出现了很成熟的技术,甚至开始接近现有数据集的饱和性能。与此同时,2017 年也是各种视频处理任务爆发性增长的一年:动作分类、动作(时序)分割、语义分割等等。这里我们将着眼于视频目标分割。
问题、数据集、挑战赛
视频目标分割任务和语义分割有两个基本区别:
视频目标分割任务分割的是一般的、非语义的目标;
视频目标分割添加了一个时序模块:它的任务是在视频的每一连续帧中寻找感兴趣目标的对应像素。
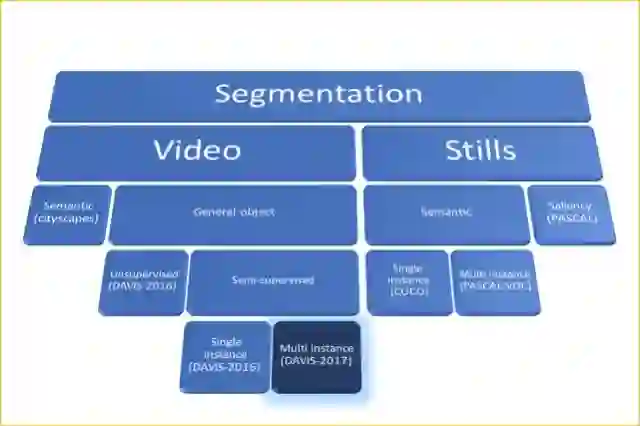
分割的细分。图中每一叶都有一个示例数据集
基于视频任务的特性,我们可以将问题分成两个子类:
无监督(亦称作视频显著性检测):寻找并分割视频中的主要目标。这意味着算法需要自行决定哪个物体才是主要的。
半监督:在输入中(只)给出视频第一帧的正确分割掩膜,然后在之后的每一连续帧中分割标注的目标。
半监督案例可以扩展为多物体分割问题,我们可以在 DAVIS-2017 挑战赛中看到。

DAVIS-2016 (左) 和 DAVIS-2017 (右) 标注的主要区别:多物体分割(multi-instance segmentation)
我们可以看到,DAVIS 是一个像素完美匹配标注的数据集。它的目标是重建真实的视频场景,如摄像机抖动、背景混杂、遮挡以及其它复杂状况。
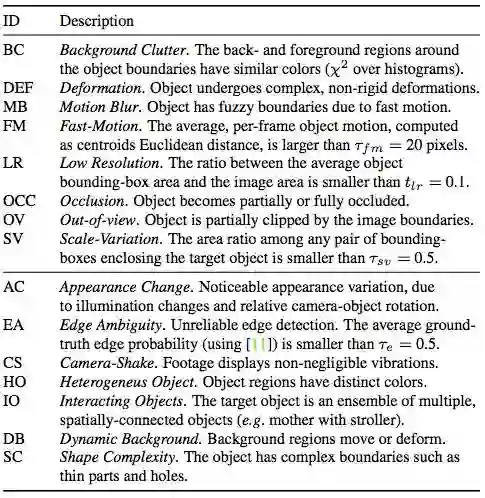
DAVIS-2016 的复杂度属性
有两个度量分割准确率的主要标准:
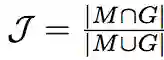
区域相似度(Region Similarity):区域相似度是掩膜 M 和真值 G 之间的 Intersection over Union 函数
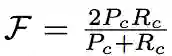
轮廓精确度(Contour Accuracy):将掩膜看成一系列闭合轮廓的集合,并计算基于轮廓的 F 度量,即准确率和召回率的函数。即轮廓精确度是对基于轮廓的准确率和召回率的 F 度量。
直观上,区域相似度度量标注错误像素的数量,而轮廓精确度度量分割边界的准确率。
新的数据集!GyGO:电商视频目标分割数据集(by Visualead)
我们将在未来几个星期内陆续发布 GyGO 的各部分内容,GyGO 是一个专用于电商视频物体分割的数据集,由大约 150 个短视频组成。
数据集地址:https://github.com/ilchemla/gygo-dataset
一方面,视频画面的序列非常简单,几乎没有遮挡、快速移动或者其它提高复杂度的属性。另一方面,这些视频中的物体相比 DAVIS-2016 数据集有更多的类别,其中很多序列包含了已知的语义类别(人类、汽车等)。GyGO 专门搜集智能手机拍摄的视频,因此帧比较稀疏(标注的视频速度只有约 5 fps)。
我们基于以下两个目的公布数据集:
目前关于视频目标分割的数据严重缺乏,只有数百个带标注的视频。我们相信每一次贡献都有望帮助提升算法表现。我们分析认为,在 GyGO 和 DAVIS 数据集上进行联合训练,视频目标分割任务能得到更好的结果。
为了推进更加开放共享的文化,鼓励其他研究人员加入我们。:) DAVIS 数据集和能促进其生长的研究生态系统给我们提供了很大的帮助,我们也希望社区能够从中受益。
DAVIS-2016 中的两个主要方法
随着用于单一目标分割的 DAVIS-2016 数据集的公布,两个最重要的方法出现了: OSVOS 和 MaskTrack。在 DAVIS-2017 挑战赛的参赛团队中,每一支队伍都想构建超越这两者的解决方案,它们俨然已经成为经典。让我们看看它们是怎么工作的:
单次视频目标分割(One Shot Video Object Segmentation,OSVOS)
OSVOS 背后的概念简单而强大:
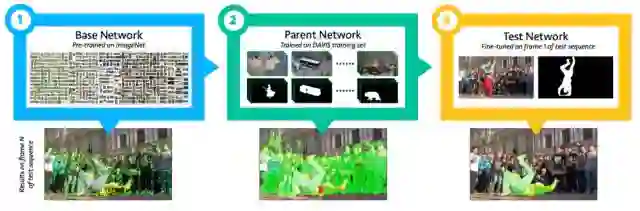
OSVOS 训练流程
1. 选择一个网络(比如 VGG-16)在 ImageNet 上进行分类预训练。
2. 将其转换为全连接卷积网络(FCN),从而保存空间信息:
训练结束时删去 FC 层。
嵌入一个新的损失函数:像素级 sigmoid 平衡交叉熵(pixel-wise sigmoid balanced cross entropy,曾用于 HED)。现在,每一个像素都可以被分类成前景或背景。
3. 在 DAVIS-2016 训练集上训练新的全连接卷积网络。
4. 单次训练:在推断的时候,给定一个新的视频输入进行分割并在第一帧给出真实标注(记住,这是一个半监督问题),创建一个新模型,使用 [3] 中训练的权重进行初始化,并在第一帧进行调整。
这个流程的结果,是适用于每一个新视频的唯一且一次性使用的模型,由于第一帧的标注,对于该新视频而言,模型其实是过拟合的。由于大多数视频中的目标和背景并不会发生巨大改变,因此这个模型的结果还是不错的。自然,如果该模型用于处理随机视频序列时,则它的表现得就没那么好了。
注意:OSVOS 方法是独立地分割视频的每一帧的,因此视频中的时序信息是没有用的。
MaskTrack(从静态图像学习视频目标分割)
OSVOS 独立地分割视频的每一帧,而 MaskTrack 还需要考虑视频中的时序信息:
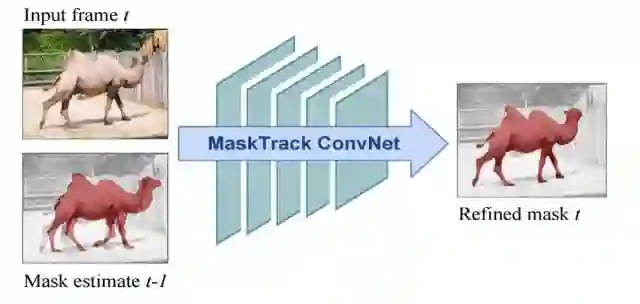
MaskTrack 的 Mask 传播模块
每一个帧将前一帧的预测掩膜作为额外输入馈送给网络:现在输入有四个通道 (RGB+前一帧的掩膜)。使用第一帧的真实标注初始化该流程。
该网络原本建立在 DeepLab VGG-16(模块化)基础上,现在在语义分割和图像显著性数据集上从头开始进行训练。通过将每一张静态图像的真实标注稍微转换,人工合成前一帧的掩膜通道输入。
基于光流场输入增加一个相同的第二流网络。模型的权重和 RGB 流的权重相同。通过将两个结果取平均融合两个流的输出。
在线训练:用第一帧的真实标注合成额外的、针对特定视频的训练数据。
注意:这两个方法都依赖于静态图像训练(与静态图像数据集相反,视频数据集较少且规模较小)。
综上所述,在这篇介绍性文章中我们了解了视频目标分割问题和 2016 年的最优解决方案。
P.S. 这里我想感谢 DAVIS 数据集和挑战赛背后的团队做出的杰出贡献。
参考文献
文中提到和分析过的主要文献:
1. Benchmark Dataset and Evaluation Methodology for Video Object Segmentation F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung, Computer Vision and Pattern Recognition (CVPR) 2016
2. The 2017 DAVIS Challenge on Video Object SegmentationJ. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbeláez, A. Sorkine-Hornung, and L. Van Gool, arXiv:1704.00675, 2017
3. Learning Video Object Segmentation from Static Images F. Perazzi, A. Khoreva, R. Benenson, B. Schiele, A. Sorkine-Hornung CVPR 2017, Honolulu, USA
4. One-Shot Video Object Segmentation, S. Caelles, K.K. Maninis, J. Pont-Tuset, L. Leal-Taixé, D. Cremers, and L. Van Gool, Computer Vision and Pattern Recognition (CVPR), 2017
原文链接:https://medium.com/@eddiesmo/video-object-segmentation-the-basics-758e77321914
编辑:文婧




