CVPR 2022 | 刷新4个SOTA!港大&字节开源ReferFormer: 语言作为查询的参考视频目标分割框架

极市导读
来自香港大学和字节跳动的研究者们提出了一种基于Transformer的参考视频目标分割新框架ReferFormer。其将语言描述视为查询条件,直接在视频中查找目标对象,除此之外,通过实例序列的整体输出自然地完成目标物体的跟踪,无需进行任何后处理。ReferFormer在四个参考视频目标分割数据集上都取得了当前最优的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

paper:https://arxiv.org/abs/2201.00487
code: https://github.com/wjn922/ReferFormer
引言
参考视频目标分割(referring video object segmentation,RVOS)是一个新兴且具有挑战性的多模态任务,它需要在视频中将文本所指代的参考对象进行实例分割。
目前得到广泛研究的参考图像分割(referring image segmentation, RIS)任务中,文本描述通常是基于目标的外观特征或者空间关系,RVOS任务则可以对目标所进行的动作进行描述,这要求模型有着更强的时空建模能力,且保证分割目标在所有视频帧上的一致性;与传统的视频目标分割(video object segmentation, VOS)任务相比,RVOS任务在预测阶段没有给定分割目标的真值,从而增加了对目标进行正确精细分割的难度。
现有的RVOS方法往往都依赖于复杂的多阶段框架,以保证分割目标的一致性。为了解决以上问题,香港大学和字节跳动的研究者们提出了一种基于Transformer的端到端RVOS框架 —— ReferFormer,其将语言描述作为查询条件,在视频中仅仅关注于参考目标,且通过连接不同帧上相对应的查询即可完成目标的追踪,无需进行后处理。该模型在四个RVOS数据集上(Ref-Youtube-VOS, Ref-DAVIS17, A2D-Sentences, JHMDB-Sentences) 均取得了当前最优的性能。
方法亮点:
-
提出了一种简单统一,基于Transformer的端到端RVOS框架,无需进行后处理;
-
将语言描述作为查询的限制条件,从而用很少数量的查询即可完成任务;
-
在四个RVOS任务数据集上都取得了当前最优的性能。
方法
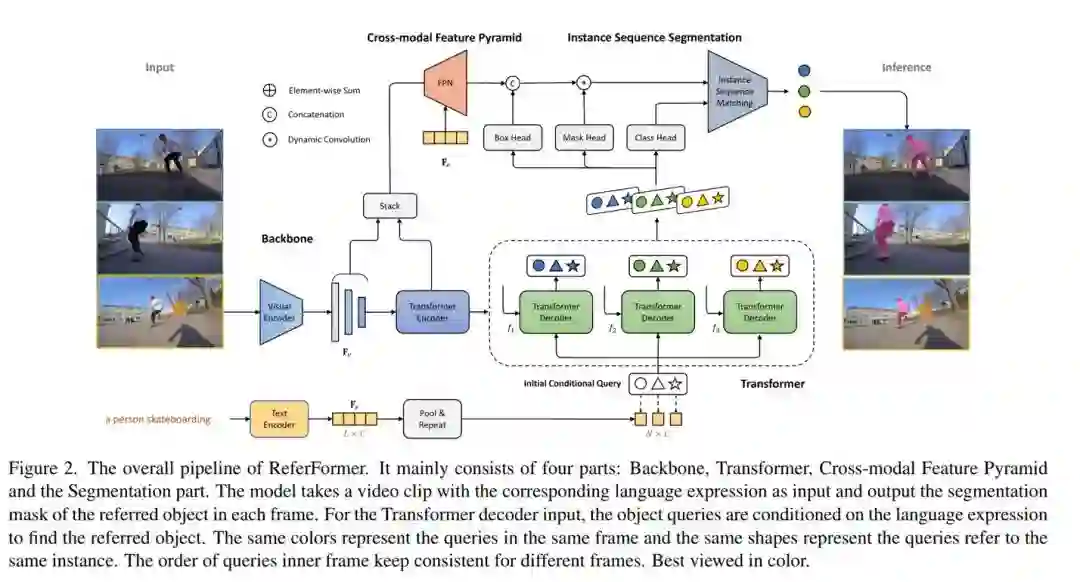
网络主要由四个部分组成:Backbone,Transformer,跨模态FPN以及实例分割生成部分。
Backbone. 网络首先使用视觉编码器从视频中抽取每一帧的特征,同时采用文本编码器获得文本描述的语言特征,该特征进行平均池化后获得的向量即为句特征。
Transformer. Transformer编码器用于进一步建模视频帧的多尺度特征;在解码器部分,定义了N个可学习特征作为query,且为所有帧共享。同时,对上述句特征复制N次,query和句特征共同作为解码器的输入。在这种方式下,所有query都会在语言的指引下仅仅关注于目标对象,因此本文将此查询称为“条件查询(conditional query)”。得益于该设计,模型采用很少数量(默认为5)的query即可获得很好的效果。最终,通过在解码器中进行query和视觉特征的交互,每一帧上均获得含有目标信息的N个表征,对于整个视频,则共有Nq个表征。
跨模态FPN. 在这一部分,视觉特征与文本特征以互注意力的形式进行多尺度、细粒度交互,可以获得更好的分割效果。这一过程中,FPN产生了语义丰富、高分辨率的特征图送入后续分割模块。
实例分割生成部分. 对于前述每一帧上获得的N个表征,首先分别通过class head,box head,mask head生成其对应的二分类概率,边界框以及动态卷积核参数。边界框作为relative coordinate特征添加至FPN的输出特征中,获得每个query对应的卷积特征图,目标mask的生成通过动态卷积得到:
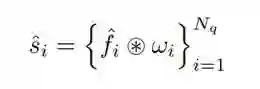
训练和预测. 每一帧上对应位置的query追踪的是同一实例(图中以相同形状表示),将相对应的query进行连接,即可获得属于同一实例的序列,从而自然地对目标进行各种而无需后处理。在训练和预测阶段,均以实例序列视为整体进行监督和输出。
在训练阶段,由于视频中仅含有一个目标物体,因此采用最小代价匹配进行正样本分配,损失函数包括二分类损失,边界框损失以及掩码损失:
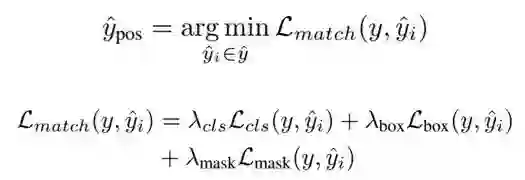
在预测阶段,输入为一整段视频。首先计算每个实例序列在所有帧上的平均得分,选择分数最高的实例序列,其索引为σ,输出其对应的mask序列即可。
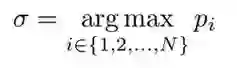
Demo
以下展示了模型在多个具有挑战性场景的分割效果:
- Ref-DAVIS17


- Ref-Youtube-VOS


性能
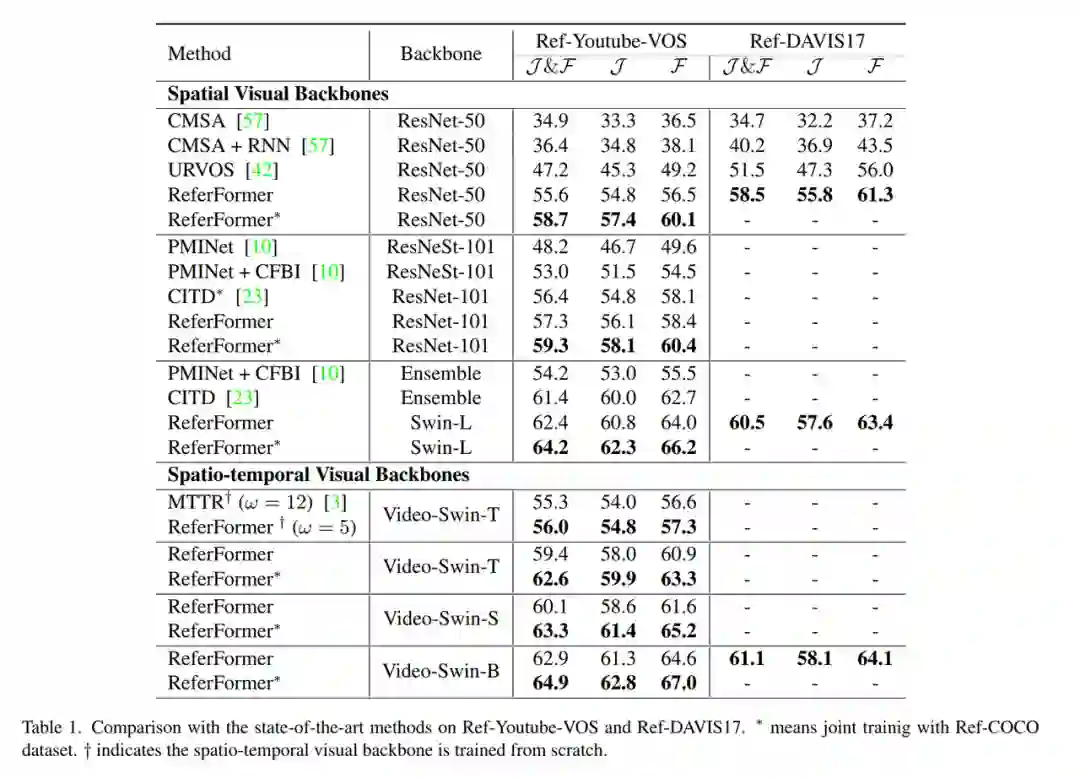
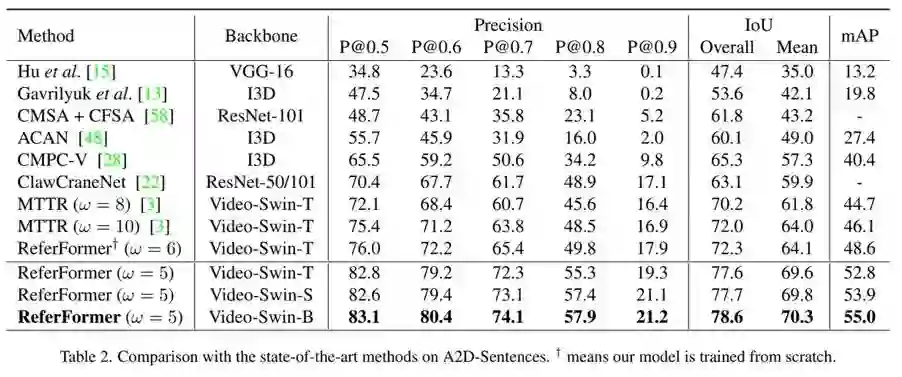
本文采用不同的视觉编码器进行了广泛实验,在当前四个RVOS上均取得了当前最好的性能。其中,Ref-DAVIS17和JHMDB-Sentences的评估采用的分别是在Ref-Youtube-VOS和A2D-Sentences上训练好的模型,证明了方法的泛化性能。
- Ref-Youtube-VOS & Ref-DAVIS17
- A2D-Sentences & JHMDB-Sentences

结论
本文提出了一个简单统一的参考视频目标分割框架,不同于以往复杂、多阶段的pipeline,本文提出了将语言描述作为查询的概念,使得模型能够精准地关注于目标对象,同时通过实例序列匹配自然地完成目标的跟踪,实现了端到端的输出。
公众号后台回复“数据集”获取100+深度学习数据集下载~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




