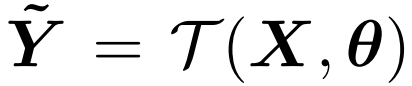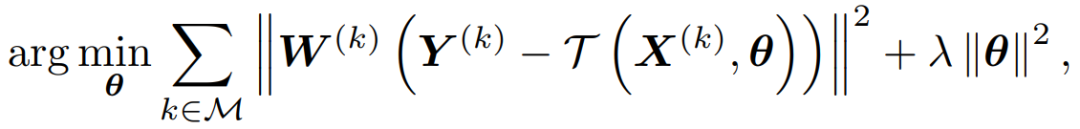本文中,来自美图影像研究院(MT Lab)与大连理工大学卢湖川团队的研究者们共同探究了如何仅使用文本描述作为参考的视频目标分割任务,突破性地提出了首个单阶段方法 ——YOFO,能够有效地进行端到端训练并达到 SOTA 效果。该论文已被 AAAI 2022 接收。
参考视频目标分割(Referring VOS, RVOS)是一个新兴起的任务,它旨在根据参考文本,从一段视频序列中分割出文本所指述的对象。与半监督视频目标分割相比,RVOS 只依赖抽象的语言描述而不是像素级的参考掩膜,为人机交互提供了一种更方便的选择,因此受到了广泛关注。
![]()
论文链接:https://www.aaai.org/AAAI22Papers/AAAI-1100.LiD.pdf
该研究的主要目的是为解决现有 RVOS 任务中所面临的两大挑战:
对此,该研究提出了一种
跨模态元迁移的端到端 RVOS 框架 ——YOFO
,其主要的贡献和创新点为:
只需单阶段推理,即可实现利用参考文本信息直接得到视频目标的分割结果,在两个主流的数据集 ——Ref-DAVIS2017 和 Ref-Youtube-VOS 上获得的效果超越了目前所有二阶段方法;
提出了一个元迁移(Meta-Transfer)模块来增强时序信息,从而实现了更聚焦于目标的特征学习;
提出了一个多尺度跨模态特征挖掘(Multi-Scale Cross-Modal Feature Mining)模块,能够充分融合语言、图片中的有用特征。
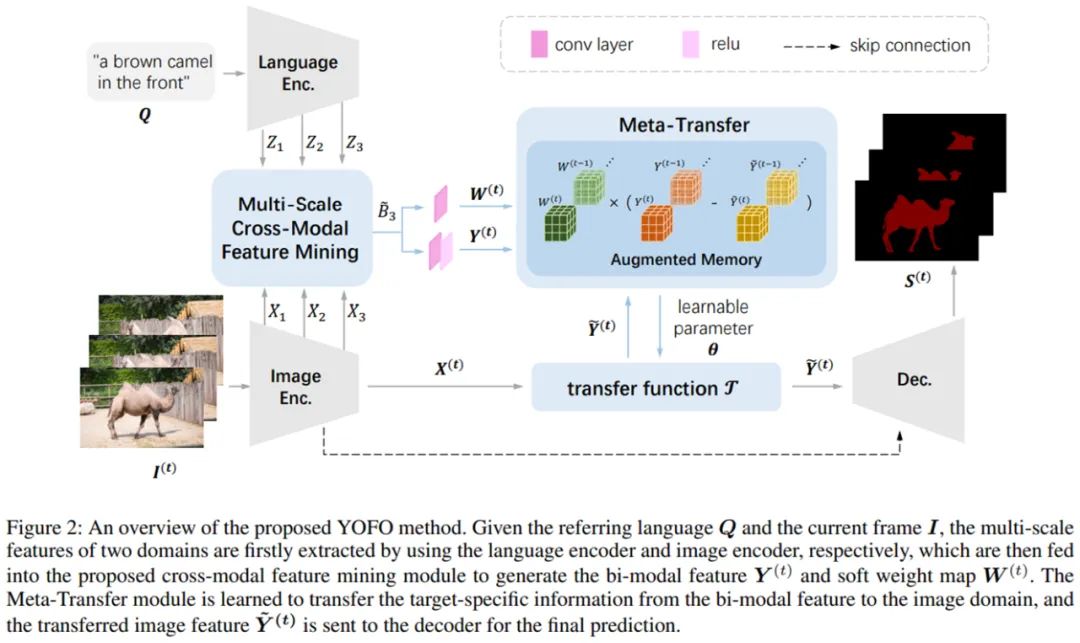
YOFO 框架主要流程如下:输入图片和文本先分别经过图片编码器和语言编码器提取特征,随后在多尺度跨模态特征挖掘模块进行融合。融合后的双模态特征在包含了记忆库的元迁移模块中进行简化,排除掉语言特征中的冗余信息,同时能保存时序信息来增强时间相关性,最后通过一个解码器得到分割结果。
![]()
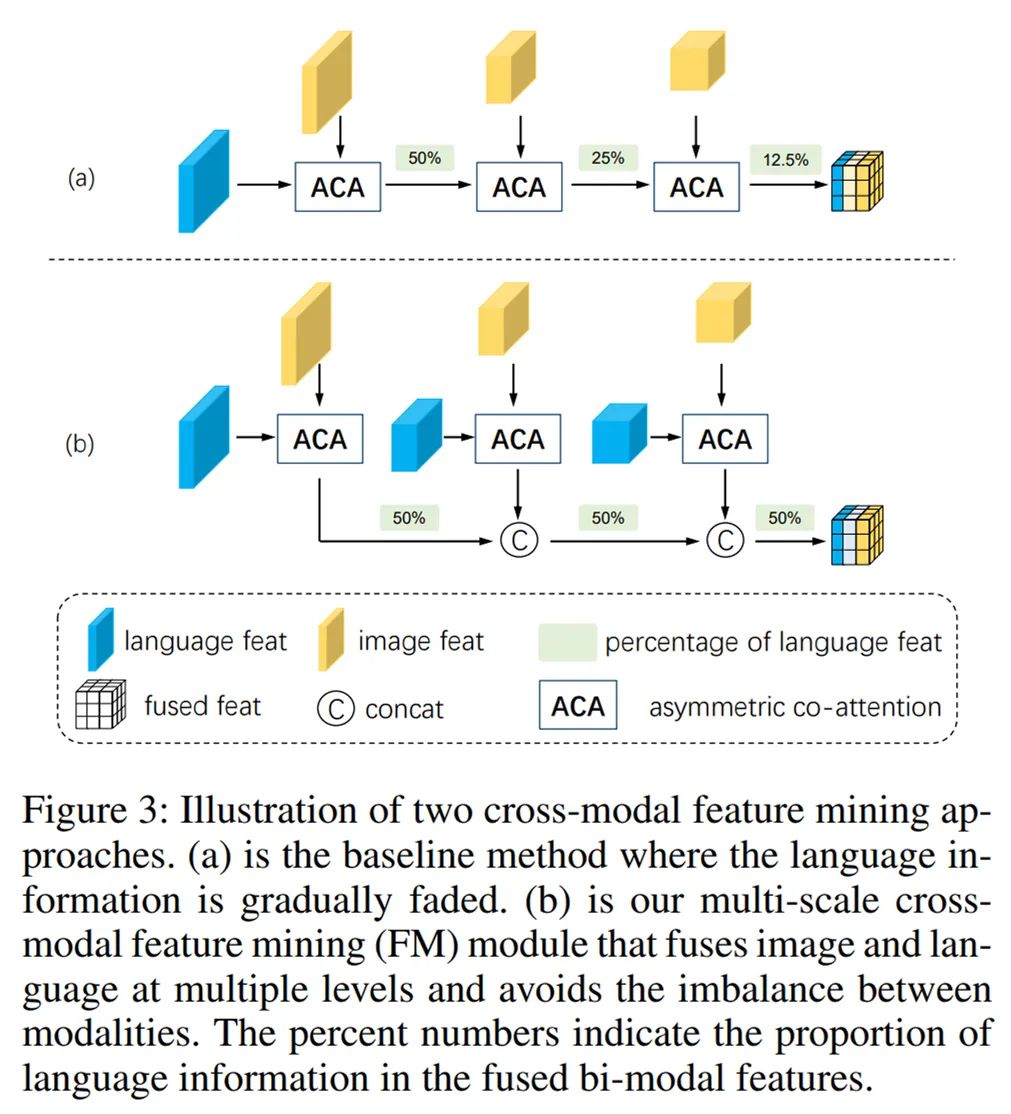
多尺度跨模态特征挖掘模块
:该模块通过逐级融合不同尺度的两个模态特征,能够保持图像特征所传达的尺度信息与语言特征间的一致性,更重要的是保证了语言信息不会在融合过程中被多尺度图像信息所淡化淹没。
![]()
元迁移模块
:采用了一种 learning-to-learn 策略,过程可以简单地描述为以下的映射函数。其中迁移函数
![]() 是一个卷积,则
是一个卷积,则
![]() 是它的卷积核参数:
是它的卷积核参数:
![]()
![]()
其中,M 代表能够储存历史信息的记忆库,W 代表不同位置的权重,能够对特征中不同的位置赋予不同的关注度,Y 代表储存在记忆库中的每个视频帧的双模态特征。该优化过程尽可能地使元迁移函数具有重构双模态特征的能力,同时也使得整个框架能够进行端到端的训练。
训练和测试
:训练时所使用的损失函数是 lovasz loss,训练集为两个视频数据集 Ref-DAVIS2017、Ref-Youtube-VOS,并通过静态数据集 Ref-COCO 进行随机仿射变换模拟视频数据作为辅助训练。元迁移的过程在训练和预测时都要进行,整个网络在 1080ti 上的运行速度达到了 10FPS。
研究采用的方法在两个主流 RVOS 数据集(Ref-DAVIS2017 和 Ref-Youtube-VOS)上均取得了优异的效果,量化指标及部分可视化效果图如下:
![]()
![]()
![]()
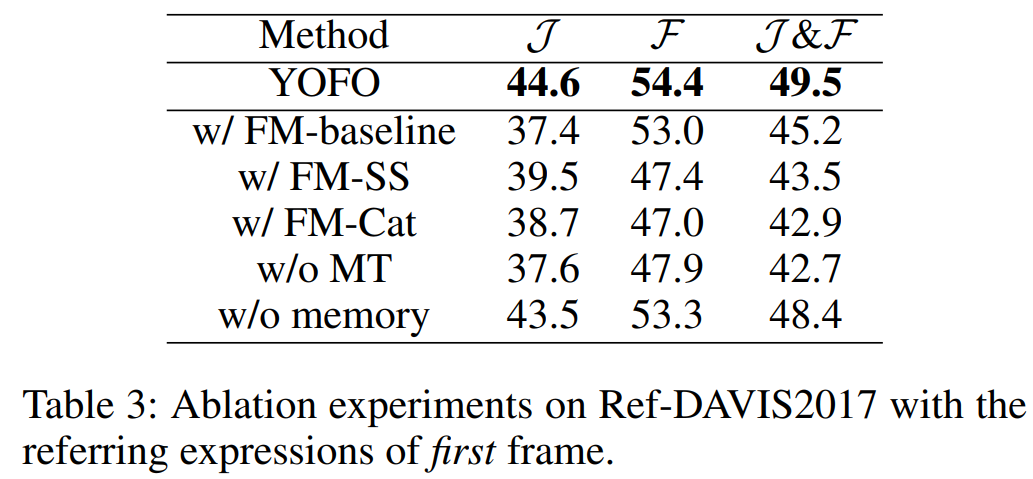
研究还通过一系列的消融实验以说明特征挖掘模块(FM)以及元迁移模块(MT)的有效性。
![]()
图 6:特征挖掘模块(FM)以及元迁移模块(MT)的有效性。
此外,研究分别对使用了 MT 模块和不使用 MT 模块的解码器输出特征进行了可视化,可以明显地看出 MT 模块能够正确地捕捉到语言所描述的内容且对干扰噪声进行过滤。
![]()
图 7:使用 MT 模块前后的解码器输出特征对比。
本论文由美图影像研究院(MT Lab)和大连理工大学卢湖川团队的研究者们共同提出。美图影像研究院(MT Lab)是美图公司致力于计算机视觉、机器学习、增强现实、云计算等领域的算法研究、工程开发和产品化落地的团队,为美图现有和未来的产品提供核心算法支持,并通过前沿技术推动美图产品发展,被称为「美图技术中枢」,曾先后多次参与 CVPR、ICCV、ECCV 等计算机视觉国际顶级会议,并斩获冠亚军十余项。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

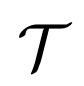 是一个卷积,则
是一个卷积,则
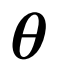 是它的卷积核参数:
是它的卷积核参数: