【CVPR2022】UTC: 用于视觉对话的任务间对比学习的统一Transformer

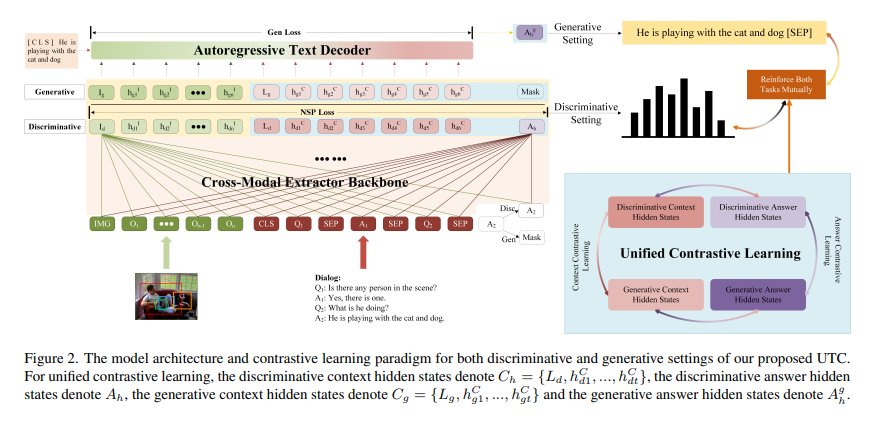
视觉对话旨在回答基于对话历史和图像内容的多轮互动问题。现有方法要么单独考虑答案排序和生成,要么仅通过两个单独的模型微弱地捕捉两个任务之间的关系。在单一模型中共同学习排序和生成答案的通用框架的研究很少。在本文中,我们提出了一个基于对比学习的框架UTC,以统一和促进识别任务和生成任务在视觉对话中使用单一的模型。具体来说,考虑到之前学习范式的内在局限性,我们设计了两种任务间对比损失,即情境对比损失和答案对比损失,使区分性任务和生成性任务相辅相成。这两种互补的对比损失利用对话语境和目标答案作为锚点,从不同的角度提供表征学习信号。我们在VisDial v1.0数据集上评估我们提出的UTC,在那里,我们的方法在鉴别和生成任务上优于最先进的技术,并在Recall@1上超过2个绝对点。
https://www.zhuanzhi.ai/paper/527537bf22a0260715026e0ea474fb5f
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“UTC” 就可以获取《【CVPR2022】UTC: 用于视觉对话的任务间对比学习的统一Transformer》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年6月20日
Arxiv
11+阅读 · 2020年10月20日
Arxiv
16+阅读 · 2020年1月2日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年6月20日
Arxiv
11+阅读 · 2020年10月20日
Arxiv
16+阅读 · 2020年1月2日