自动机器学习
·

深度学习让机器可以从大量的数据中学习经验并加以应用,已经在图像分类、序列标注等多个任务上取得了惊人的成果。但是,这一过程需要大量的人工干预:特征提取、模型选择、参数调节等,既费时又费力。
所以专家们自然而然想到了引入自动化让机器自己“学习如何学习”。然而机器学习的自动化离不开几个关键难题:教授什么知识和配备什么工具?在哪一部分实现自动化?自动化训练如何保证稳定的效果?如何在最短时间内找到又简单又高效的方案?
论文指出,当前的自动机器学习多是在整个流程中的某个或某几个独立分段实现自动化,这种 “半自动” 让搜索自然受限于 “次优” 并导致最终结果的偏差。而且搜索空间往往“精心设计”,与自动学习的初衷相违背,实际落地时也易出现过拟合的情况。很显然,自动机器学习需要对网络结构有更高一级的理解能力。
首先,论文的作者提出了基于终身知识锚点的进化算法。而其中极富创新性的全自动机器学习框架,首次打破了现有自动机器学习中各搜索空间的独立设计,并使用数据集知识锚点加进化算法来加速搜索,解决了在超大空间搜索最优方案的设计难题。
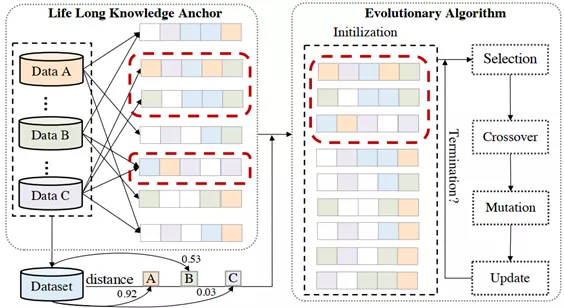
承袭现有的终身学习与元学习思想,该框架中的知识锚点使用了全新的元特征和概率抽样方法,缓解了搜索过程中的过拟合。不仅如此,框架还实现了全流程自动化,极大降低了机器学习应用门槛。用户只需根据提示进行操作,无须了解算法和代码,时间成本很低。
成为VIP会员查看完整内容
相关内容
Arxiv
3+阅读 · 2019年9月3日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年9月3日