国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL)在世界范围内每年召开一次,是自然语言处理领域的顶级会议,被中国计算机协会(CCF)评级为A类会议,今年是第61届会议,将于2023年7月9-14日在加拿大多伦多召开。ACL 2023会议网址https://2023.aclweb.org/

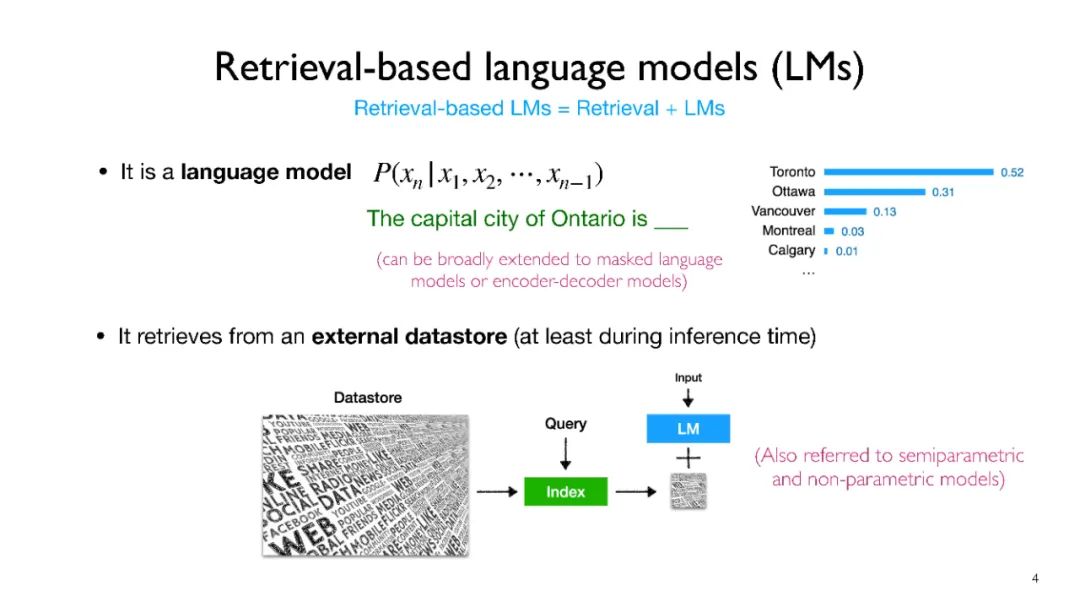
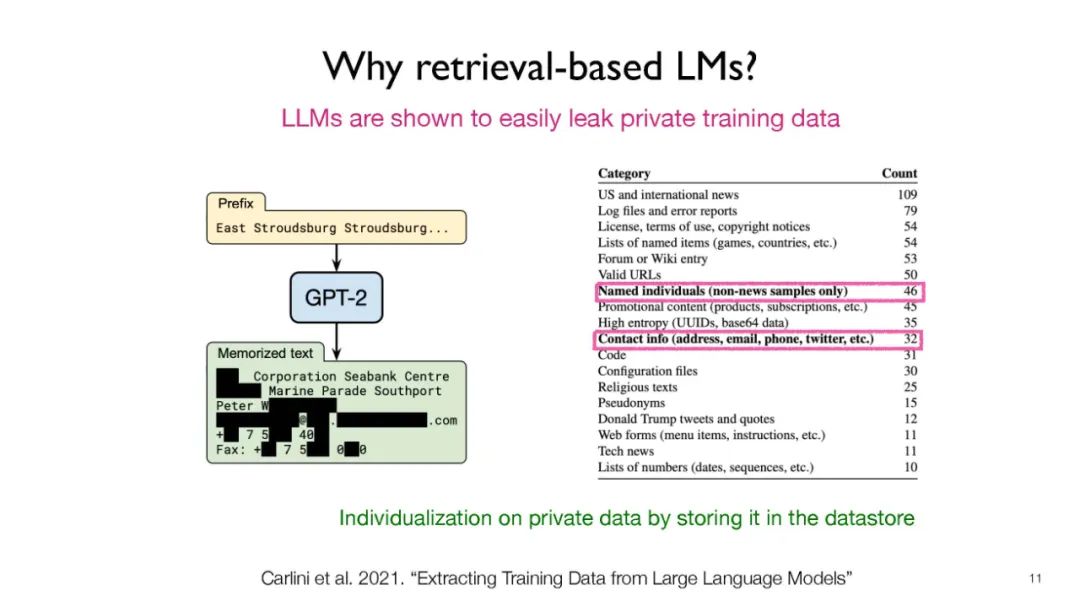
像GPT-3和PaLM这样的语言模型(LMs)在自然语言处理(NLP)任务中表现出了令人印象深刻的能力。然而,仅仅依赖于他们的参数来编码大量的世界知识需要过多的参数,因此需要大量的计算,而且他们经常难以学习长期的知识。此外,这些参数化的LMs在根本上无法随着时间的推移进行适应,常常产生幻觉,并可能从训练语料库中泄露私人数据。为了克服这些限制,人们对基于检索的LMs产生了越来越大的兴趣,这些模型将非参数化的数据存储(例如,来自外部语料库的文本块)与它们的参数化副本结合在一起。基于检索的LMs可以以更少的参数大幅度超越没有检索的LMs,可以通过更换他们的检索语料库来更新他们的知识,并且为用户提供引文以便于轻松验证和评估预测。
在这个教程中,我们的目标是提供关于基于检索的LMs最近进展的全面而连贯的概述。我们将首先提供基础知识,涵盖LMs和检索系统的基础。然后我们将关注基于检索的LMs在架构,学习方法和应用方面的最近进展。

像GPT-3 (Brown等,2020) 和 PaLM (Chowdhery等,2022) 这样的语言模型(LMs)在一系列自然语言处理(NLP)任务中展示出了令人印象深刻的能力。然而,仅依赖它们的参数来编码世界知识需要过于庞大的参数数量,从而导致大量的计算,它们往往在学习长期知识方面存在困难(Roberts等,2020;Kandpal等,2022;Mallen等,2022)。此外,这些参数化的LMs从根本上无法随时间的推移进行适应(De Cao等,2021;Lazaridou等,2021;Kasai等,2022),经常会产生幻觉(Shuster等,2021),并可能从训练语料库中泄漏私人数据(Carlini等,2021)。为了克服这些限制,人们对基于检索的LMs(Guu等,2020;Khandelwal等,2020;Borgeaud等,2022;Zhong等,2022;Izacard等,2022b;Min等,2022)产生了越来越大的兴趣,这些模型将非参数化的数据存储(例如,来自外部语料库的文本块)与他们的参数化版本结合在一起。基于检索的LMs可以以更少的参数大幅度超越没有检索的LMs(Mallen等,2022),可以通过替换检索语料库来更新他们的知识(Izacard等,2022b),并且为用户提供引文以便于轻松验证和评估预测(Menick等,2022;Bohnet等,2022)。过去,检索和LMs大多被分开研究,只是最近研究者们才将他们集成起来,构建了在其中检索和LMs更有机地互动的系统,由于兴趣的增长,已经提出了一些基于检索的LMs。他们在神经架构(例如,检索单元的粒度,如何整合检索到的信息)、学习算法和在下游应用中的不同使用等方面存在差异。在这个教程中,我们的目标是提供关于基于检索的LMs最近进展的全面而连贯的概述。我们将首先提供基础知识,涵盖LMs(例如,掩码LMs,自回归LMs)和检索系统(例如,广泛用于神经检索系统的最近邻搜索方法;Karpukhin等,2020)的基础。然后我们将关注基于检索的LMs在架构,学习方法和应用方面的最近进展。
架构分类
我们根据各种维度介绍了基于检索的LMs的架构分类。基于检索的LMs可以按照在数据存储中存储的检索单元的粒度进行分类:1) 一段文本(Borgeaud等,2022;Izacard等,2022b);2) 一个标记(Khandelwal等,2020;Zhong等,2022;Min等,2022);3) 一个实体提及(Févry等,2020;de Jong等,2022)。我们也计划介绍用于优化数据存储和改进相似性搜索的技术(He等,2021;Alon等,2022)。同时,基于检索的LMs可以根据检索到的信息如何与参数编码器集成来进行分类:1) 是否将检索到的组件与原始输入文本连接起来(Lewis等,2020;Guu等,2020;Izacard等,2022b);2) 是否将检索到的组件作为潜在的组件并集成到Transformers的中间层中(de Jong等,2022;Févry等,2020;Borgeaud等,2022);3) 是否将从检索到的组件和LMs中分布的标记进行插值(Khandelwal等,2020;Zhong等,2022;Yogatama等,2021)。
可扩展的学习算法
接下来,我们讨论基于检索的LMs的训练方法。由于检索数据存储通常非常大,如何有效且高效地训练基于检索的LMs仍然是一个挑战。我们首先讨论分步训练方法,这种方法将检索组件和LMs分开训练,可以通过大规模预训练(Izacard等,2022a)或多任务指令调整(Asai等,2022)来实现。其他一些工作用固定的检索模块训练基于检索的LMs(Borgeaud等,2022;Yogatama等,2021)。然后,我们讨论在合理的资源需求下进行联合训练:可以通过对全数据存储进行批处理近似,或者异步更新具有更新参数的数据存储。前者在联合训练过程中使用精心设计的全文档的一部分(Zhong等,2022;de Jong等,2022;Min等,2022)。另一方面,后者的目标是在训练过程中使用全文档,并每隔一定的时间步长异步更新索引(Izacard等,2022b;Guu等,2020)。
适应下游任务在讨论了基于检索的LMs的基本构建模块后,我们展示了如何将基于检索的LMs应用于下游应用。我们首先简要总结了将模型适应新任务的两种方法:零-shot或少-shot提示(Shi等,2022;Wang等,2022),以及在目标任务数据上进行微调(Lewis等,2020)。然后,我们讨论了设计用于特定下游任务的更强大的基于检索的LMs方法,如对话(Shuster等,2021),语义解析(Pasupat等,2021)和机器翻译(Khandelwal等,2021;Zheng等,2021)。到目前为止,我们的教程主要关注的是检索和整合英文普通文本。在最后,我们将介绍基于检索的LMs在英文文本之外的最新扩展,包括多语言(Asai等,2021),多模态(Chen等,2022;Yasunaga等,2022)和代码(Parvez等,2021)检索。这些工作通常将稠密检索模型扩展到可以在异构输入空间之间进行检索(例如,跨语言,跨模态),并且已经表明引用检索的知识可以产生知识密集型生成。最后,我们将通过一个练习展示基于检索的LMs的有效性。我们通过讨论一些重要问题和未来方向来结束我们的教程,包括(1)如何在不牺牲性能的情况下进一步提高基于检索的LMs的可扩展性,(2)在迅速发展的LMs时代,基于检索的LMs在何时特别有用,以及(3)为了实现基于检索的LMs在更多样化的领域中的应用,我们需要什么。