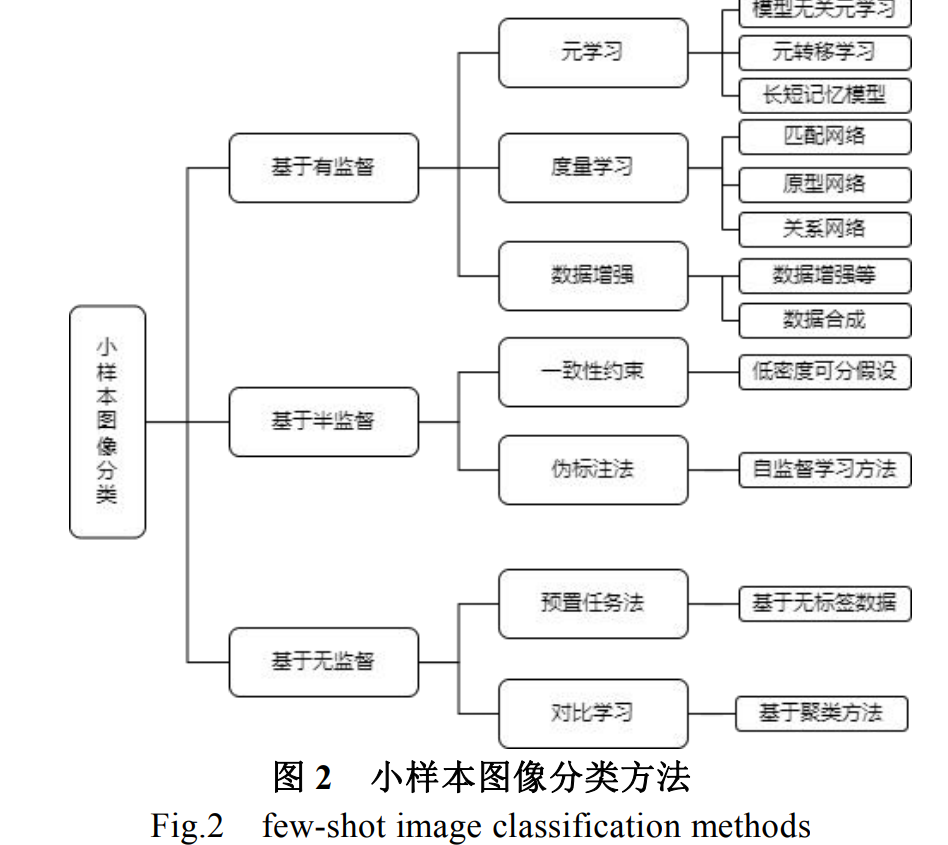
近年来,凭借大规模数据集和庞大的计算资源,使得以深度学习为代表的人工智能算法在诸多领域取得成功。其中计算机视觉领域的图像分类技术蓬勃发展,并涌现出许多成熟的视觉任务分类任务模型。这些模型均需要利用大量的标注样本进行训练,但在实际场景中因诸多限制导致数据量稀少,往往很难获得相应规模的高质量标注样本。因此如何使用少量样本进行学习已经逐渐成为当前的研究热点。小样本学习旨在通过少量样本实现对新类别样本的高效识别与处理。针对分类任务系统梳理了当前小样本图像分类的相关工作,小样本学习主要采用元学习、度量学习和数据增强等深度学习方法。从有监督、半监督和无监督等层次归纳总结了小样本图像分类的研究进展和典型技术模型,以及这些模型方法在若干公共数据集上的表现,并从机制、优势、局限性等方法进行对比分析。最后讨论了当前小样本图像分类面临的技术难点以及未来的发展趋势。大规模标注数据集是深度学习成功的必要条 件之一[1-4]。在现实世界的真实场景中,许多领域并 不具有获得大规模数据集的条件,这对于工作开展 十分不便;也有一些领域,涉及到隐私、成本、道 德等问题也很难获得高质量数据。例如,在医疗诊 断领域,医学图像的来源是病例,而病例会因为隐 私等问题获取难度较大;在半导体芯片缺陷检测领 域,会面临半导体芯片的型号不同和缺陷数据较少 等问题。为了解决诸多领域中数据有限和获取难度较 大的问题,小样本学习(Few-shot Learning,FSL) [5-8]方法被提出。小样本学习是指训练类别样本较少 的情况下,进行相关的学习任务。机器通过学习大 量的基类(Base class)后,仅仅需要少量样本就能快 速学习到新类(New class)。通常情况下,小样本学 习能够利用类别中的少量样本,即一个或者几个样 本进行学习。例如,一个小朋友去动物园并没有见 过‘黄莺’这个动物,但是阅读过有关动物书籍,书 籍上有‘黄莺’的信息,通过学习书上的内容,小朋 友就知道动物园中那个动物是‘黄莺’。这是因为人 们可以高效的利用以往的先验知识,对现在的任务 快速理解。人们这种快速理解新事物的能力,也是 当前深度学习难以具备的。本文针对小样本图像分 类问题介绍小样本学习的相关技术,主要介绍小样 本图像分类,小样本图像分类的最终目的是达到人 类的水平[9]。小样本图像分类问题建模如图 1 所示。在图示 中,将任务划分为两部分,训练集(Training data)也 叫做支持集(Support data),其中分为 N 个数据类别, 每 N 个数据类别包括 K 个样本,简称为 N-way K-shot 问题[10]。测试集(Test data)也叫做查询集 (Query data)。查询集的类别属于支持集中的类别。解决 N-way K-shot 小样本图像分类问题,首先从辅 助的数据集学习先验知识,再在标注有限的目标数 据集上利用已经学习的先验知识进行图像分类和 预测。
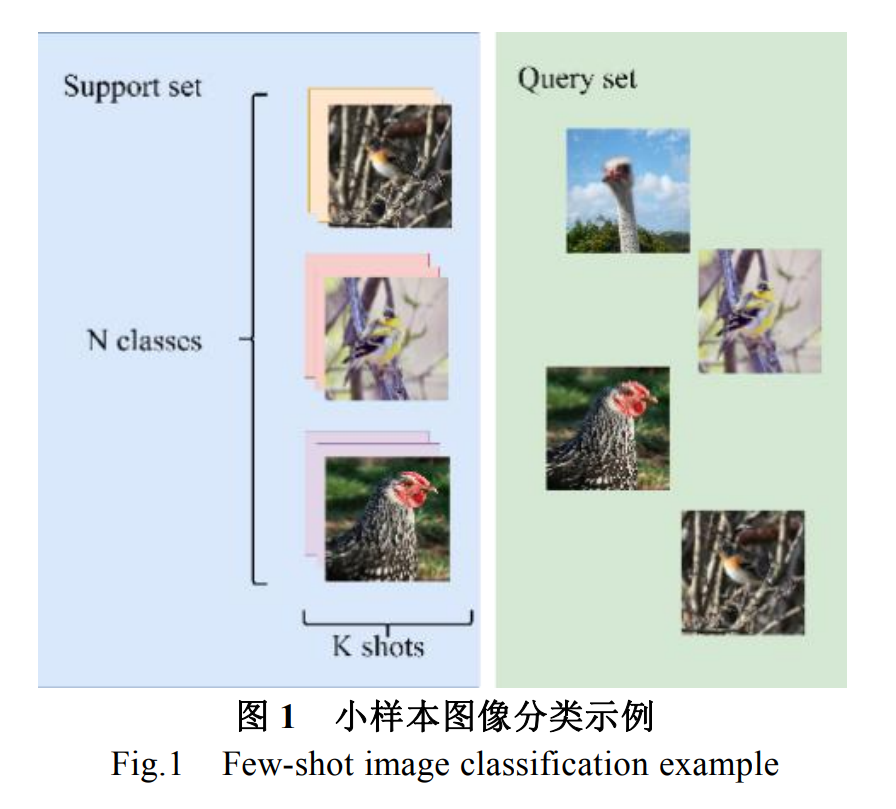
目前已经有一些关于小样本学习各方面的综述,赵凯琳等[11]对小样本学习进行了综述介绍,从基于模型微调、数据增强和迁移学习的三个方向来介绍小样本学习的方法,并且进行了归纳总结;刘春磊等[12]将小样本学习方法归纳为基于迁移学习的范式和基于元学习的范式,再按照改进策略的不同进行小样本目标检测综述介绍;张振伟等[13]从基于度量学习、数据增强、模型结构、元学习等六个方面对小样本目标检测方法进行了总结分析。综合近些年小样本学习发展,元学习、度量学习和数据增强等深度学习方法已经逐渐成为解决小样本图像处理的主流方法。近些年来,随着无监督[14]、半监督学习[15]和主动学习[16]的兴起和发展,很多研究者也将其应用到小样本图像分类问题中。与这些不同综述[11-13]不同,本文首先将这些方法在有监督、半监督和无监督三种范式下,如图2 所示,再按照各种情况的不同方法,从度量学习、元学习、伪标注、对比学习等角度进行归纳总结,对比分析了这些方法的性能表现。并总结了各自的核心思想以及使用领域。文章的第一节介绍小样本图像分类框架及其数据集;第二、三、四节分别介绍在有监督、半监督和无监督情况下的小样本图像分类研究进展,以及在各种监督技术下的小样本图像分类方法总结和对比,第五、第六节对小样本图像分类方法核心思想、适用领域和优缺点进行对比分析,并提 出小样本图像分类的挑战和未来发展方向。