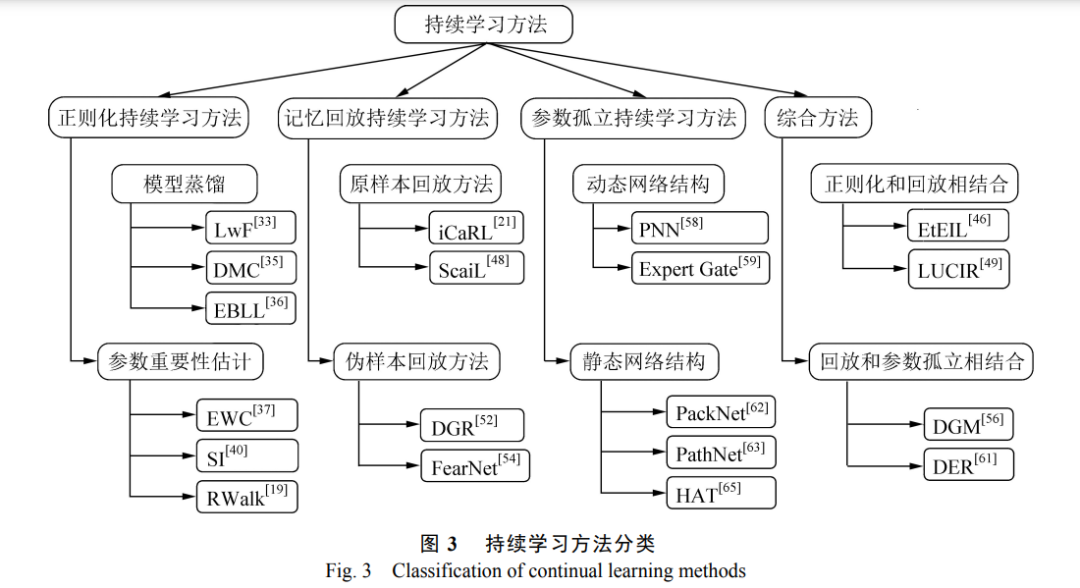
深度学习模型通常限定在固定数据集中进行训练,训练完成之后模型无法随着时间而扩展其行为. 将已训练好的模型在新数据上训练会出现灾难性遗忘现象. 持续学习是一种能够缓解深度学习模型灾难性遗 忘的机器学习方法,它旨在不断扩展模型的适应能力,让模型能够在不同时刻学习不同任务的知识. 目前,持 续学习算法主要分为 4 大方面,分别是正则化方法、记忆回放方法、参数孤立方法和综合方法. 对这 4 大方面 方法的研究进展进行了系统总结与分析,梳理了衡量持续学习算法性能的评估方法,讨论了持续学习的新兴 研究趋势. http://www.yndxxb.ynu.edu.cn/yndxxbzrkxb/article/doi/10.7540/j.ynu.20220312?viewType=HTML 得益于更大的数据集、更强的计算能力以及 网络结构创新,深度学习在图像分类[1]、人脸识别[2] 等任务上已经实现了接近人类甚至超越人类的性 能. 然而大多数神经网络只能在预先知道所有类的 批量学习设定下进行训练直至拟合,当有新数据出 现时,必须使用全部数据重新训练模型,以适应数 据分布变化[3] . 随着移动设备和互联网的飞速发展, 人们每天都会拍摄和分享大量图片和视频. 而从零 开始重新训练模型是耗时且低效的,这就要求模型 拥有以序列方式进行持续学习和更新的能力,以适 应每天新产生的数据. 神经网络从原来的批量学习模式转变为序列 学习模式时,很容易出现对旧知识的遗忘,这意味 着,在使用新数据更新模型后,模型在先前学习的 任务中所达到的性能会急剧下降[4],出现灾难性遗 忘. 早在 30 多年前,人们就在多层感知器中发现了 灾难性遗忘现象[5],产生灾难性遗忘的根本原因是 新任务训练过程需要改变神经网络权值,这不可避 免地修改了某些对于旧任务来说至关重要的权重, 使得模型不再适用于旧任务. 与此相反,人类可以 不断学习和适应新知识,并且在自身积累新知识的 同时,也会对原有知识进行了补充和修正,学习新 知识很少会导致人类灾难性地忘记之前的知识[6] . 如自然视觉系统,先前的知识得到了保留的同时, 新的视觉信息被不断地整合到已有知识中. 为了克服灾难性遗忘,学习系统一方面要在新 任务上表现出获取新知识和提炼现有知识的能力, 另一方面要防止新任务对现有知识的显著干扰. 持 续学习,也称为终身学习,它建立在不断学习外部 世界的想法之上,神经网络通过持续学习算法能够 渐进地学习新知识,并且保留过去学习的内容. 近 年来,如图 1 所示,持续学习在计算机视觉领域获 得了蓬勃发展,同时各单位也如火如荼开展着持续 学习的相关比赛[7] . 鉴于持续学习深刻的应用场景 和该领域飞速的发展,本文对持续学习的研究工作 进行综述,从而帮助读者掌握持续学习研究的最新 趋势.