【重温经典】吴恩达课程学习笔记二:无监督学习(unsupervised learning)
【导读】前一段时间,专知内容组推出了春节充电系列:李宏毅2017机器学习课程学习笔记,反响热烈,由此可见,大家对人工智能、机器学习的系列课程非常感兴趣,近期,专知内容组推出吴恩达老师的机器学习课程笔记系列,重温机器学习经典课程,希望大家会喜欢。
吴恩达机器学习课程系列视频链接:
http://study.163.com/course/courseMain.htm?courseId=1004570029
吴恩达课程学习笔记二:无监督学习(unsupervised learning)
1、无监督学习与监督学习的区别
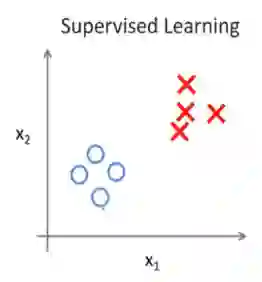
对于监督学习来说,输入算法的数据集中给定了一组特征对应的类别(label)(比如是否是恶性肿瘤)。监督学习又包括回归(regression)和分类(classification)。
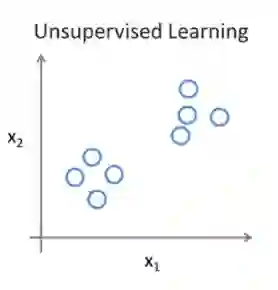
而对于无监督学习,输入的数据集不包含label,我们只知道我们这里有一个数据集,那么可以判定出它的结构吗。如上右图,算法可能会将它分为两类,左下角和右上角两类。这种算法叫聚类算法。
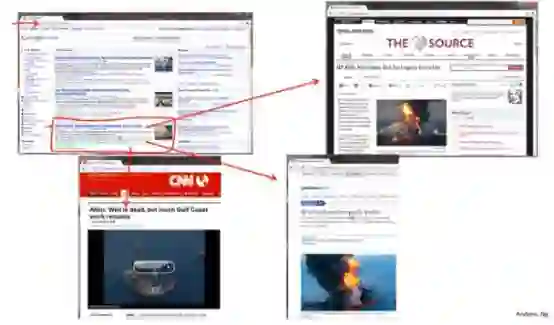
例如谷歌新闻,它每天去搜集成千上万的新闻,然后聚类出某一类的新闻显示在一起(例如下图就是把,不同的报纸对某起石油泄露事件的报道的链接整合到一起)
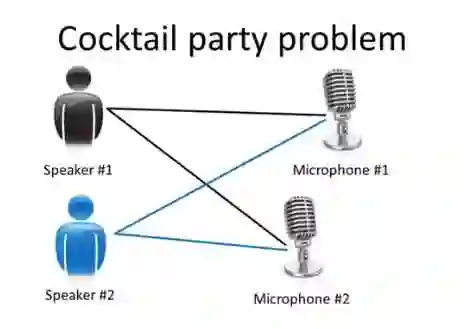
2、一种典型的无监督问题(鸡尾酒会的问题)
假设一个鸡尾酒会只有两个人,同时说话,房间里放置了两个麦克风,麦克风与人的相对位置不同,(或许第一个人的声音在麦克风1里要响一点,第二个人在麦克风2里要响一点)如下图:
现在麦克风里记录了两个人用不同的语言从一数到十的声音,现在将这个混合的音频信息交给无监督学习进行处理,从而找出数据的结构。
“鸡尾酒会”算法可能会得出结果:这可能是两种不同的声音混在了一起,并将两种声音分开。事实上,想要分离出两种声音,用Octave一行代码就可以完成对语音的分离工作(这里的Octave代码虽然只有一行但是这却用了很大的精力,这里算是通识介绍,如果是小白读者大可以不用太过在意):

3、无监督学习两种常见用例
无监督学习常用在探索性分析和降维:
无监督学习在探索性分析中非常有用,因为它可以自动识别数据结构。例如,如果分析师试图对消费者进行细分,那么无监督聚类方法将成为他们分析的一个很好的起点。在人们提出数据趋势是不可能或不切实际的情况下,无监督学习可以提供初始见解,然后用于检验个人的假设。
降维指的是使用较少的列或特征来表示数据的方法,可以通过无监督的方法来实现。在表示学习中,我们希望了解各个特征之间的关系,使我们能够使用与我们初始特征相互关联的潜在特征来表示我们的数据。这种稀疏的潜在结构通常比我们开始使用的功能要少得多,因此它可以使进一步的数据处理变得更加密集,并且可以消除冗余功能
4、a small quiz
对于下图给定的题目,哪些需要使用无监督的算法

选项一:给定一个有是否是垃圾邮件label的数据集,训练一个垃圾邮件分类箱
选项二:给定一组从网上搜集的文章,将同一类的文章分类在一起
选项三:给定顾客的信息,将顾客分成不同购买类型的类别
选项四:给定一批被label了是否患糖尿病的病人信息的数据集,训练数据集从而去预测一个新的病人是否患有糖尿病。
答案:选项二和选项三
后面的笔记中会讲到更多的算法,以及这些算法是如何工作的。期待与你重温经典,一起学习!
参考链接:
http://study.163.com/course/courseMain.htm?courseId=1004570029
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!



