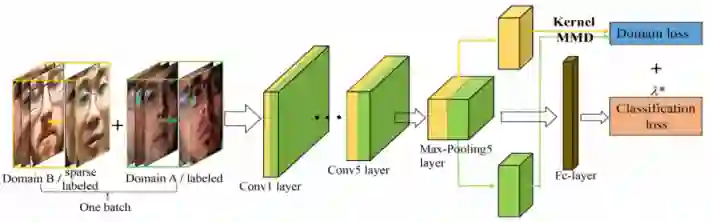
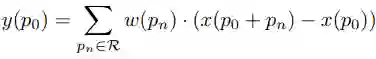如上图所示,其中每个 batch 包含一半源图像和一半目标图像,最后一个池层输出的两个域的特征用于计算分布距离,计算使用 kernel based MMD,最后的损失函数是分类损失和 domain 损失组成组成。
Meta learning
当遇到新的应用场景,面对中训练样本分布外的攻击类型时,数据驱动的模型往往会产生不可预测的结果。如果要调整活体检测模型以适应新的攻击,就需要收集足够的样本进行训练,然而收集有标签的数据的成本是昂贵的。因此,对于 anti spoofing 这类问题,data-driven 这条路很被动,而且很难看到头。
论文标题:Regularized Fine-grained Meta Face Anti-spoofing
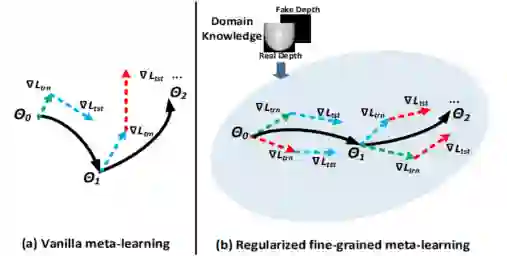
如果我们将现有的元学习算法直接应用于人脸反欺骗任务,会由于以下两个问题而降低性能: 1. 人脸反欺骗模型仅具有二进制类监督,会出现泛化效果差。如下图(a)所示,如果仅在二元类别标签的监督下,将常见的元学习算法应用于面部反欺骗,则 meta train 和 meta test 的学习方向将是有偏见的,这使得 meta learning 难以训练并最终找到广义的学习方向。
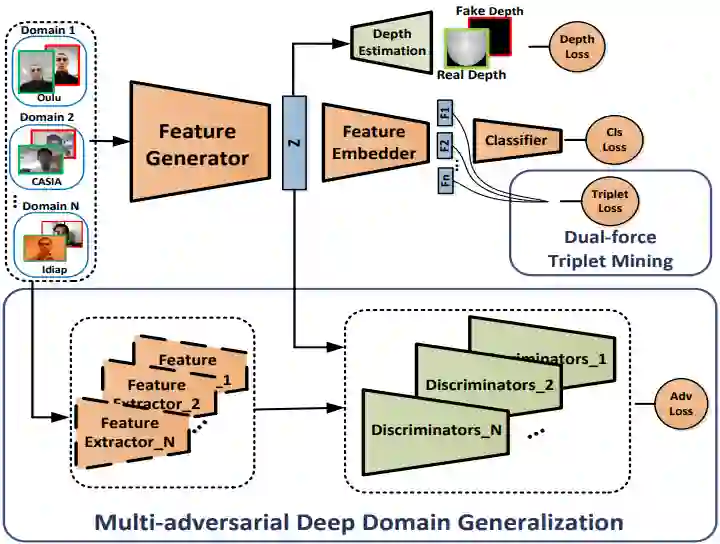
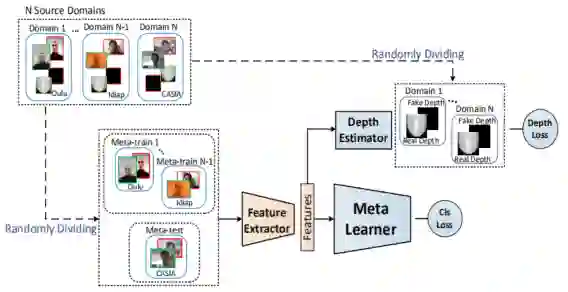
2. 对于 domain generalization 方法的 meta learning,其在每次元学习迭代中将多个源域粗略地划分为两组 meta train 和 meta test。因此,在每次迭代中仅模拟了单个 domain shift,这对于人脸反欺骗任务是效果较差的。 为了解决上述两个问题,如下图所示,本文提出了一种新颖的正则化细粒度元学习框架。 对于第一个问题,与二元类别标签相比,特定于面部反欺骗任务的领域知识可以提供更通用的区分信息。因此,将人脸反欺骗领域知识作为正则化方法纳入特征学习过程中,这样,这种正则化元学习可以针对脸部反欺骗任务,在元训练和元测试中专注于更协调,更通用的学习方向。 对于第二个问题,提出的框架采用了如上图(b)所示的细粒度学习策略。该策略将源域划分为多个元训练域和元测试域,并在每次迭代中在它们之间的每对之间共同进行元学习。这样,可以同时模拟多 domain shift,因此可以在元学习中利用更丰富的域移位信息来训练广义的面部反欺骗模型。
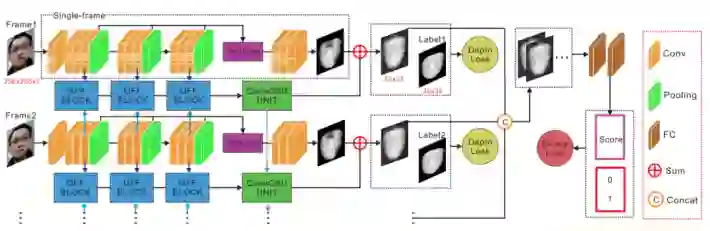
这篇文章的网络由特征抽取器、元学习器和深度估计器组成。在 Meta-Train 过程中,我们从 N 个训练集中随机选择 N-1 个,使用 binary loss 进行训练,使用了深度监督加强对模型的监督。剩余的一个训练集用于 Meta-Test,Meta-Optimization 过程就是对上述 meta-train and meta-test 中的 model 进行更新。
论文标题:Learning Meta Model for Zero-Shot and Few-shot Face Anti-spoofing
论文来源:AAAI 2020
论文链接:https://arxiv.org/abs/1904.12490
这篇文章将 FAS 做为一个 Zero-shot 和 Few-shot 的学习问题。本文的主要贡献有: 1. 首先将 FAS 定义为一个 zero- and few-shot 的问题。 2. 为了解决 zero- and few-shot FAS 问题,提出一种新的基于元学习的方法:自适应内更新元面孔反欺骗(AIM-FAS) 3. 我们提出了三个新颖的 zero- and few-shot FAS 基准点,以验证 AIM-FAS 的有效性。 4. 进行了全面的实验,以表明 AIM-FAS 在零和几乎没有反欺骗基准。 Zero-shot learning 旨在学习一般的区别特征,这些特征对可以从已知的假脸中检测未知的新假脸。Few-shot learning 旨在快速适应反欺骗模式,通过学习预先定义的假脸和收集到的少量新攻击的样本。 具体来说,在 zero- or few-shot FAS 任务,meta-learner 的一次训练迭代包括两个阶段。元学习者使用 supper set 更新其权重,然后在 query set 上测试更新后的元学习者,得到元学习者的学习成绩和损失。最后,我们用元学习优化元学习者损失。
NAS
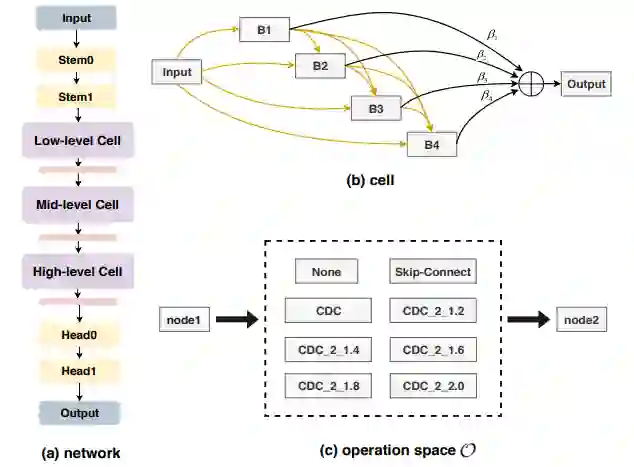
论文标题:Searching Central Difference Convolutional Networks for Face Anti-Spoofifing