作者:Donghwee Yoon等
机器之心编译
编辑:蛋酱、张倩
在这篇论文中,研究者提出了 OUR-GAN,这是首个单样本(one-shot)超高分辨率(UHR)图像合成框架,能够从单个训练图像生成具有 4K 甚至更高分辨率的非重复图像。
![]()
论文链接:https://arxiv.org/pdf/2202.13799.pdf
传统生成模型通常从相对较小的图像数据集中,基于 patch 分布学习生成大型图像,这种方法很难生成视觉上连贯的图像。OUR-GAN 以低分辨率生成视觉上连贯的图像,然后通过超分辨率逐渐提升分辨率。由于 OUR-GAN 从真实的 UHR 图像中学习,它可以合成具有精细细节的大规模形状,同时保持远距离连贯性。
OUR-GAN 应用无缝衔接的子区域超分辨率,在内存受限的条件下合成 4K 或更高分辨率的 UHR 图像,并解决了边界不连续的问题。此外,OUR-GAN 通过向特征图添加垂直位置嵌入来提高多样性和视觉连贯性。在 ST4K 和 RAISE 数据集上的实验结果表明:与现有方法相比,OUR-GAN 表现出更高的保真度、视觉连贯性和多样性。
我们来看一下 OUR-GAN 的合成效果,下图(上)是 OUR-GAN 训练使用的单个 4K 图像,(下)是 OUR-GAN 合成的 16K (16384 x 10912) 图像。
![]()
![]()
以下几组是 OUR-GAN 合成的 4K 风景图:
![]()
OUR-GAN 成功合成了具有多种图案的高质量纹理图像:
![]()
OUR-GAN 通过三个步骤合成占用有限 GPU 内存的 UHR 图像,如下图 3 所示。首先,OURGAN 生成低分辨率的全局结构。然后通过 in-memory 超分辨率在内存限制内尽可能提高分辨率。最后,OURGAN 通过逐个子区域应用超分辨率来进一步提高超出内存限制的分辨率来合成 UHR 图像。
![]()
超分辨率模型的输出分辨率受限于训练图像的分辨率。然而,ZSSR 和 MZSR 已经证明,通过利用信息的内部循环,超分辨率模型可以生成比训练图像大 2 到 4 倍的图像。
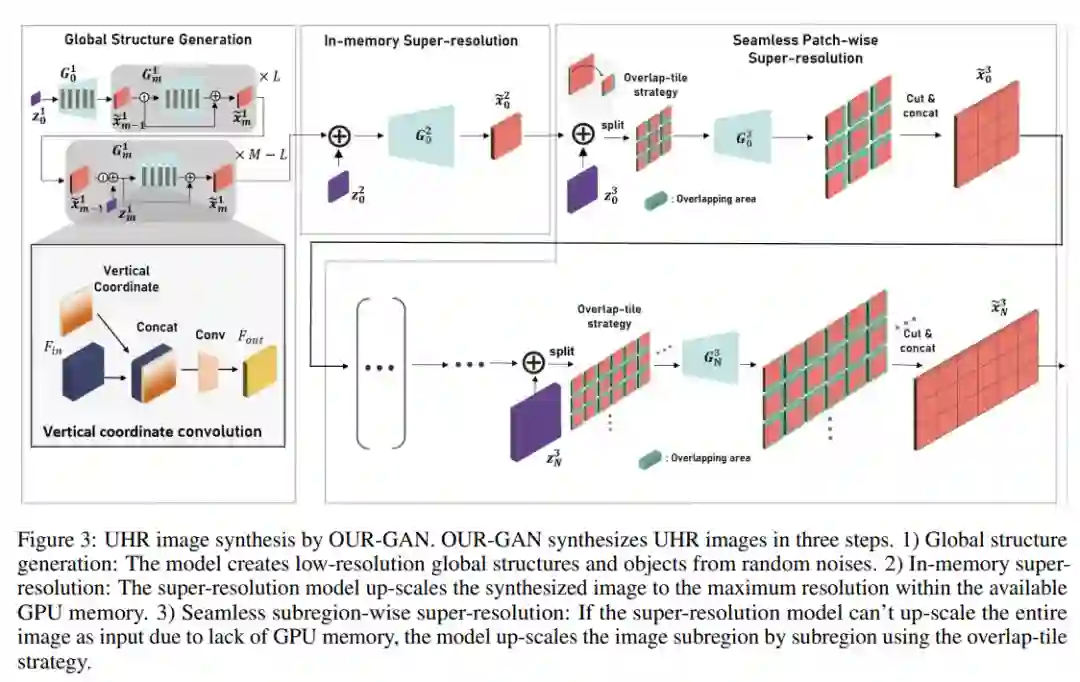
从单个训练图像中学习合成具有全局连贯形状的不同图像,是一项具有挑战性的任务。该研究的初步实验比较了可以用单个图像训练的多个模型。其中,HP-VAE-GAN 表现出比其他模型更高的多样性,但全局一致性不足。因此,该研究选择 HP-VAE-GAN 作为第一步的基线模型,并通过应用垂直坐标卷积来提高全局一致性。HP-VAE-GAN 通过基于分层 patch 的生成方案合成图像,如方程式 (1)-(3),其中
![]() 、
、
![]() 和
和
![]() 分
别表示在尺度 m 下的生成器、合成图像和高斯噪声向量。
符号↑代表上采样。
分
别表示在尺度 m 下的生成器、合成图像和高斯噪声向量。
符号↑代表上采样。
![]()
首先,如等式 (1) 所示,HP-VAE-GAN 从高斯噪声
![]() 生
成初始图像,然后如等式 (2)(3) 所示,逐渐增加分辨率。
在 1 ≤ m ≤ L 的早期阶段,为了多样性,HP-VAE-GAN 应用 patch VAE [19],如方程式 (2),因为 GAN 模型的多样性由于模式崩溃问题而受到限制。
然而,在 L < m ≤ M 的后期阶段,为了细节的保真,它应用了 patch GAN [22],如等式 (3)。
在第二步和第三步中,OUR-GAN 专注于保真度,并通过添加精细细节来提高先前合成图像的分辨率。在第三步中,OUR-GAN 应用子区域超分辨率以将图像分辨率提高到超出内存限制。这些步骤中最大的技术挑战是使用单个训练图像学习超分辨率模型。该研究通过预训练 ESRGAN(一种以良好的输出质量而闻名的超分辨率模型)来实现高保真度,然后使用单个训练图像对其进行微调。在之前的工作中,有超分辨率模型,例如 ZSSR 和 MZSR [21],可以从单个图像中学习。然而,在初步实验中,预训练 ESRGAN 表现出比零样本超分辨率模块更高的图像质量。该研究使用 DIV2K 和 Flickr2K 数据集来预训练 ESRGAN。
在第二步中,研究者在先前合成的图像
生
成初始图像,然后如等式 (2)(3) 所示,逐渐增加分辨率。
在 1 ≤ m ≤ L 的早期阶段,为了多样性,HP-VAE-GAN 应用 patch VAE [19],如方程式 (2),因为 GAN 模型的多样性由于模式崩溃问题而受到限制。
然而,在 L < m ≤ M 的后期阶段,为了细节的保真,它应用了 patch GAN [22],如等式 (3)。
在第二步和第三步中,OUR-GAN 专注于保真度,并通过添加精细细节来提高先前合成图像的分辨率。在第三步中,OUR-GAN 应用子区域超分辨率以将图像分辨率提高到超出内存限制。这些步骤中最大的技术挑战是使用单个训练图像学习超分辨率模型。该研究通过预训练 ESRGAN(一种以良好的输出质量而闻名的超分辨率模型)来实现高保真度,然后使用单个训练图像对其进行微调。在之前的工作中,有超分辨率模型,例如 ZSSR 和 MZSR [21],可以从单个图像中学习。然而,在初步实验中,预训练 ESRGAN 表现出比零样本超分辨率模块更高的图像质量。该研究使用 DIV2K 和 Flickr2K 数据集来预训练 ESRGAN。
在第二步中,研究者在先前合成的图像
![]() 中加入随机噪声
中加入随机噪声
![]() ,然后通过
,然后通过
![]() 中的超分辨率模型
中的超分辨率模型
![]() 提
高分辨率。
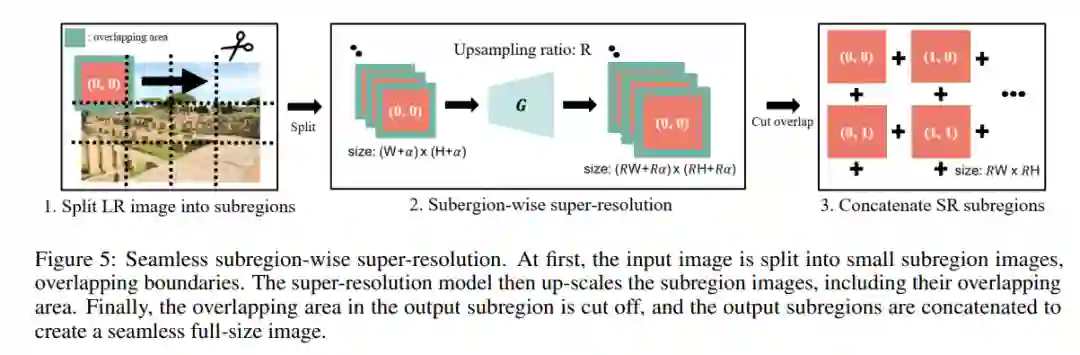
在第三步中,他们将图像划分为子区域,对每个子区域图像进行超分辨率处理,然后将缩放后的子区域图像拼接成一幅更高分辨率的图像,如图 5 所示。
这样的分区超分辨率可以重复多次,以产生 4K 或更高分辨率的 UHR 图像。
提
高分辨率。
在第三步中,他们将图像划分为子区域,对每个子区域图像进行超分辨率处理,然后将缩放后的子区域图像拼接成一幅更高分辨率的图像,如图 5 所示。
这样的分区超分辨率可以重复多次,以产生 4K 或更高分辨率的 UHR 图像。
![]()
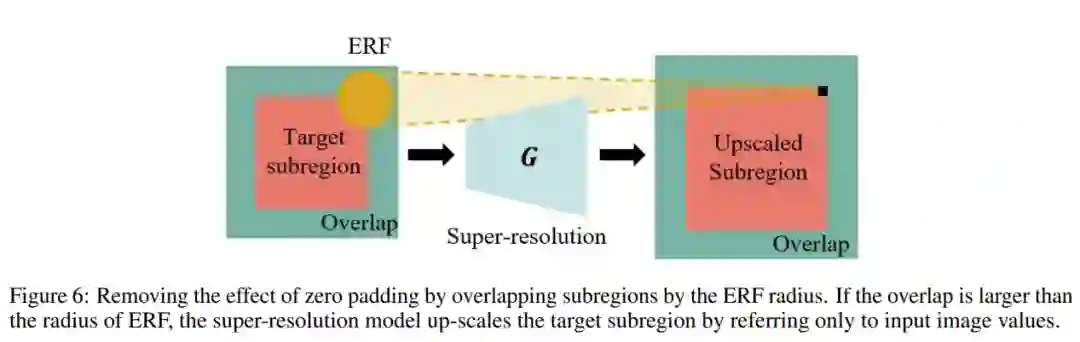
然而,如果没有精心设计,这种分区域的超分辨率会在边界处表现出不连续。在以前的工作中,有一些方法可以防止不连续性。以前的工作表明,不连续性的主要原因是输入特征图周围的零填充(zero-padding),并提出了一些补救措施。[28] 应用了重叠平铺(overlap-tile)策略,扩展输入子区域以阻止边界处零填充的影响。[12] 通过仔细设计具有交替卷积和转置卷积的网络来消除零填充。
由于后者需要重新设计网络,因此研究者对前者进行了改进。受 Wenjie Luo 等人 (2016) 的启发,研究者将重叠大小设置为 ERF 的半径,如图 6 所示,它明显小于 TRF。图 7 中的实验结果表明,等于 ERF 半径的重叠足以防止不连续性。ERF 的渐近逼近是 O (√depth), 而 TRF 的渐近逼近是 O (depth),这表明方法的好处是不可忽略的。
![]()
![]()
研究者比较了没有重叠和 ERF 半径重叠的子区域超分辨率的结果。图 7 显示了子区域超分辨率输出图像与将图像整体放大的普通超分辨率输出图像之间的差异。图 7 (a) 表明,在没有重叠的情况下,子区域超分辨率在子区域边界处产生显着差异。然而,重叠的子区域减弱了这种差异。
下图 8 展示了 OUR-GAN 生成的 4K 样本、基线模型以及 ground truth 图像。
![]()
图 8. OUR-GAN 生成的 4K 样本、基线模型生成的样本,以及 ground truth 图像。
InGAN 未能合成包含大量形状的可视化超高分辨率图像,因为它是通过重复从小样本训练中学到的小规模模式来合成图像。SinGAN 可以生成大规模的模式,但是未能捕捉到结构细节。然而,OUR-GAN 成功地合成了具有视觉连贯形状和精细细节的高质量图像。与其他模型相比,OUR-GAN 合成了最具视觉冲击力的图像。
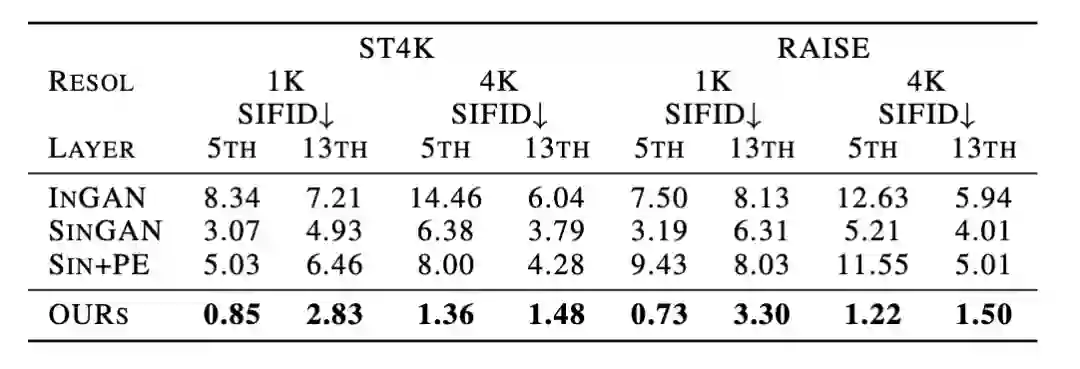
如下表 1 所示,OUR-GAN 在定量研究中的表现也优于其他模型,它在所有配置中得分最高,这表明 OUR-GAN 综合了全局形状和局部细节的高质量图像。
为了评估垂直坐标卷积的效果,研究者用其他模型替换了 OUR-GAN 的 first step 模型,并比较了合成图像的差异: SinGAN,ConSinGAN,HP-VAE-GAN,SIV-GAN。
![]()
图 9 展示了生成的图像。ConSinGAN 和 SIV-GAN 生成的模式多样性有限,而 HPVAE-GAN 合成的扭曲结构结合了不相关的模式。如图 10 所示,与 HP-VAE-GAN 相比,OUR-GAN 显著提高了模式的全局一致性,并且与 ConSinGAN 和 SIV-GAN 相比产生了更多样化的模式。
![]()
图 10: 采用垂直坐标卷积的效果。OUR-GAN 通过垂直坐标卷积的空间偏差来提高视觉连贯性。
![]()
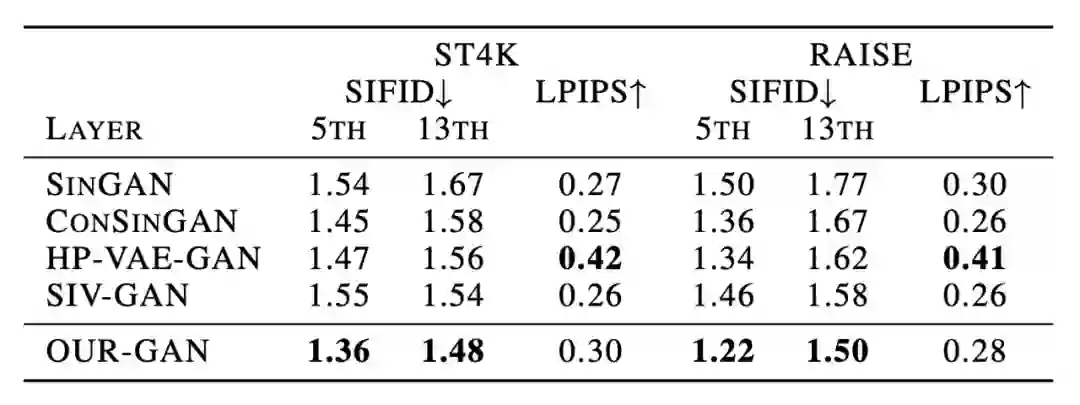
表 2 列出了定量评价的结果,OUR-GAN 在定量结果方面表现良好。OUR-GAN 的 SIFID 分数最低,这表明 OUR-GAN 在学习训练图像的内部统计数据方面是有效的。与 LPIPS 的其他基线相比,OUR-GAN 没有表现出显著差异。然而,高 LPIPS 并不总是表明模型产生高质量的图像,因为它不惩罚视觉上不协调的模式(附录 H 展示了高 LPIPS 视觉不协调的样本)。尽管与 HP-VAE-GAN 相比,OUR-GAN 缺乏多样性,但 OUR-GAN 可以合成视觉上更为连贯的图像。
![]()
该研究还评估了 OUR-GAN 合成高保真 UHR 纹理图像的性能。OUR-GAN 从 ST4K 纹理图像和合成 UHR 图像中学习,图 11 中展示了两个合成样本。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com





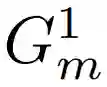 、
、
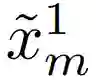 和
和
 分
别表示在尺度 m 下的生成器、合成图像和高斯噪声向量。
符号↑代表上采样。
分
别表示在尺度 m 下的生成器、合成图像和高斯噪声向量。
符号↑代表上采样。
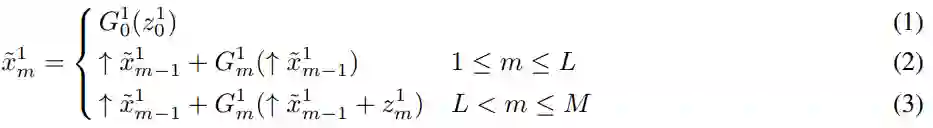
 生
成初始图像,然后如等式 (2)(3) 所示,逐渐增加分辨率。
在 1 ≤ m ≤ L 的早期阶段,为了多样性,HP-VAE-GAN 应用 patch VAE [19],如方程式 (2),因为 GAN 模型的多样性由于模式崩溃问题而受到限制。
然而,在 L < m ≤ M 的后期阶段,为了细节的保真,它应用了 patch GAN [22],如等式 (3)。
生
成初始图像,然后如等式 (2)(3) 所示,逐渐增加分辨率。
在 1 ≤ m ≤ L 的早期阶段,为了多样性,HP-VAE-GAN 应用 patch VAE [19],如方程式 (2),因为 GAN 模型的多样性由于模式崩溃问题而受到限制。
然而,在 L < m ≤ M 的后期阶段,为了细节的保真,它应用了 patch GAN [22],如等式 (3)。
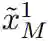 中加入随机噪声
中加入随机噪声
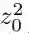 ,然后通过
,然后通过
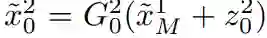 中的超分辨率模型
中的超分辨率模型
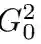 提
高分辨率。
在第三步中,他们将图像划分为子区域,对每个子区域图像进行超分辨率处理,然后将缩放后的子区域图像拼接成一幅更高分辨率的图像,如图 5 所示。
这样的分区超分辨率可以重复多次,以产生 4K 或更高分辨率的 UHR 图像。
提
高分辨率。
在第三步中,他们将图像划分为子区域,对每个子区域图像进行超分辨率处理,然后将缩放后的子区域图像拼接成一幅更高分辨率的图像,如图 5 所示。
这样的分区超分辨率可以重复多次,以产生 4K 或更高分辨率的 UHR 图像。