[ICCV 2021] 联合视觉语义推理:文本识别的多级解码器

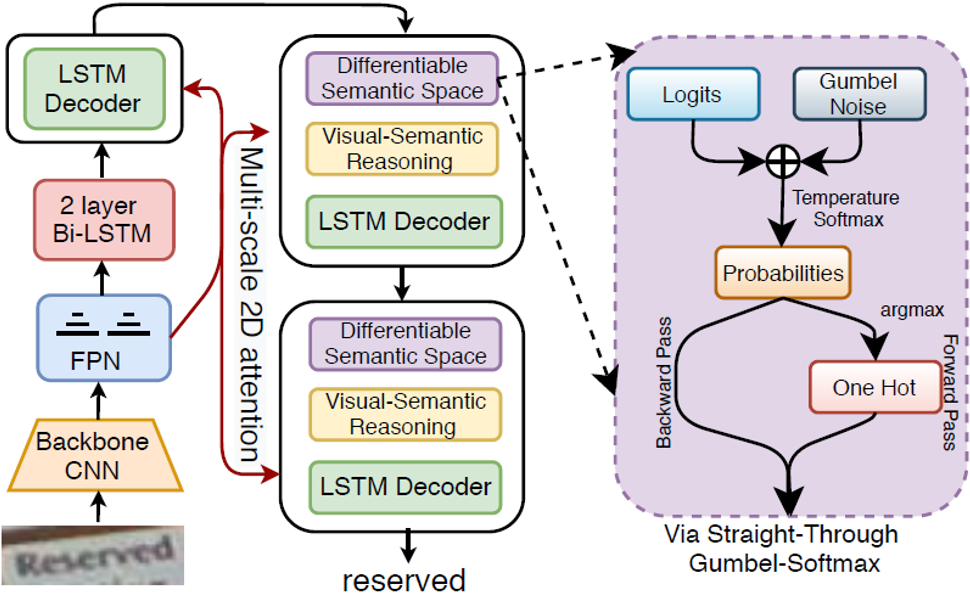
图1 本文方法流程示意图
一、研究背景
在野外场景中,文字图像可能会模糊、扭曲或部分失真,噪声或有伪影,这使得仅使用视觉特征识别非常困难。在这种情况下,我们人类会首先尝试仅使用视觉线索来解释易于识别的字符。然后,联合处理先前已经识别的字符序列的视觉和语义信息,应用语义推理技巧对最终的文本进行解码。
二、方法原理
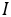 ,我们打算预测字符序列
,我们打算预测字符序列
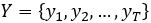 ,其中
T
表示文本的可变长度。我们的框架有两个方面:(
i
)视觉特征提取器提取上下文丰富的整体特征和多尺度特征图。(
ii
)随后,多阶段注意力解码器以阶段连续方式建立字符序列估计。
,其中
T
表示文本的可变长度。我们的框架有两个方面:(
i
)视觉特征提取器提取上下文丰富的整体特征和多尺度特征图。(
ii
)随后,多阶段注意力解码器以阶段连续方式建立字符序列估计。
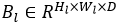 ,其中
,其中
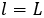 表示分辨率最低但语义级别最高的最深残差块。
表示分辨率最低但语义级别最高的最深残差块。
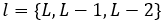 。视觉特征由两个组成部分:(i)多尺度特征图
。视觉特征由两个组成部分:(i)多尺度特征图
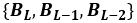 ,它在后面的解码过程中充当2D注意力图的上下文。(ii)整体特征
,它在后面的解码过程中充当2D注意力图的上下文。(ii)整体特征
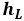 ,用于初始化第一级解码器的初始状态。
,用于初始化第一级解码器的初始状态。
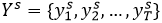 。
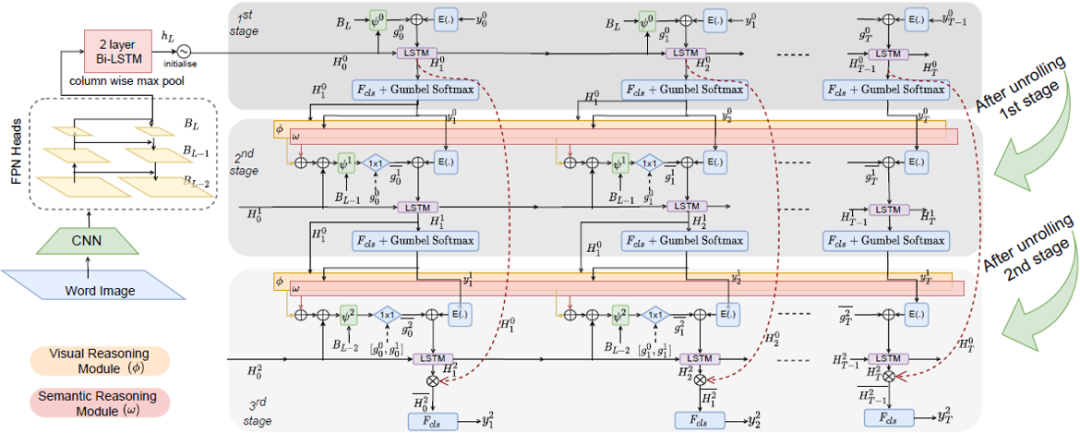
具体地说,第一级解码器仅依赖于提取的视觉特征。
后续阶段还使用了建立在初始预测之上的全局语义信息,采用了阶段解码范式。
。
具体地说,第一级解码器仅依赖于提取的视觉特征。
后续阶段还使用了建立在初始预测之上的全局语义信息,采用了阶段解码范式。
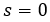
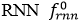 ,初始隐藏状态由整体视觉特征初始化:
,初始隐藏状态由整体视觉特征初始化:
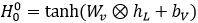 。同时
。同时
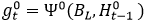 使用局部字符特定信息进行扩充。在每
t-th
时间步,我们得到输出字符的分布如下
使用局部字符特定信息进行扩充。在每
t-th
时间步,我们得到输出字符的分布如下
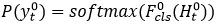 和
和
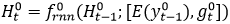 。一旦预测到“
End-token
”,解码过程停止。
。一旦预测到“
End-token
”,解码过程停止。
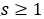 可以被建模为如下公式:
可以被建模为如下公式:
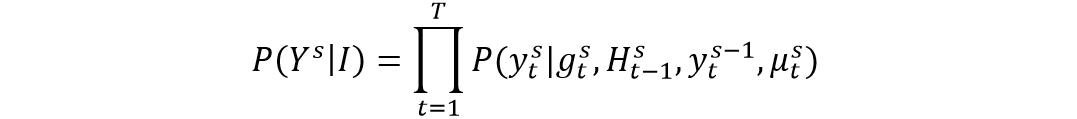
 上的分布中获取离散字符标记需要不可微的Argmax操作。由于我们的动机在于端到端可训练的框架中耦合多级解码器,因此我们采用Gumbel Softmax重新参数化技巧[5]和直通(ST)梯度估计器,以便梯度可以跨级反向传播。这使模型能够学习基于推理的细化策略,而不是之前的预测。
上的分布中获取离散字符标记需要不可微的Argmax操作。由于我们的动机在于端到端可训练的框架中耦合多级解码器,因此我们采用Gumbel Softmax重新参数化技巧[5]和直通(ST)梯度估计器,以便梯度可以跨级反向传播。这使模型能够学习基于推理的细化策略,而不是之前的预测。
我们掩码(也会有目的地用错误的实例替换)某些输入时间步长,并通过线性层强制预测掩码令牌。这有助于模型提前使用纯文本数据了解更好的细化潜力。
三、主要实验结果

 )
)
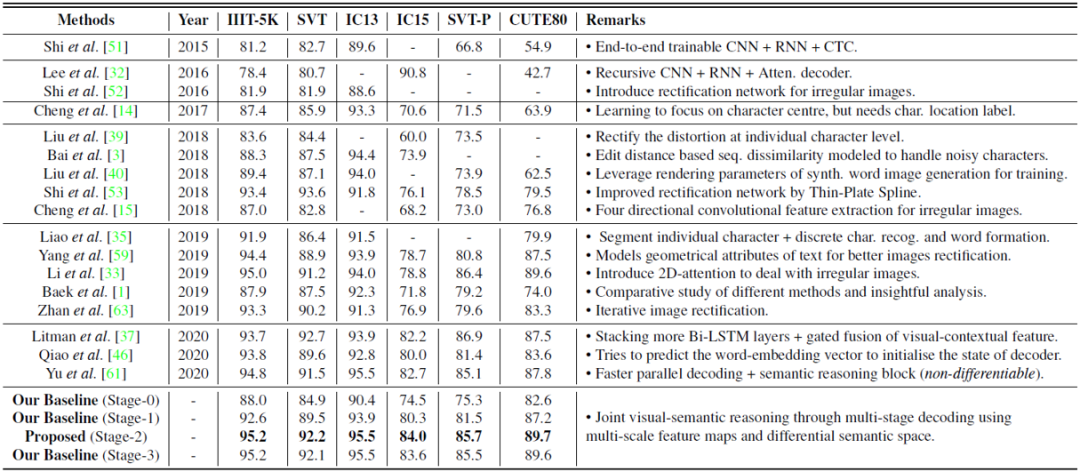
表1 所提出方法与不同最新方法的比较
 :仅最后阶段,
:仅最后阶段,
 :多阶段,
GAP
:与最终性能相比的
WRA
差距。)
:多阶段,
GAP
:与最终性能相比的
WRA
差距。)
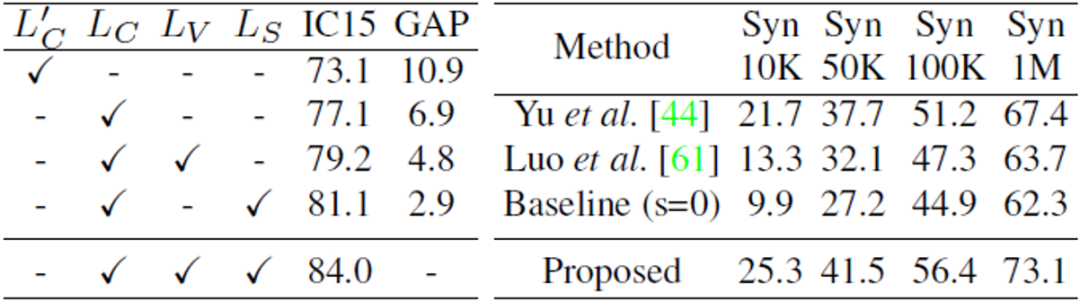
表3 联合视觉语义推理模块的意义以及与语言模型(LM)的比较

表4 对所提出的方法进行了计算分析

四、总结与讨论
此外,本文还引入了多尺度2D注意力以及不同阶段之间的密集和残差连接,以处理不同尺度的字符大小,从而在训练期间获得更好的性能和更快的收敛速度。实验结果表明,本文的方法比现有的SOTA方法有相当大的优势。
五、相关资源
https://openaccess.thecvf.com/content/ICCV2021/papers/Bhunia_Joint_Visual_Semantic_Reasoning_Multi-Stage_Decoder_for_Text_Recognition_ICCV_2021_paper.pdf
参考文献
原文作者: Ayan Kumar Bhunia, Aneeshan Sain, Amandeep Kumar*, Shuvozit Ghose*, Pinaki Nath Chowdhury, Yi-Zhe Song
撰稿:张晓怡
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MSDT” 就可以获取《[ICCV 2021] 联合视觉语义推理:文本识别的多级解码器》专知下载链接




