
Transformer的最新进展伴随着对计算资源的巨大需求,突出了开发高效训练技术的重要性,通过有效使用计算和存储资源,使Transformer训练更快、成本更低、准确度更高。

本综述首次系统地概述了transformer的高效训练,涵盖了加速算法和硬件方面的最新进展,重点是前者。我们分析和比较了在训练期间节省中间张量计算和存储成本的方法,以及硬件/算法协同设计的技术。最后讨论了面临的挑战和未来的研究方向。
https://www.zhuanzhi.ai/paper/3b027298fe1e5d2a83a18e2e19e245ed **深度学习,又称深度神经网络(DNN)是机器学习的一种变革性方法。它彻底改变了机器学习和人工智能,被公认为引领第四次产业革命的技术。**总的来说,深度学习的巨大成功归功于它有效地利用了现有的大量计算资源和大量标记数据。尽管最近的发展带来了巨大的兴奋,但深度学习模型,特别是transformer,已经变得异常庞大和计算密集型,导致了两个基本挑战。
**第一个问题涉及训练基于transformer的大型模型的密集计算。**一项广泛讨论的深度学习模型能耗研究[74]估计,训练一个大型语言模型(LLM)会产生626,155磅的温室气体,相当于五辆汽车的寿命排放量;随着型号越来越大,它们对计算的需求超过了硬件效率的提高。例如,超级巨星GPT-3[9]在5000亿个单词上进行训练,并膨胀到1750亿个参数。值得注意的是,根据GPT-32的技术概述,单次训练运行将需要355 gpu年,成本至少为460万美元,V100理论上估计为28 TFLOPS,最低的3年保留云定价。因此,让深度学习在计算中站得住,以及与之相关的能耗对于绿色人工智能显得尤为重要。
第二个问题是与基于注意力的模型大小成正比的指数式增长的训练存储。例如,文献中最大的语言模型从2018年的BERTlarge[43]的3.45亿增长到目前的数千亿,如配备530B参数的MT-NLG[71]模型。因此,这些SOTA海量模型需要存储高效的训练技术,以减少存储中间张量和跨加速器数据交换(通信)的存储占用,同时确保高处理元素(PE)利用率。**本综述回顾了提高训练基于注意力模型的计算和存储效率的通用技术,即transformer,如图1所示。**通过技术创新和主要用例来描述它们,总结它们并得出它们之间的联系。主要对提高transformer训练效率的算法创新感兴趣,还简要讨论了硬件/算法协同设计的进展。我们把对硬件加速器设计的回顾作为未来的工作。
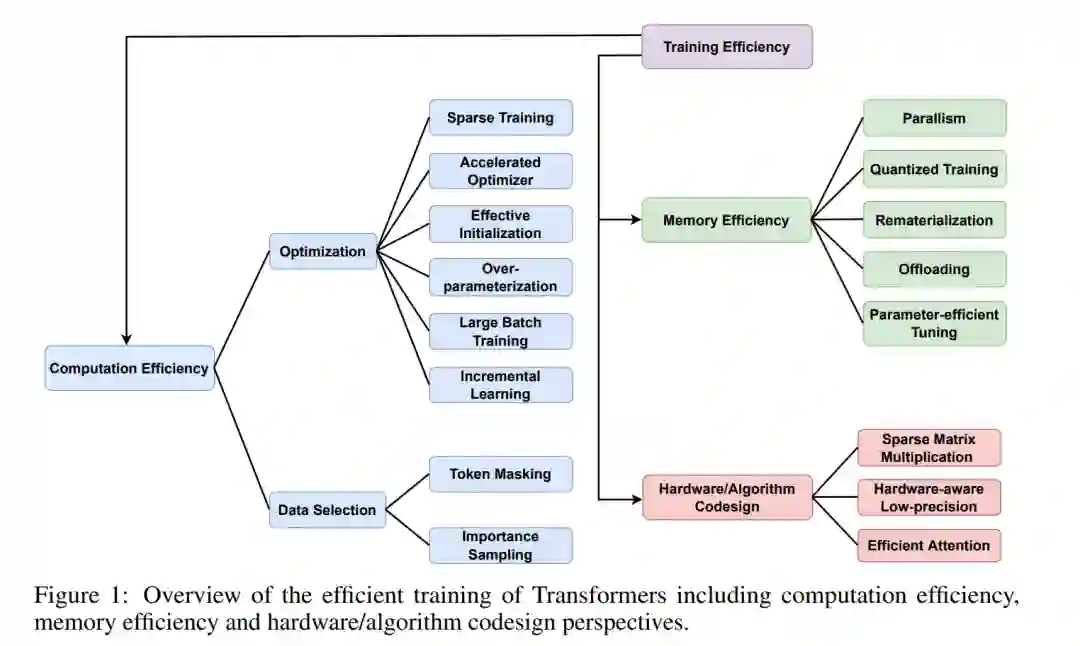
2 计算效率
为了实现更快的梯度下降收敛速度,一个经典的解决方案是融合动量技术,其中每一步都是最陡的下降方向和最近迭代位移的组合,有助于加速相关方向的梯度下降并抑制振荡。开创性的工作包括Nesterov的凸优化加速梯度[61]和非凸问题的动量近端梯度[50]等。为了满足机器学习模型大规模优化的需求,支配优化器以随机方式设计。特别是,带动量的随机梯度下降(SGD)和自适应学习率估计方法Adam[45]被广泛用于训练深度神经网络。从经验上讲,用Adam训练transformer的效果优于SGD,[85]揭示了随机梯度中噪声的重尾分布是SGD性能不佳的主要原因,并通过自适应噪声裁剪的视角来理解Adam。默认情况下,AdamW[56]是Adam的一个变体,它将L2正则化和权重衰减解耦,是transformer广泛使用的优化器。关于机器学习中的加速优化方法的更多细节,请参阅[54,8]。
数据选择
令牌掩蔽。标记掩码是自监督预训练任务中的一种主要方法,如掩码语言建模(MLM)[43,9]和掩码图像建模(MIM)[6,32]。标记掩码的精神是随机掩码一些输入标记,并训练模型用可见标记的上下文信息预测缺失的内容,例如词汇表id或像素。由于压缩序列长度以二次方式降低了计算和存储复杂度,跳过处理掩码token为MLM和MIM带来了可观的训练效率增益。对于MLM,[72]提出联合预训练语言生成任务的编码器和解码器,同时删除解码器中的掩码标记,以节省存储和计算成本。对于MIM,代表性工作[32]表明,在视觉中,在编码器之前删除掩码图像块显示出更强的性能,并且比保留掩码标记的总体预训练时间和存储消耗低3倍或更多。在[51]中也发现了类似的现象,对于语言-图像预训练,随机掩码并去除掩码图像块的总体预训练时间比原始片段快3.7倍[66]。 **3 存储效率 **
除了计算负担之外,大型Transformer模型的模型规模越来越大,例如从BERT [43] 345M参数模型到1.75万亿参数的GPT-3,这是训练的一个关键瓶颈,因为它们不适合单个设备的存储。我们首先分析了现有模型训练框架的内存消耗,它被1)模型状态所占用,包括优化器状态(例如Adam中的动量和方差)、梯度和参数;2)激活(我们忽略了临时缓冲区和空闲碎片存储,因为它们相对较小)。我们在表1中总结了记忆有效的训练方法。下面,我们将讨论优化存储使用的主要解决方案。

4 硬件算法设计
除了计算和存储负担外,设计高效的硬件加速器可以加快DNN的训练和推理。具体来说,与中央处理器(CPU)相比,图形处理器(GPU)由于高度的并行性,在执行矩阵乘法时更加强大。对于专注于特定计算任务的应用,专用集成电路(AISCs)具有低功耗、高训练/推理速度的优势。例如,谷歌设计的张量处理单元(TPU)比当代cpu和gpu[41]的每瓦性能高30 ~ 80倍。然而,ASIC不容易重新编程或适应新任务。相比之下,现场可编程门阵列(FGPA)可以根据需要重新编程以执行不同的功能,也可以在最终设计之前作为asic的原型。为了进一步优化DNNs,特别是Transformer的训练效率,硬件-算法协同设计在设计算法时考虑了硬件的约束和能力。
